 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3mbo: Bayesian Optimization in R
Mar 31, 2026We present mlr3mbo, a comprehensive and modular toolbox for Bayesian optimization in R. mlr3mbo supports single- and multi-objective optimization, multi-point proposals, batch and asynchronous parallelization, input and output transformations, and robust error handling. While it can be used for many standard Bayesian optimization variants in applied settings, researchers can also construct custom BO algorithms from its flexible building blocks. In addition to an introduction to the software, its design principles, and its building blocks, the paper presents two extensive empirical evaluations of the software on the surrogate-based benchmark suite YAHPO Gym. To identify robust default configurations for both numeric and mixed-hierarchical optimization regimes, and to gain further insights into the respective impacts of individual settings, we run a coordinate descent search over the mlr3mbo configuration space and analyze its results. Furthermore, we demonstrate that mlr3mbo achieves state-of-the-art performance by benchmarking it against a wide range of optimizers, including HEBO, SMAC3, Ax, and Optuna.
LLaMEA-SAGE: Guiding Automated Algorithm Design with Structural Feedback from Explainable AI
Jan 29, 2026Large language models have enabled automated algorithm design (AAD) by generating optimization algorithms directly from natural-language prompts. While evolutionary frameworks such as LLaMEA demonstrate strong exploratory capabilities across the algorithm design space, their search dynamics are entirely driven by fitness feedback, leaving substantial information about the generated code unused. We propose a mechanism for guiding AAD using feedback constructed from graph-theoretic and complexity features extracted from the abstract syntax trees of the generated algorithms, based on a surrogate model learned over an archive of evaluated solutions. Using explainable AI techniques, we identify features that substantially affect performance and translate them into natural-language mutation instructions that steer subsequent LLM-based code generation without restricting expressivity. We propose LLaMEA-SAGE, which integrates this feature-driven guidance into LLaMEA, and evaluate it across several benchmarks. We show that the proposed structured guidance achieves the same performance faster than vanilla LLaMEA in a small controlled experiment. In a larger-scale experiment using the MA-BBOB suite from the GECCO-MA-BBOB competition, our guided approach achieves superior performance compared to state-of-the-art AAD methods. These results demonstrate that signals derived from code can effectively bias LLM-driven algorithm evolution, bridging the gap between code structure and human-understandable performance feedback in automated algorithm design.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025
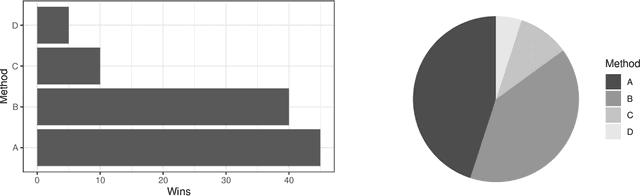
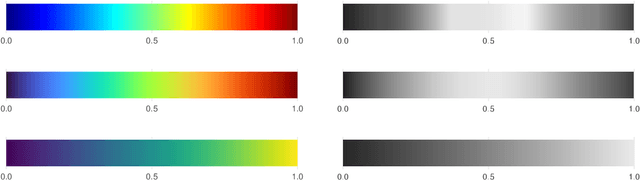
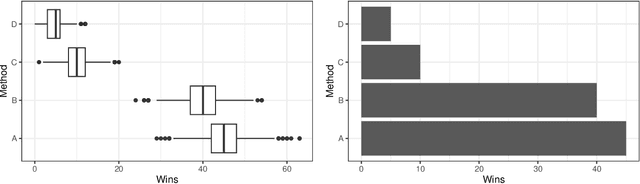
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Code Evolution Graphs: Understanding Large Language Model Driven Design of Algorithms
Mar 20, 2025
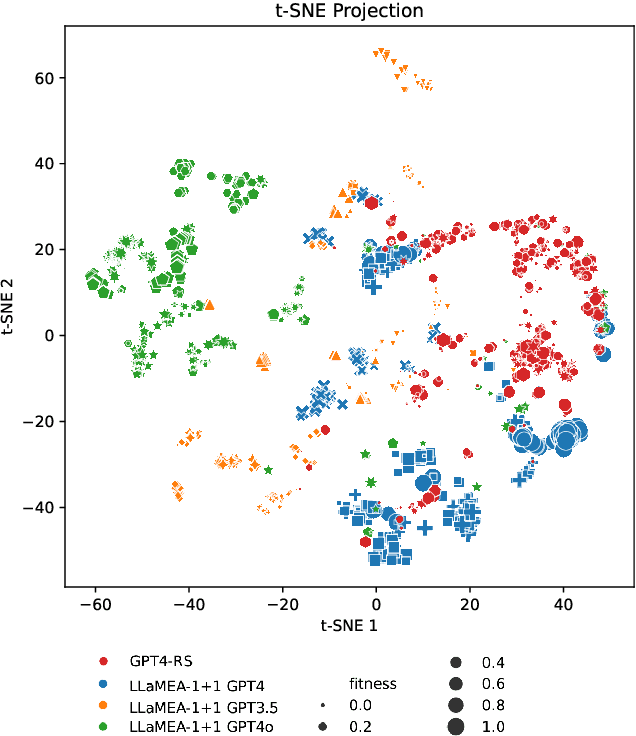
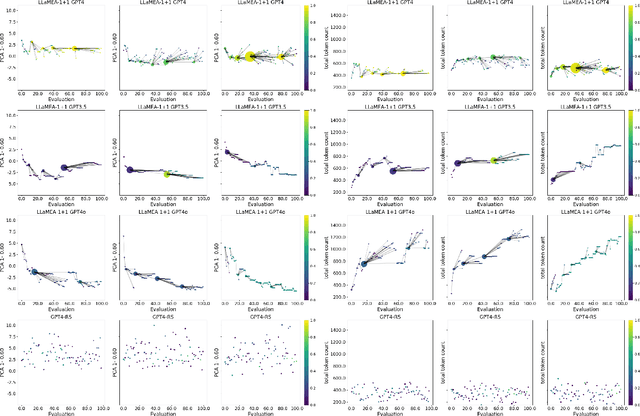

Large Language Models (LLMs) have demonstrated great promise in generating code, especially when used inside an evolutionary computation framework to iteratively optimize the generated algorithms. However, in some cases they fail to generate competitive algorithms or the code optimization stalls, and we are left with no recourse because of a lack of understanding of the generation process and generated codes. We present a novel approach to mitigate this problem by enabling users to analyze the generated codes inside the evolutionary process and how they evolve over repeated prompting of the LLM. We show results for three benchmark problem classes and demonstrate novel insights. In particular, LLMs tend to generate more complex code with repeated prompting, but additional complexity can hurt algorithmic performance in some cases. Different LLMs have different coding ``styles'' and generated code tends to be dissimilar to other LLMs. These two findings suggest that using different LLMs inside the code evolution frameworks might produce higher performing code than using only one LLM.
How explainable are adversarially-robust CNNs?
May 25, 2022
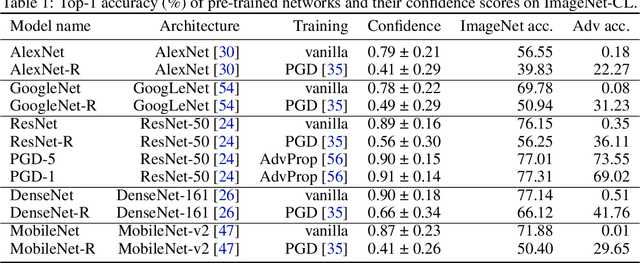
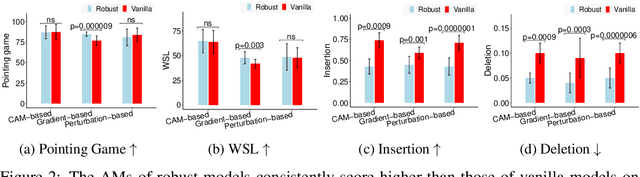

Three important criteria of existing convolutional neural networks (CNNs) are (1) test-set accuracy; (2) out-of-distribution accuracy; and (3) explainability. While these criteria have been studied independently, their relationship is unknown. For example, do CNNs that have a stronger out-of-distribution performance have also stronger explainability? Furthermore, most prior feature-importance studies only evaluate methods on 2-3 common vanilla ImageNet-trained CNNs, leaving it unknown how these methods generalize to CNNs of other architectures and training algorithms. Here, we perform the first, large-scale evaluation of the relations of the three criteria using 9 feature-importance methods and 12 ImageNet-trained CNNs that are of 3 training algorithms and 5 CNN architectures. We find several important insights and recommendations for ML practitioners. First, adversarially robust CNNs have a higher explainability score on gradient-based attribution methods (but not CAM-based or perturbation-based methods). Second, AdvProp models, despite being highly accurate more than both vanilla and robust models alone, are not superior in explainability. Third, among 9 feature attribution methods tested, GradCAM and RISE are consistently the best methods. Fourth, Insertion and Deletion are biased towards vanilla and robust models respectively, due to their strong correlation with the confidence score distributions of a CNN. Fifth, we did not find a single CNN to be the best in all three criteria, which interestingly suggests that CNNs are harder to interpret as they become more accurate.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
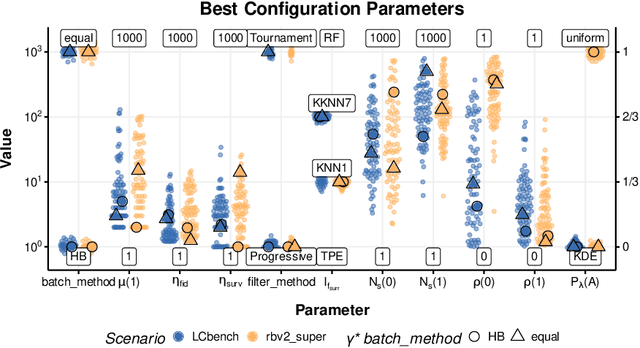

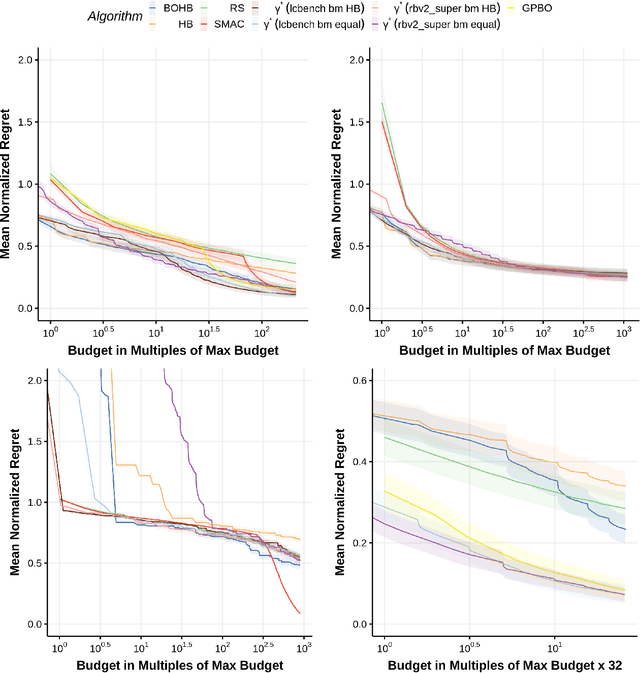
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
Bayesian Optimization in Materials Science: A Survey
Jul 29, 2021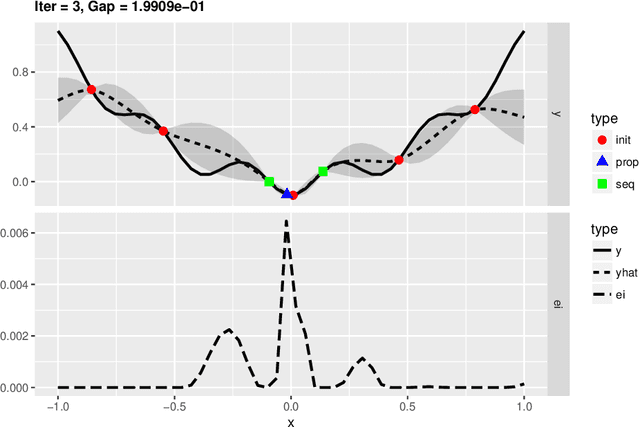
Bayesian optimization is used in many areas of AI for the optimization of black-box processes and has achieved impressive improvements of the state of the art for a lot of applications. It intelligently explores large and complex design spaces while minimizing the number of evaluations of the expensive underlying process to be optimized. Materials science considers the problem of optimizing materials' properties given a large design space that defines how to synthesize or process them, with evaluations requiring expensive experiments or simulations -- a very similar setting. While Bayesian optimization is also a popular approach to tackle such problems, there is almost no overlap between the two communities that are investigating the same concepts. We present a survey of Bayesian optimization approaches in materials science to increase cross-fertilization and avoid duplication of work. We highlight common challenges and opportunities for joint research efforts.
Modeling and Optimizing Laser-Induced Graphene
Jul 29, 2021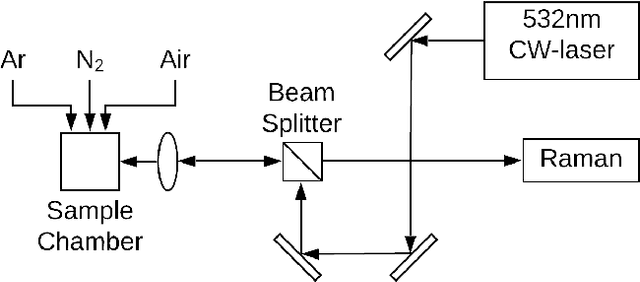
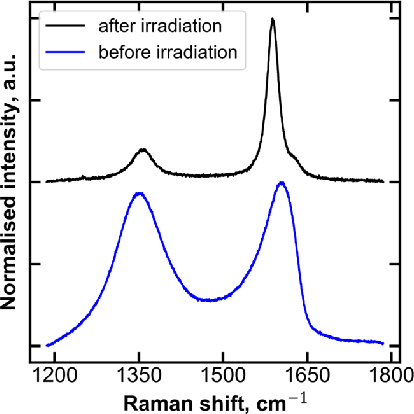
A lot of technological advances depend on next-generation materials, such as graphene, which enables a raft of new applications, for example better electronics. Manufacturing such materials is often difficult; in particular, producing graphene at scale is an open problem. We provide a series of datasets that describe the optimization of the production of laser-induced graphene, an established manufacturing method that has shown great promise. We pose three challenges based on the datasets we provide -- modeling the behavior of laser-induced graphene production with respect to parameters of the production process, transferring models and knowledge between different precursor materials, and optimizing the outcome of the transformation over the space of possible production parameters. We present illustrative results, along with the code used to generate them, as a starting point for interested users. The data we provide represents an important real-world application of machine learning; to the best of our knowledge, no similar datasets are available.
FlexiBO: Cost-Aware Multi-Objective Optimization of Deep Neural Networks
Jan 18, 2020
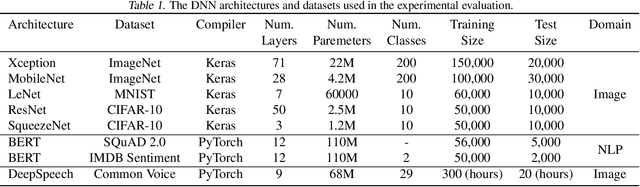
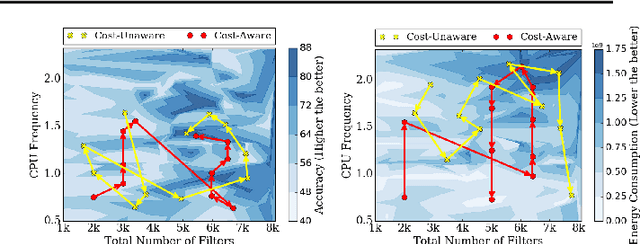
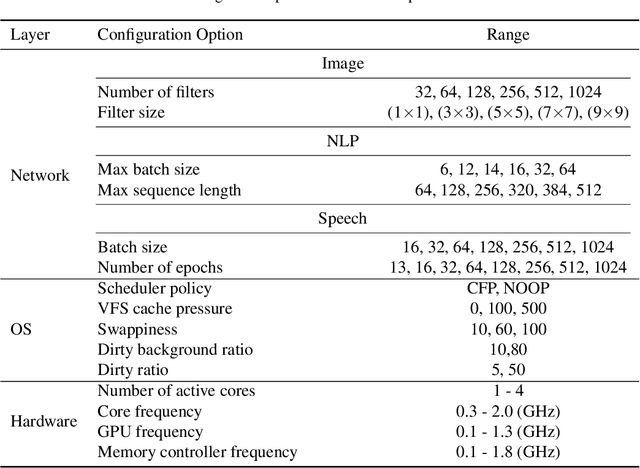
One of the key challenges in designing machine learning systems is to determine the right balance amongst several objectives, which also oftentimes are incommensurable and conflicting. For example, when designing deep neural networks (DNNs), one often has to trade-off between multiple objectives, such as accuracy, energy consumption, and inference time. Typically, there is no single configuration that performs equally well for all objectives. Consequently, one is interested in identifying Pareto-optimal designs. Although different multi-objective optimization algorithms have been developed to identify Pareto-optimal configurations, state-of-the-art multi-objective optimization methods do not consider the different evaluation costs attending the objectives under consideration. This is particularly important for optimizing DNNs: the cost arising on account of assessing the accuracy of DNNs is orders of magnitude higher than that of measuring the energy consumption of pre-trained DNNs. We propose FlexiBO, a flexible Bayesian optimization method, to address this issue. We formulate a new acquisition function based on the improvement of the Pareto hyper-volume weighted by the measurement cost of each objective. Our acquisition function selects the next sample and objective that provides maximum information gain per unit of cost. We evaluated FlexiBO on 7 state-of-the-art DNNs for object detection, natural language processing, and speech recognition. Our results indicate that, when compared to other state-of-the-art methods across the 7 architectures we tested, the Pareto front obtained using FlexiBO has, on average, a 28.44% higher contribution to the true Pareto front and achieves 25.64% better diversity.
Transfer Learning for Performance Modeling of Deep Neural Network Systems
Apr 04, 2019
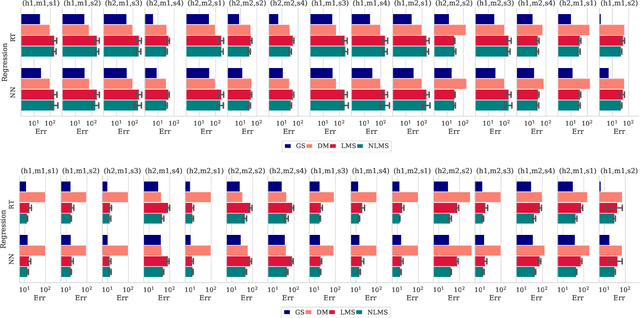
Modern deep neural network (DNN) systems are highly configurable with large a number of options that significantly affect their non-functional behavior, for example inference time and energy consumption. Performance models allow to understand and predict the effects of such configuration options on system behavior, but are costly to build because of large configuration spaces. Performance models from one environment cannot be transferred directly to another; usually models are rebuilt from scratch for different environments, for example different hardware. Recently, transfer learning methods have been applied to reuse knowledge from performance models trained in one environment in another. In this paper, we perform an empirical study to understand the effectiveness of different transfer learning strategies for building performance models of DNN systems. Our results show that transferring information on the most influential configuration options and their interactions is an effective way of reducing the cost to build performance models in new environments.