 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3mbo: Bayesian Optimization in R
Mar 31, 2026We present mlr3mbo, a comprehensive and modular toolbox for Bayesian optimization in R. mlr3mbo supports single- and multi-objective optimization, multi-point proposals, batch and asynchronous parallelization, input and output transformations, and robust error handling. While it can be used for many standard Bayesian optimization variants in applied settings, researchers can also construct custom BO algorithms from its flexible building blocks. In addition to an introduction to the software, its design principles, and its building blocks, the paper presents two extensive empirical evaluations of the software on the surrogate-based benchmark suite YAHPO Gym. To identify robust default configurations for both numeric and mixed-hierarchical optimization regimes, and to gain further insights into the respective impacts of individual settings, we run a coordinate descent search over the mlr3mbo configuration space and analyze its results. Furthermore, we demonstrate that mlr3mbo achieves state-of-the-art performance by benchmarking it against a wide range of optimizers, including HEBO, SMAC3, Ax, and Optuna.
mlr3summary: Concise and interpretable summaries for machine learning models
Apr 25, 2024
This work introduces a novel R package for concise, informative summaries of machine learning models. We take inspiration from the summary function for (generalized) linear models in R, but extend it in several directions: First, our summary function is model-agnostic and provides a unified summary output also for non-parametric machine learning models; Second, the summary output is more extensive and customizable -- it comprises information on the dataset, model performance, model complexity, model's estimated feature importances, feature effects, and fairness metrics; Third, models are evaluated based on resampling strategies for unbiased estimates of model performances, feature importances, etc. Overall, the clear, structured output should help to enhance and expedite the model selection process, making it a helpful tool for practitioners and researchers alike.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
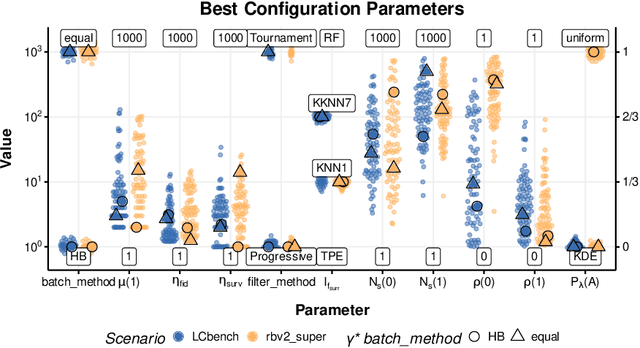

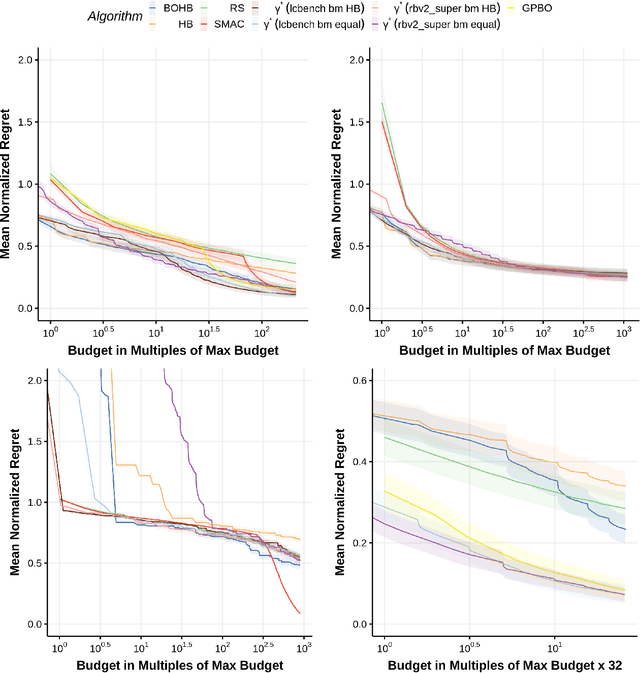
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
Mlr3spatiotempcv: Spatiotemporal resampling methods for machine learning in R
Oct 25, 2021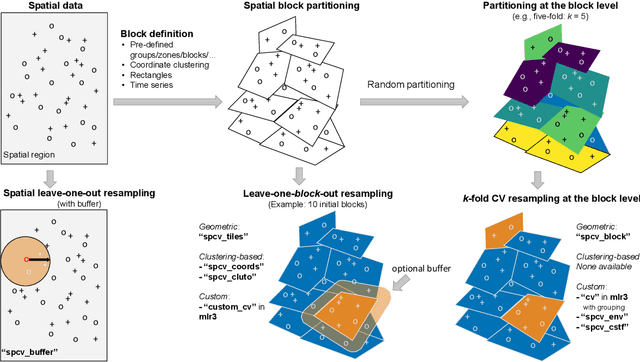
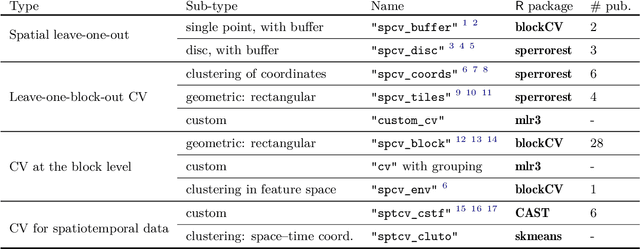
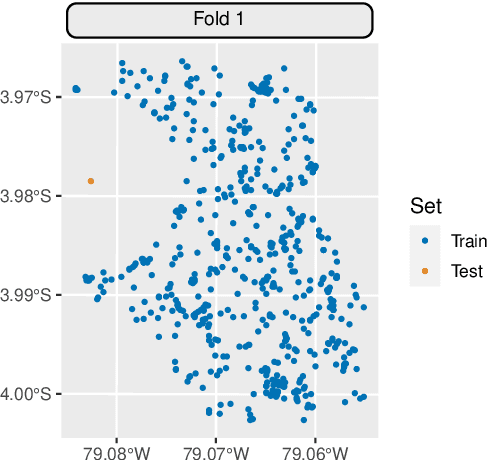
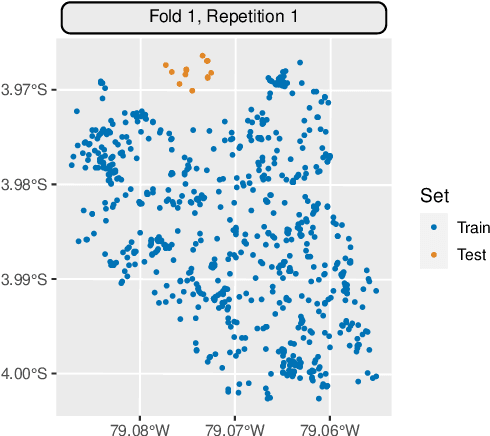
Spatial and spatiotemporal machine-learning models require a suitable framework for their model assessment, model selection, and hyperparameter tuning, in order to avoid error estimation bias and over-fitting. This contribution reviews the state-of-the-art in spatial and spatiotemporal CV, and introduces the \proglang{R} package mlr3spatiotempcv as an extension package of the machine-learning framework \textbf{mlr3}. Currently various \proglang{R} packages implementing different spatiotemporal partitioning strategies exist: \pkg{blockCV}, \pkg{CAST}, \pkg{kmeans} and \pkg{sperrorest}. The goal of \pkg{mlr3spatiotempcv} is to gather the available spatiotemporal resampling methods in \proglang{R} and make them available to users through a simple and common interface. This is made possible by integrating the package directly into the \pkg{mlr3} machine-learning framework, which already has support for generic non-spatiotemporal resampling methods such as random partitioning. One advantage is the use of a consistent nomenclature in an overarching machine-learning toolkit instead of a varying package-specific syntax, making it easier for users to choose from a variety of spatiotemporal resampling methods. This package avoids giving recommendations which method to use in practice as this decision depends on the predictive task at hand, the autocorrelation within the data, and the spatial structure of the sampling design or geographic objects being studied.
Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges
Jul 14, 2021
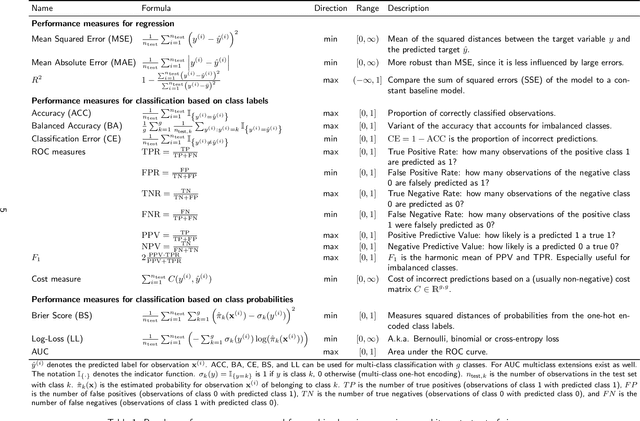
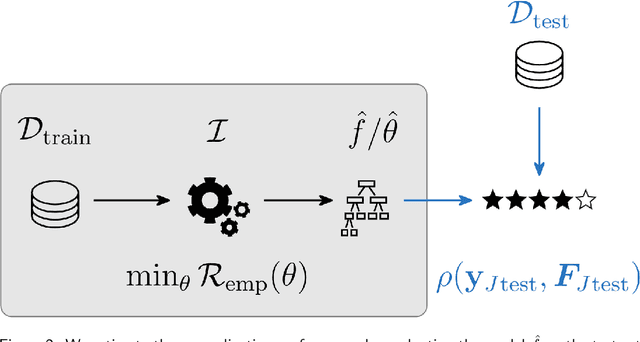
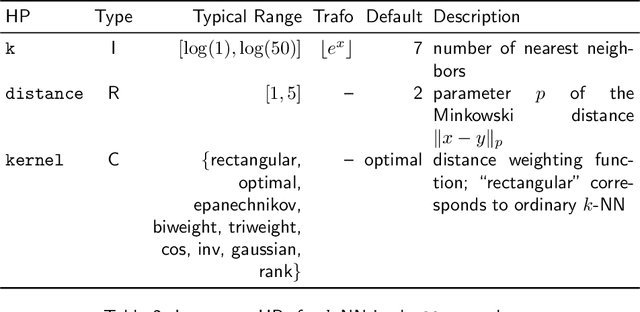
Most machine learning algorithms are configured by one or several hyperparameters that must be carefully chosen and often considerably impact performance. To avoid a time consuming and unreproducible manual trial-and-error process to find well-performing hyperparameter configurations, various automatic hyperparameter optimization (HPO) methods, e.g., based on resampling error estimation for supervised machine learning, can be employed. After introducing HPO from a general perspective, this paper reviews important HPO methods such as grid or random search, evolutionary algorithms, Bayesian optimization, Hyperband and racing. It gives practical recommendations regarding important choices to be made when conducting HPO, including the HPO algorithms themselves, performance evaluation, how to combine HPO with ML pipelines, runtime improvements, and parallelization.