 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Off-the-Shelf Models: A Lightweight and Accessible Machine Learning Pipeline for Ecologists Working with Image Data
Jan 22, 2026We introduce a lightweight experimentation pipeline designed to lower the barrier for applying machine learning (ML) methods for classifying images in ecological research. We enable ecologists to experiment with ML models independently, thus they can move beyond off-the-shelf models and generate insights tailored to local datasets and specific classification tasks and target variables. Our tool combines a simple command-line interface for preprocessing, training, and evaluation with a graphical interface for annotation, error analysis, and model comparison. This design enables ecologists to build and iterate on compact, task-specific classifiers without requiring advanced ML expertise. As a proof of concept, we apply the pipeline to classify red deer (Cervus elaphus) by age and sex from 3392 camera trap images collected in the Veldenstein Forest, Germany. Using 4352 cropped images containing individual deer labeled by experts, we trained and evaluated multiple backbone architectures with a wide variety of parameters and data augmentation strategies. Our best-performing models achieved 90.77% accuracy for age classification and 96.15% for sex classification. These results demonstrate that reliable demographic classification is feasible even with limited data to answer narrow, well-defined ecological problems. More broadly, the framework provides ecologists with an accessible tool for developing ML models tailored to specific research questions, paving the way for broader adoption of ML in wildlife monitoring and demographic analysis.
Invariance Pair-Guided Learning: Enhancing Robustness in Neural Networks
Feb 26, 2025



Out-of-distribution generalization of machine learning models remains challenging since the models are inherently bound to the training data distribution. This especially manifests, when the learned models rely on spurious correlations. Most of the existing approaches apply data manipulation, representation learning, or learning strategies to achieve generalizable models. Unfortunately, these approaches usually require multiple training domains, group labels, specialized augmentation, or pre-processing to reach generalizable models. We propose a novel approach that addresses these limitations by providing a technique to guide the neural network through the training phase. We first establish input pairs, representing the spurious attribute and describing the invariance, a characteristic that should not affect the outcome of the model. Based on these pairs, we form a corrective gradient complementing the traditional gradient descent approach. We further make this correction mechanism adaptive based on a predefined invariance condition. Experiments on ColoredMNIST, Waterbird-100, and CelebA datasets demonstrate the effectiveness of our approach and the robustness to group shifts.
Trust Me, I Know the Way: Predictive Uncertainty in the Presence of Shortcut Learning
Feb 13, 2025



The correct way to quantify predictive uncertainty in neural networks remains a topic of active discussion. In particular, it is unclear whether the state-of-the art entropy decomposition leads to a meaningful representation of model, or epistemic, uncertainty (EU) in the light of a debate that pits ignorance against disagreement perspectives. We aim to reconcile the conflicting viewpoints by arguing that both are valid but arise from different learning situations. Notably, we show that the presence of shortcuts is decisive for EU manifesting as disagreement.
Privilege Scores
Feb 03, 2025



Bias-transforming methods of fairness-aware machine learning aim to correct a non-neutral status quo with respect to a protected attribute (PA). Current methods, however, lack an explicit formulation of what drives non-neutrality. We introduce privilege scores (PS) to measure PA-related privilege by comparing the model predictions in the real world with those in a fair world in which the influence of the PA is removed. At the individual level, PS can identify individuals who qualify for affirmative action; at the global level, PS can inform bias-transforming policies. After presenting estimation methods for PS, we propose privilege score contributions (PSCs), an interpretation method that attributes the origin of privilege to mediating features and direct effects. We provide confidence intervals for both PS and PSCs. Experiments on simulated and real-world data demonstrate the broad applicability of our methods and provide novel insights into gender and racial privilege in mortgage and college admissions applications.
Overcoming Fairness Trade-offs via Pre-processing: A Causal Perspective
Jan 24, 2025Training machine learning models for fair decisions faces two key challenges: The \emph{fairness-accuracy trade-off} results from enforcing fairness which weakens its predictive performance in contrast to an unconstrained model. The incompatibility of different fairness metrics poses another trade-off -- also known as the \emph{impossibility theorem}. Recent work identifies the bias within the observed data as a possible root cause and shows that fairness and predictive performance are in fact in accord when predictive performance is measured on unbiased data. We offer a causal explanation for these findings using the framework of the FiND (fictitious and normatively desired) world, a "fair" world, where protected attributes have no causal effects on the target variable. We show theoretically that (i) classical fairness metrics deemed to be incompatible are naturally satisfied in the FiND world, while (ii) fairness aligns with high predictive performance. We extend our analysis by suggesting how one can benefit from these theoretical insights in practice, using causal pre-processing methods that approximate the FiND world. Additionally, we propose a method for evaluating the approximation of the FiND world via pre-processing in practical use cases where we do not have access to the FiND world. In simulations and empirical studies, we demonstrate that these pre-processing methods are successful in approximating the FiND world and resolve both trade-offs. Our results provide actionable solutions for practitioners to achieve fairness and high predictive performance simultaneously.
mlr3summary: Concise and interpretable summaries for machine learning models
Apr 25, 2024
This work introduces a novel R package for concise, informative summaries of machine learning models. We take inspiration from the summary function for (generalized) linear models in R, but extend it in several directions: First, our summary function is model-agnostic and provides a unified summary output also for non-parametric machine learning models; Second, the summary output is more extensive and customizable -- it comprises information on the dataset, model performance, model complexity, model's estimated feature importances, feature effects, and fairness metrics; Third, models are evaluated based on resampling strategies for unbiased estimates of model performances, feature importances, etc. Overall, the clear, structured output should help to enhance and expedite the model selection process, making it a helpful tool for practitioners and researchers alike.
A Guide to Feature Importance Methods for Scientific Inference
Apr 19, 2024While machine learning (ML) models are increasingly used due to their high predictive power, their use in understanding the data-generating process (DGP) is limited. Understanding the DGP requires insights into feature-target associations, which many ML models cannot directly provide, due to their opaque internal mechanisms. Feature importance (FI) methods provide useful insights into the DGP under certain conditions. Since the results of different FI methods have different interpretations, selecting the correct FI method for a concrete use case is crucial and still requires expert knowledge. This paper serves as a comprehensive guide to help understand the different interpretations of FI methods. Through an extensive review of FI methods and providing new proofs regarding their interpretation, we facilitate a thorough understanding of these methods and formulate concrete recommendations for scientific inference. We conclude by discussing options for FI uncertainty estimation and point to directions for future research aiming at full statistical inference from black-box ML models.
Connecting the Dots: Is Mode-Connectedness the Key to Feasible Sample-Based Inference in Bayesian Neural Networks?
Feb 02, 2024A major challenge in sample-based inference (SBI) for Bayesian neural networks is the size and structure of the networks' parameter space. Our work shows that successful SBI is possible by embracing the characteristic relationship between weight and function space, uncovering a systematic link between overparameterization and the difficulty of the sampling problem. Through extensive experiments, we establish practical guidelines for sampling and convergence diagnosis. As a result, we present a Bayesian deep ensemble approach as an effective solution with competitive performance and uncertainty quantification.
Evaluating machine learning models in non-standard settings: An overview and new findings
Oct 23, 2023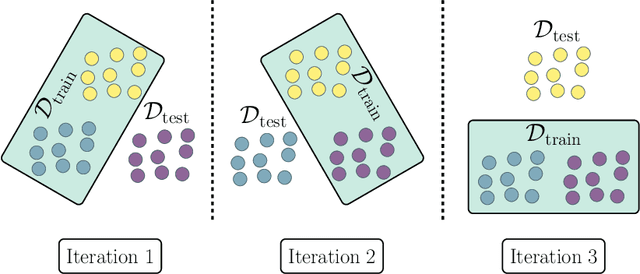

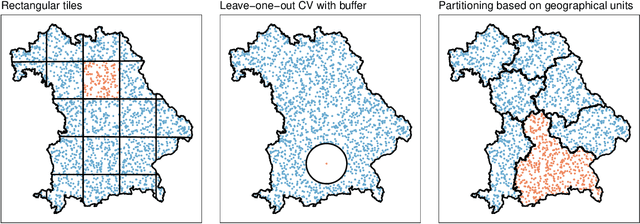

Estimating the generalization error (GE) of machine learning models is fundamental, with resampling methods being the most common approach. However, in non-standard settings, particularly those where observations are not independently and identically distributed, resampling using simple random data divisions may lead to biased GE estimates. This paper strives to present well-grounded guidelines for GE estimation in various such non-standard settings: clustered data, spatial data, unequal sampling probabilities, concept drift, and hierarchically structured outcomes. Our overview combines well-established methodologies with other existing methods that, to our knowledge, have not been frequently considered in these particular settings. A unifying principle among these techniques is that the test data used in each iteration of the resampling procedure should reflect the new observations to which the model will be applied, while the training data should be representative of the entire data set used to obtain the final model. Beyond providing an overview, we address literature gaps by conducting simulation studies. These studies assess the necessity of using GE-estimation methods tailored to the respective setting. Our findings corroborate the concern that standard resampling methods often yield biased GE estimates in non-standard settings, underscoring the importance of tailored GE estimation.
Causal Fair Machine Learning via Rank-Preserving Interventional Distributions
Jul 24, 2023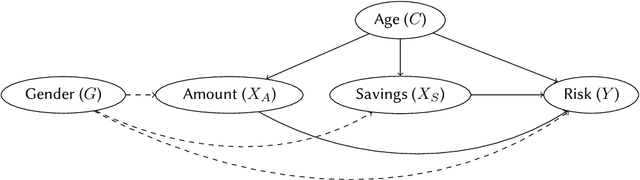

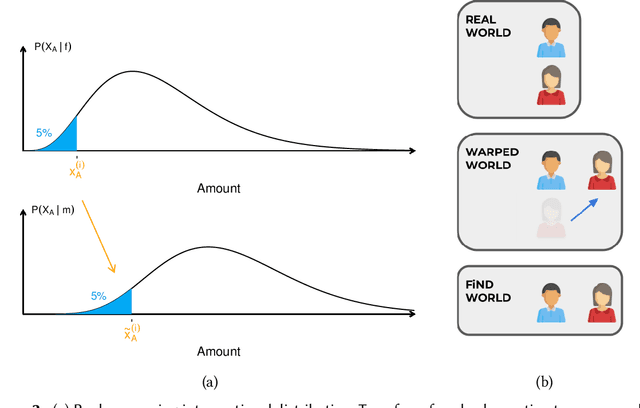
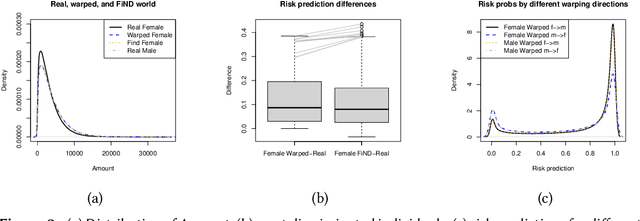
A decision can be defined as fair if equal individuals are treated equally and unequals unequally. Adopting this definition, the task of designing machine learning models that mitigate unfairness in automated decision-making systems must include causal thinking when introducing protected attributes. Following a recent proposal, we define individuals as being normatively equal if they are equal in a fictitious, normatively desired (FiND) world, where the protected attribute has no (direct or indirect) causal effect on the target. We propose rank-preserving interventional distributions to define an estimand of this FiND world and a warping method for estimation. Evaluation criteria for both the method and resulting model are presented and validated through simulations and empirical data. With this, we show that our warping approach effectively identifies the most discriminated individuals and mitigates unfairness.