 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlawful Proxy Discrimination: A Framework for Challenging Inherently Discriminatory Algorithms
Apr 22, 2024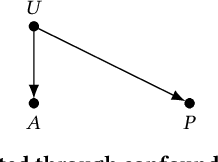



Emerging scholarship suggests that the EU legal concept of direct discrimination - where a person is given different treatment on grounds of a protected characteristic - may apply to various algorithmic decision-making contexts. This has important implications: unlike indirect discrimination, there is generally no 'objective justification' stage in the direct discrimination framework, which means that the deployment of directly discriminatory algorithms will usually be unlawful per se. In this paper, we focus on the most likely candidate for direct discrimination in the algorithmic context, termed inherent direct discrimination, where a proxy is inextricably linked to a protected characteristic. We draw on computer science literature to suggest that, in the algorithmic context, 'treatment on the grounds of' needs to be understood in terms of two steps: proxy capacity and proxy use. Only where both elements can be made out can direct discrimination be said to be `on grounds of' a protected characteristic. We analyse the legal conditions of our proposed proxy capacity and proxy use tests. Based on this analysis, we discuss technical approaches and metrics that could be developed or applied to identify inherent direct discrimination in algorithmic decision-making.
The Neutrality Fallacy: When Algorithmic Fairness Interventions are (Not) Positive Action
Apr 18, 2024Various metrics and interventions have been developed to identify and mitigate unfair outputs of machine learning systems. While individuals and organizations have an obligation to avoid discrimination, the use of fairness-aware machine learning interventions has also been described as amounting to 'algorithmic positive action' under European Union (EU) non-discrimination law. As the Court of Justice of the European Union has been strict when it comes to assessing the lawfulness of positive action, this would impose a significant legal burden on those wishing to implement fair-ml interventions. In this paper, we propose that algorithmic fairness interventions often should be interpreted as a means to prevent discrimination, rather than a measure of positive action. Specifically, we suggest that this category mistake can often be attributed to neutrality fallacies: faulty assumptions regarding the neutrality of fairness-aware algorithmic decision-making. Our findings raise the question of whether a negative obligation to refrain from discrimination is sufficient in the context of algorithmic decision-making. Consequently, we suggest moving away from a duty to 'not do harm' towards a positive obligation to actively 'do no harm' as a more adequate framework for algorithmic decision-making and fair ml-interventions.
Fairlearn: Assessing and Improving Fairness of AI Systems
Mar 29, 2023Fairlearn is an open source project to help practitioners assess and improve fairness of artificial intelligence (AI) systems. The associated Python library, also named fairlearn, supports evaluation of a model's output across affected populations and includes several algorithms for mitigating fairness issues. Grounded in the understanding that fairness is a sociotechnical challenge, the project integrates learning resources that aid practitioners in considering a system's broader societal context.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.
Does the End Justify the Means? On the Moral Justification of Fairness-Aware Machine Learning
Feb 17, 2022

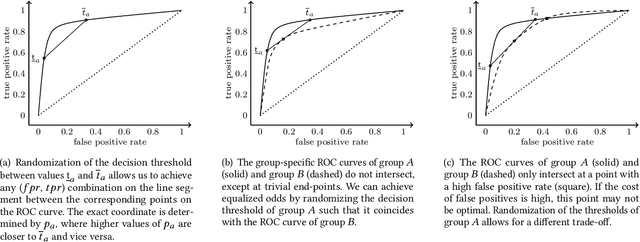
Despite an abundance of fairness-aware machine learning (fair-ml) algorithms, the moral justification of how these algorithms enforce fairness metrics is largely unexplored. The goal of this paper is to elicit the moral implications of a fair-ml algorithm. To this end, we first consider the moral justification of the fairness metrics for which the algorithm optimizes. We present an extension of previous work to arrive at three propositions that can justify the fairness metrics. Different from previous work, our extension highlights that the consequences of predicted outcomes are important for judging fairness. We draw from the extended framework and empirical ethics to identify moral implications of the fair-ml algorithm. We focus on the two optimization strategies inherent to the algorithm: group-specific decision thresholds and randomized decision thresholds. We argue that the justification of the algorithm can differ depending on one's assumptions about the (social) context in which the algorithm is applied - even if the associated fairness metric is the same. Finally, we sketch paths for future work towards a more complete evaluation of fair-ml algorithms, beyond their direct optimization objectives.