 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
The Interaction Layer: An Exploration for Co-Designing User-LLM Interactions in Parental Wellbeing Support Systems
Nov 02, 2024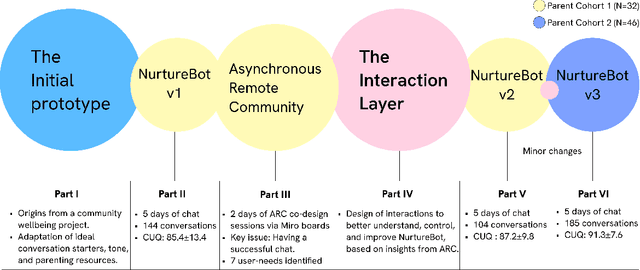



Parenting brings emotional and physical challenges, from balancing work, childcare, and finances to coping with exhaustion and limited personal time. Yet, one in three parents never seek support. AI systems potentially offer stigma-free, accessible, and affordable solutions. Yet, user adoption often fails due to issues with explainability and reliability. To see if these issues could be solved using a co-design approach, we developed and tested NurtureBot, a wellbeing support assistant for new parents. 32 parents co-designed the system through Asynchronous Remote Communities method, identifying the key challenge as achieving a "successful chat". Aspart of co-design, parents role-played as NurturBot, rewriting its dialogues to improve user understanding, control, and outcomes. The refined prototype evaluated by 32 initial and 46 new parents, showed improved user experience and usability, with final CUQ score of 91.3/100, demonstrating successful interaction patterns. Our process revealed useful interaction design lessons for effective AI parenting support.
Unlawful Proxy Discrimination: A Framework for Challenging Inherently Discriminatory Algorithms
Apr 22, 2024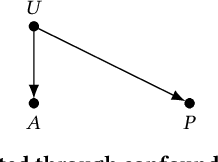



Emerging scholarship suggests that the EU legal concept of direct discrimination - where a person is given different treatment on grounds of a protected characteristic - may apply to various algorithmic decision-making contexts. This has important implications: unlike indirect discrimination, there is generally no 'objective justification' stage in the direct discrimination framework, which means that the deployment of directly discriminatory algorithms will usually be unlawful per se. In this paper, we focus on the most likely candidate for direct discrimination in the algorithmic context, termed inherent direct discrimination, where a proxy is inextricably linked to a protected characteristic. We draw on computer science literature to suggest that, in the algorithmic context, 'treatment on the grounds of' needs to be understood in terms of two steps: proxy capacity and proxy use. Only where both elements can be made out can direct discrimination be said to be `on grounds of' a protected characteristic. We analyse the legal conditions of our proposed proxy capacity and proxy use tests. Based on this analysis, we discuss technical approaches and metrics that could be developed or applied to identify inherent direct discrimination in algorithmic decision-making.
On the Apparent Conflict Between Individual and Group Fairness
Dec 14, 2019

A distinction has been drawn in fair machine learning research between `group' and `individual' fairness measures. Many technical research papers assume that both are important, but conflicting, and propose ways to minimise the trade-offs between these measures. This paper argues that this apparent conflict is based on a misconception. It draws on theoretical discussions from within the fair machine learning research, and from political and legal philosophy, to argue that individual and group fairness are not fundamentally in conflict. First, it outlines accounts of egalitarian fairness which encompass plausible motivations for both group and individual fairness, thereby suggesting that there need be no conflict in principle. Second, it considers the concept of individual justice, from legal philosophy and jurisprudence which seems similar but actually contradicts the notion of individual fairness as proposed in the fair machine learning literature. The conclusion is that the apparent conflict between individual and group fairness is more of an artifact of the blunt application of fairness measures, rather than a matter of conflicting principles. In practice, this conflict may be resolved by a nuanced consideration of the sources of `unfairness' in a particular deployment context, and the carefully justified application of measures to mitigate it.
Algorithms that Remember: Model Inversion Attacks and Data Protection Law
Oct 15, 2018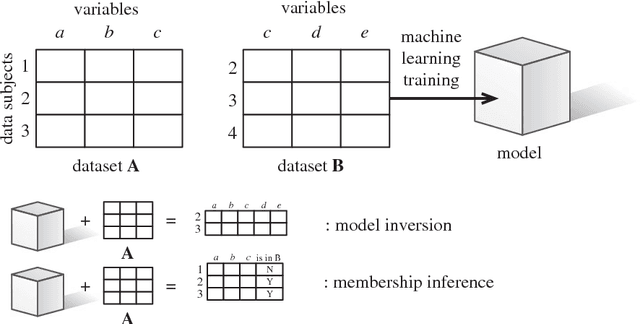
Many individuals are concerned about the governance of machine learning systems and the prevention of algorithmic harms. The EU's recent General Data Protection Regulation (GDPR) has been seen as a core tool for achieving better governance of this area. While the GDPR does apply to the use of models in some limited situations, most of its provisions relate to the governance of personal data, while models have traditionally been seen as intellectual property. We present recent work from the information security literature around `model inversion' and `membership inference' attacks, which indicate that the process of turning training data into machine learned systems is not one-way, and demonstrate how this could lead some models to be legally classified as personal data. Taking this as a probing experiment, we explore the different rights and obligations this would trigger and their utility, and posit future directions for algorithmic governance and regulation.
* 15 pages, 1 figure
Some HCI Priorities for GDPR-Compliant Machine Learning
Mar 16, 2018In this short paper, we consider the roles of HCI in enabling the better governance of consequential machine learning systems using the rights and obligations laid out in the recent 2016 EU General Data Protection Regulation (GDPR)---a law which involves heavy interaction with people and systems. Focussing on those areas that relate to algorithmic systems in society, we propose roles for HCI in legal contexts in relation to fairness, bias and discrimination; data protection by design; data protection impact assessments; transparency and explanations; the mitigation and understanding of automation bias; and the communication of envisaged consequences of processing.
Fairness and Accountability Design Needs for Algorithmic Support in High-Stakes Public Sector Decision-Making
Feb 03, 2018Calls for heightened consideration of fairness and accountability in algorithmically-informed public decisions---like taxation, justice, and child protection---are now commonplace. How might designers support such human values? We interviewed 27 public sector machine learning practitioners across 5 OECD countries regarding challenges understanding and imbuing public values into their work. The results suggest a disconnect between organisational and institutional realities, constraints and needs, and those addressed by current research into usable, transparent and 'discrimination-aware' machine learning---absences likely to undermine practical initiatives unless addressed. We see design opportunities in this disconnect, such as in supporting the tracking of concept drift in secondary data sources, and in building usable transparency tools to identify risks and incorporate domain knowledge, aimed both at managers and at the 'street-level bureaucrats' on the frontlines of public service. We conclude by outlining ethical challenges and future directions for collaboration in these high-stakes applications.
* 14 pages, 0 figures, ACM Conference on Human Factors in Computing Systems (CHI'18), April 21--26, Montreal, Canada
Like trainer, like bot? Inheritance of bias in algorithmic content moderation
Jul 05, 2017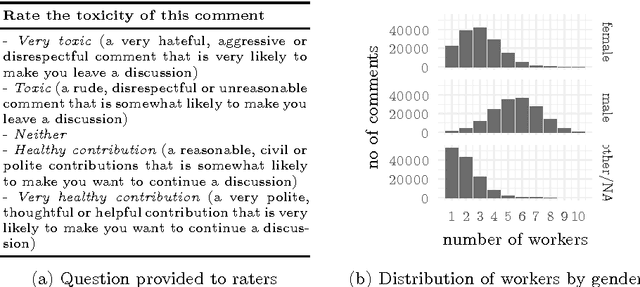
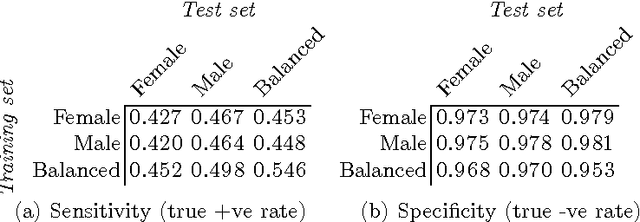
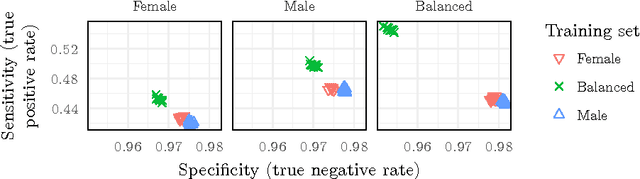
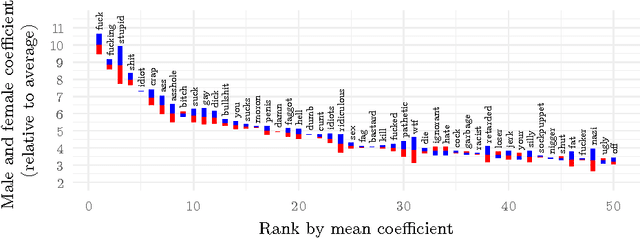
The internet has become a central medium through which `networked publics' express their opinions and engage in debate. Offensive comments and personal attacks can inhibit participation in these spaces. Automated content moderation aims to overcome this problem using machine learning classifiers trained on large corpora of texts manually annotated for offence. While such systems could help encourage more civil debate, they must navigate inherently normatively contestable boundaries, and are subject to the idiosyncratic norms of the human raters who provide the training data. An important objective for platforms implementing such measures might be to ensure that they are not unduly biased towards or against particular norms of offence. This paper provides some exploratory methods by which the normative biases of algorithmic content moderation systems can be measured, by way of a case study using an existing dataset of comments labelled for offence. We train classifiers on comments labelled by different demographic subsets (men and women) to understand how differences in conceptions of offence between these groups might affect the performance of the resulting models on various test sets. We conclude by discussing some of the ethical choices facing the implementers of algorithmic moderation systems, given various desired levels of diversity of viewpoints amongst discussion participants.