 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigor in AI: Doing Rigorous AI Work Requires a Broader, Responsible AI-Informed Conception of Rigor
Jun 17, 2025In AI research and practice, rigor remains largely understood in terms of methodological rigor -- such as whether mathematical, statistical, or computational methods are correctly applied. We argue that this narrow conception of rigor has contributed to the concerns raised by the responsible AI community, including overblown claims about AI capabilities. Our position is that a broader conception of what rigorous AI research and practice should entail is needed. We believe such a conception -- in addition to a more expansive understanding of (1) methodological rigor -- should include aspects related to (2) what background knowledge informs what to work on (epistemic rigor); (3) how disciplinary, community, or personal norms, standards, or beliefs influence the work (normative rigor); (4) how clearly articulated the theoretical constructs under use are (conceptual rigor); (5) what is reported and how (reporting rigor); and (6) how well-supported the inferences from existing evidence are (interpretative rigor). In doing so, we also aim to provide useful language and a framework for much-needed dialogue about the AI community's work by researchers, policymakers, journalists, and other stakeholders.
The Impossibility of Fair LLMs
May 28, 2024The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
Responsible AI Research Needs Impact Statements Too
Nov 20, 2023All types of research, development, and policy work can have unintended, adverse consequences - work in responsible artificial intelligence (RAI), ethical AI, or ethics in AI is no exception.
Unified Browsing Models for Linear and Grid Layouts
Oct 19, 2023Many information access systems operationalize their results in terms of rankings, which are then displayed to users in various ranking layouts such as linear lists or grids. User interaction with a retrieved item is highly dependent on the item's position in the layout, and users do not provide similar attention to every position in ranking (under any layout model). User attention is an important component in the evaluation process of ranking, due to its use in effectiveness metrics that estimate utility as well as fairness metrics that evaluate ranking based on social and ethical concerns. These metrics take user browsing behavior into account in their measurement strategies to estimate the attention the user is likely to provide to each item in ranking. Research on understanding user browsing behavior has proposed several user browsing models, and further observed that user browsing behavior differs with different ranking layouts. However, the underlying concepts of these browsing models are often similar, including varying components and parameter settings. We seek to leverage that similarity to represent multiple browsing models in a generalized, configurable framework which can be further extended to more complex ranking scenarios. In this paper, we describe a probabilistic user browsing model for linear rankings, show how they can be configured to yield models commonly used in current evaluation practice, and generalize this model to also account for browsing behaviors in grid-based layouts. This model provides configurable framework for estimating the attention that results from user browsing activity for a range of IR evaluation and measurement applications in multiple formats, and also identifies parameters that need to be estimated through user studies to provide realistic evaluation beyond ranked lists.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022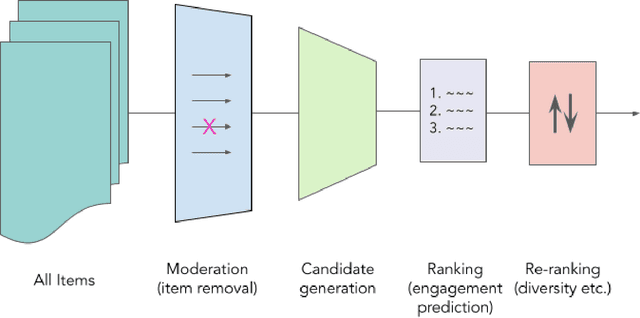
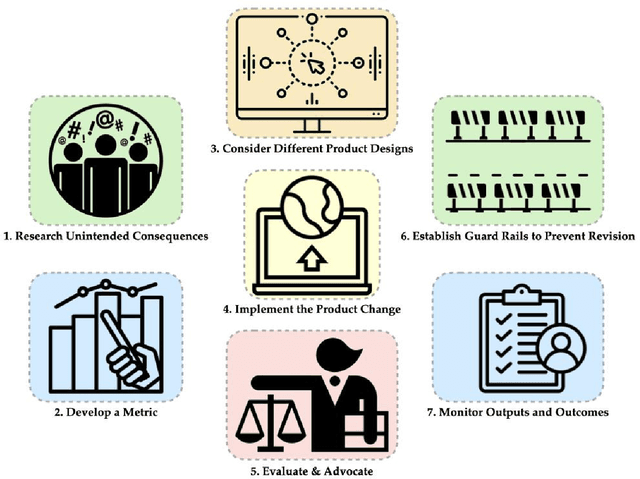
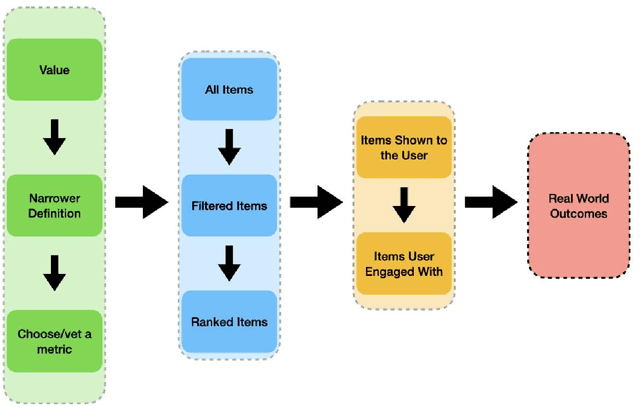

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
Estimation of Fair Ranking Metrics with Incomplete Judgments
Aug 11, 2021
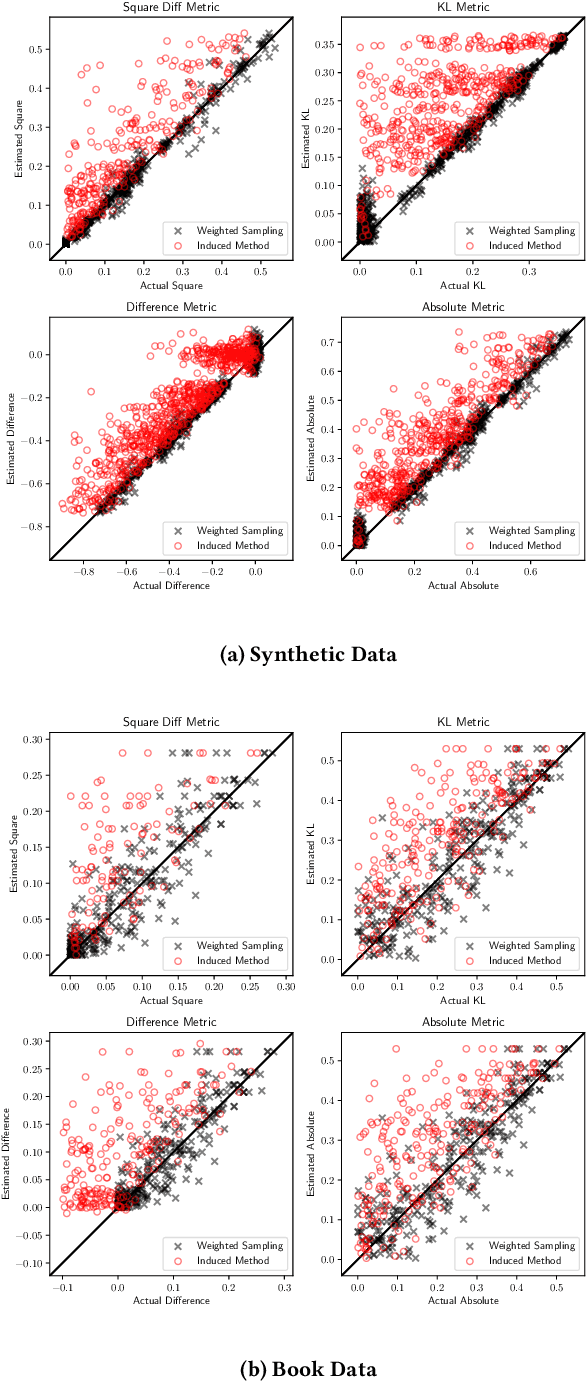
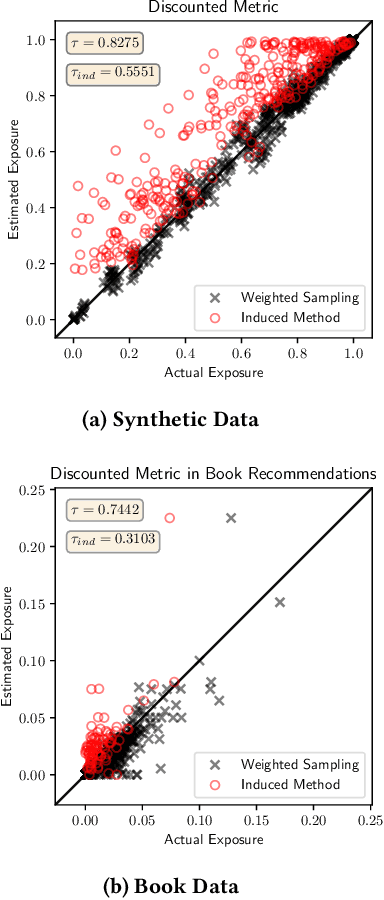

There is increasing attention to evaluating the fairness of search system ranking decisions. These metrics often consider the membership of items to particular groups, often identified using protected attributes such as gender or ethnicity. To date, these metrics typically assume the availability and completeness of protected attribute labels of items. However, the protected attributes of individuals are rarely present, limiting the application of fair ranking metrics in large scale systems. In order to address this problem, we propose a sampling strategy and estimation technique for four fair ranking metrics. We formulate a robust and unbiased estimator which can operate even with very limited number of labeled items. We evaluate our approach using both simulated and real world data. Our experimental results demonstrate that our method can estimate this family of fair ranking metrics and provides a robust, reliable alternative to exhaustive or random data annotation.