 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything, Everywhere All in One Evaluation: Using Multiverse Analysis to Evaluate the Influence of Model Design Decisions on Algorithmic Fairness
Aug 31, 2023A vast number of systems across the world use algorithmic decision making (ADM) to (partially) automate decisions that have previously been made by humans. When designed well, these systems promise more objective decisions while saving large amounts of resources and freeing up human time. However, when ADM systems are not designed well, they can lead to unfair decisions which discriminate against societal groups. The downstream effects of ADMs critically depend on the decisions made during the systems' design and implementation, as biases in data can be mitigated or reinforced along the modeling pipeline. Many of these design decisions are made implicitly, without knowing exactly how they will influence the final system. It is therefore important to make explicit the decisions made during the design of ADM systems and understand how these decisions affect the fairness of the resulting system. To study this issue, we draw on insights from the field of psychology and introduce the method of multiverse analysis for algorithmic fairness. In our proposed method, we turn implicit design decisions into explicit ones and demonstrate their fairness implications. By combining decisions, we create a grid of all possible "universes" of decision combinations. For each of these universes, we compute metrics of fairness and performance. Using the resulting dataset, one can see how and which decisions impact fairness. We demonstrate how multiverse analyses can be used to better understand variability and robustness of algorithmic fairness using an exemplary case study of predicting public health coverage of vulnerable populations for potential interventions. Our results illustrate how decisions during the design of a machine learning system can have surprising effects on its fairness and how to detect these effects using multiverse analysis.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Mind the Gap: Measuring Generalization Performance Across Multiple Objectives
Dec 08, 2022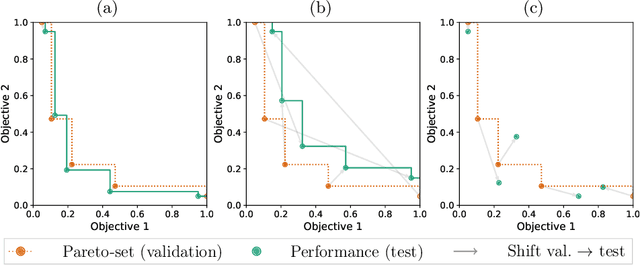
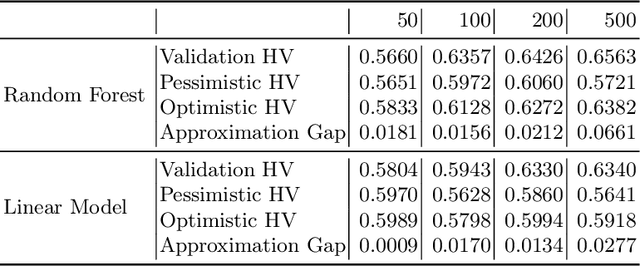
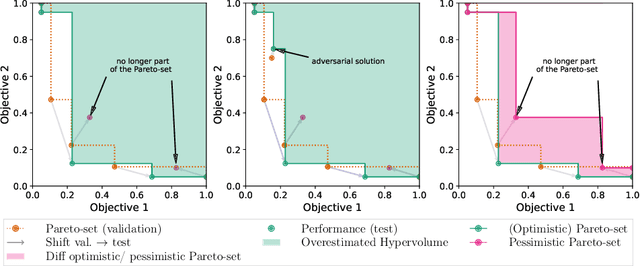
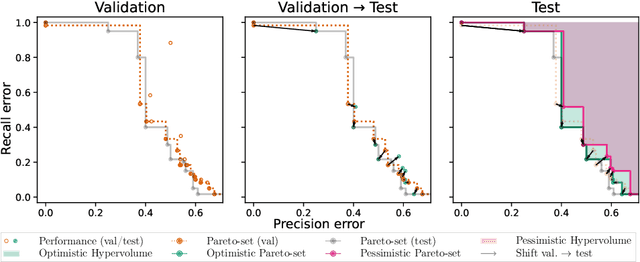
Modern machine learning models are often constructed taking into account multiple objectives, e.g., to minimize inference time while also maximizing accuracy. Multi-objective hyperparameter optimization (MHPO) algorithms return such candidate models and the approximation of the Pareto front is used to assess their performance. However, when estimating generalization performance of an approximation of a Pareto front found on a validation set by computing the performance of the individual models on the test set, models might no longer be Pareto-optimal. This makes it unclear how to measure performance. To resolve this, we provide a novel evaluation protocol that allows measuring the generalization performance of MHPO methods and to study its capabilities for comparing two optimization experiments.
Tackling Neural Architecture Search With Quality Diversity Optimization
Jul 30, 2022

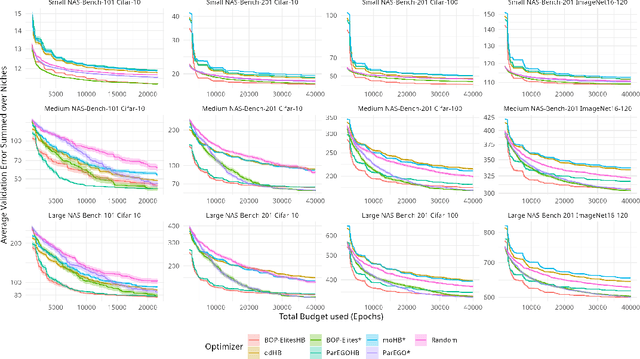

Neural architecture search (NAS) has been studied extensively and has grown to become a research field with substantial impact. While classical single-objective NAS searches for the architecture with the best performance, multi-objective NAS considers multiple objectives that should be optimized simultaneously, e.g., minimizing resource usage along the validation error. Although considerable progress has been made in the field of multi-objective NAS, we argue that there is some discrepancy between the actual optimization problem of practical interest and the optimization problem that multi-objective NAS tries to solve. We resolve this discrepancy by formulating the multi-objective NAS problem as a quality diversity optimization (QDO) problem and introduce three quality diversity NAS optimizers (two of them belonging to the group of multifidelity optimizers), which search for high-performing yet diverse architectures that are optimal for application-specific niches, e.g., hardware constraints. By comparing these optimizers to their multi-objective counterparts, we demonstrate that quality diversity NAS in general outperforms multi-objective NAS with respect to quality of solutions and efficiency. We further show how applications and future NAS research can thrive on QDO.
A geometric framework for outlier detection in high-dimensional data
Jul 01, 2022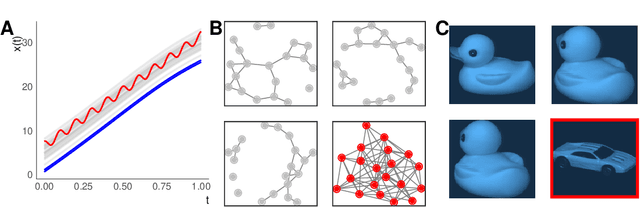

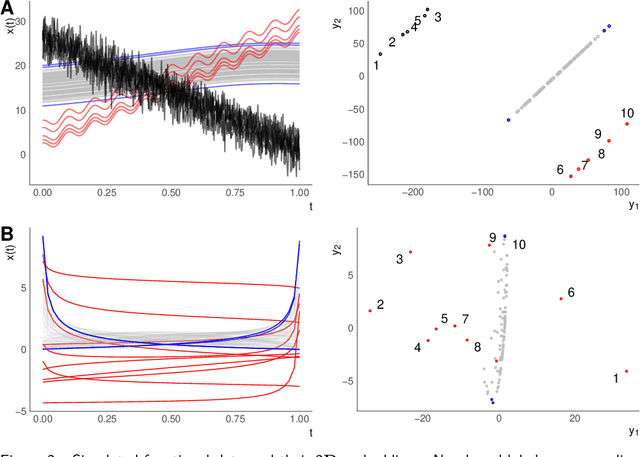
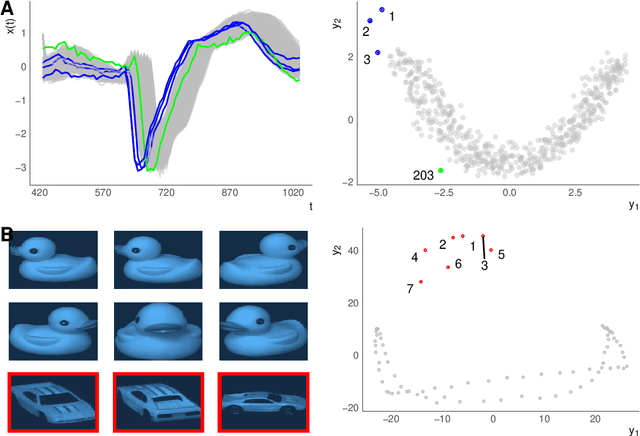
Outlier or anomaly detection is an important task in data analysis. We discuss the problem from a geometrical perspective and provide a framework that exploits the metric structure of a data set. Our approach rests on the manifold assumption, i.e., that the observed, nominally high-dimensional data lie on a much lower dimensional manifold and that this intrinsic structure can be inferred with manifold learning methods. We show that exploiting this structure significantly improves the detection of outlying observations in high-dimensional data. We also suggest a novel, mathematically precise, and widely applicable distinction between distributional and structural outliers based on the geometry and topology of the data manifold that clarifies conceptual ambiguities prevalent throughout the literature. Our experiments focus on functional data as one class of structured high-dimensional data, but the framework we propose is completely general and we include image and graph data applications. Our results show that the outlier structure of high-dimensional and non-tabular data can be detected and visualized using manifold learning methods and quantified using standard outlier scoring methods applied to the manifold embedding vectors.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022

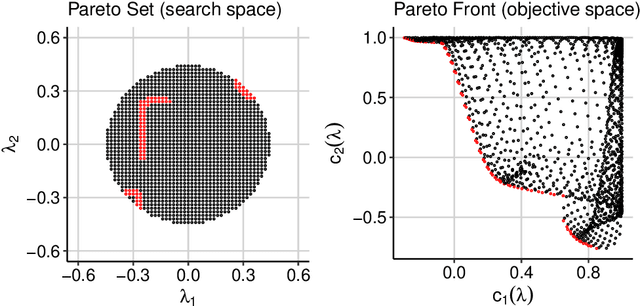
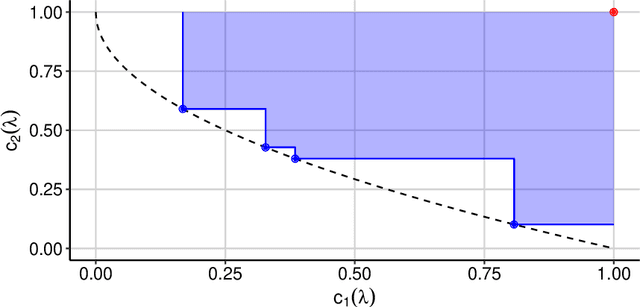
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Flexible Group Fairness Metrics for Survival Analysis
May 26, 2022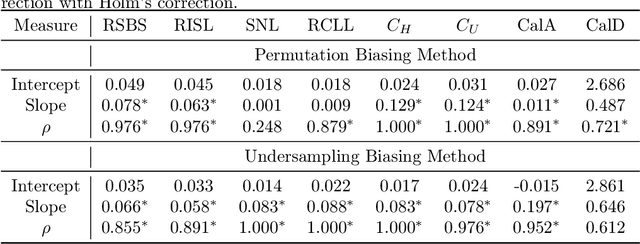
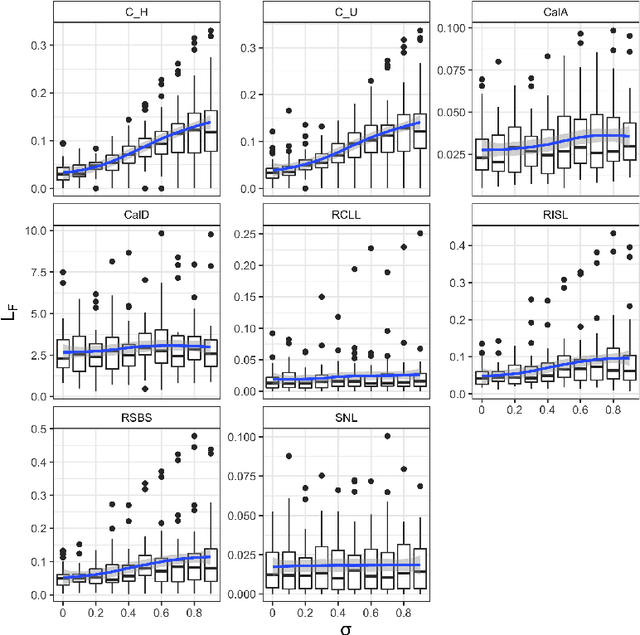
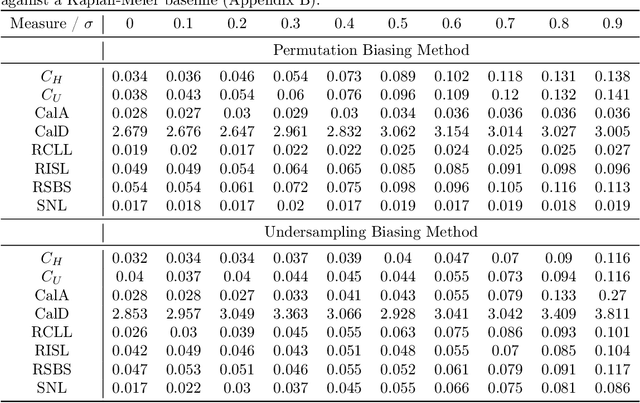
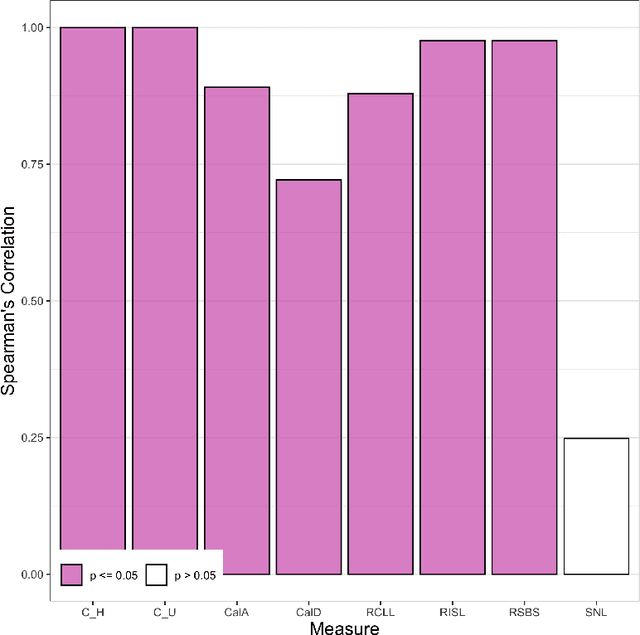
Algorithmic fairness is an increasingly important field concerned with detecting and mitigating biases in machine learning models. There has been a wealth of literature for algorithmic fairness in regression and classification however there has been little exploration of the field for survival analysis. Survival analysis is the prediction task in which one attempts to predict the probability of an event occurring over time. Survival predictions are particularly important in sensitive settings such as when utilising machine learning for diagnosis and prognosis of patients. In this paper we explore how to utilise existing survival metrics to measure bias with group fairness metrics. We explore this in an empirical experiment with 29 survival datasets and 8 measures. We find that measures of discrimination are able to capture bias well whereas there is less clarity with measures of calibration and scoring rules. We suggest further areas for research including prediction-based fairness metrics for distribution predictions.
A Collection of Quality Diversity Optimization Problems Derived from Hyperparameter Optimization of Machine Learning Models
Apr 28, 2022



The goal of Quality Diversity Optimization is to generate a collection of diverse yet high-performing solutions to a given problem at hand. Typical benchmark problems are, for example, finding a repertoire of robot arm configurations or a collection of game playing strategies. In this paper, we propose a set of Quality Diversity Optimization problems that tackle hyperparameter optimization of machine learning models - a so far underexplored application of Quality Diversity Optimization. Our benchmark problems involve novel feature functions, such as interpretability or resource usage of models. To allow for fast and efficient benchmarking, we build upon YAHPO Gym, a recently proposed open source benchmarking suite for hyperparameter optimization that makes use of high performing surrogate models and returns these surrogate model predictions instead of evaluating the true expensive black box function. We present results of an initial experimental study comparing different Quality Diversity optimizers on our benchmark problems. Furthermore, we discuss future directions and challenges of Quality Diversity Optimization in the context of hyperparameter optimization.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
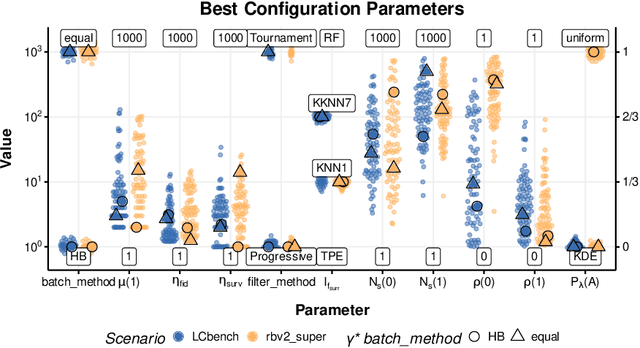

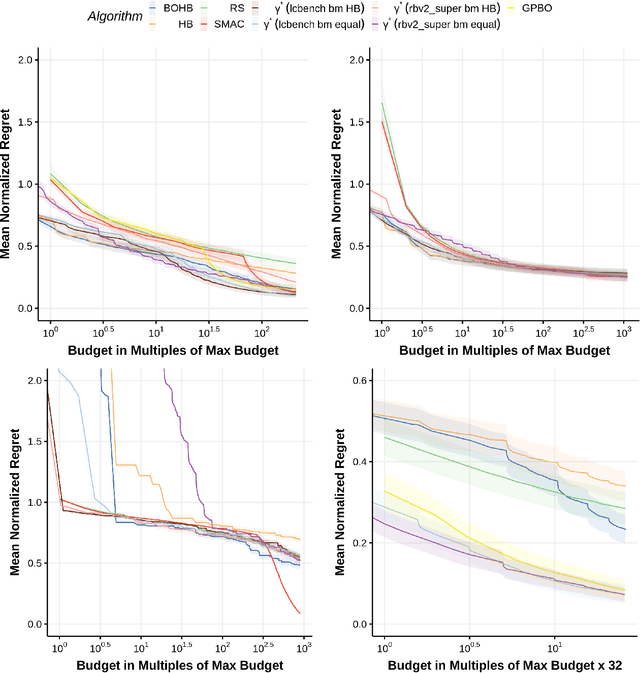
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
YAHPO Gym -- Design Criteria and a new Multifidelity Benchmark for Hyperparameter Optimization
Sep 08, 2021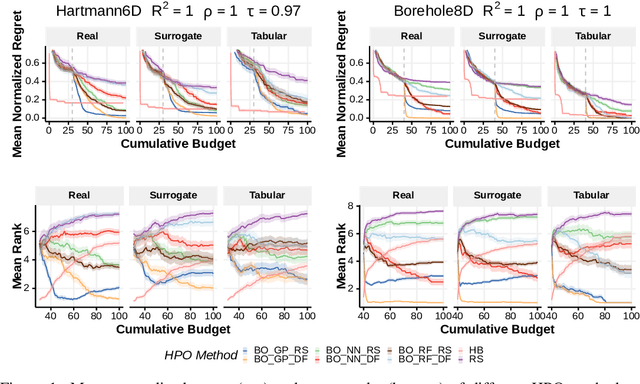

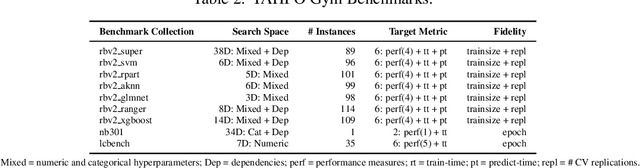
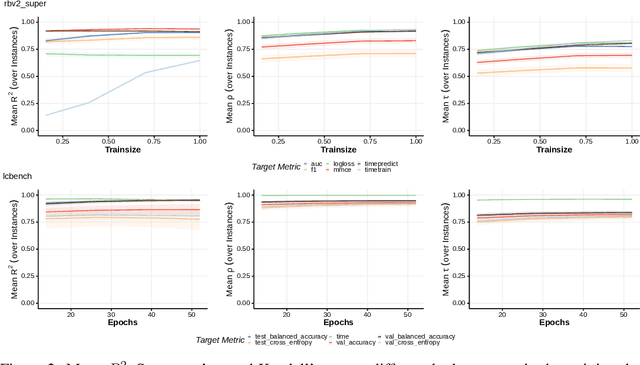
When developing and analyzing new hyperparameter optimization (HPO) methods, it is vital to empirically evaluate and compare them on well-curated benchmark suites. In this work, we list desirable properties and requirements for such benchmarks and propose a new set of challenging and relevant multifidelity HPO benchmark problems motivated by these requirements. For this, we revisit the concept of surrogate-based benchmarks and empirically compare them to more widely-used tabular benchmarks, showing that the latter ones may induce bias in performance estimation and ranking of HPO methods. We present a new surrogate-based benchmark suite for multifidelity HPO methods consisting of 9 benchmark collections that constitute over 700 multifidelity HPO problems in total. All our benchmarks also allow for querying of multiple optimization targets, enabling the benchmarking of multi-objective HPO. We examine and compare our benchmark suite with respect to the defined requirements and show that our benchmarks provide viable additions to existing suites.