 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Tampering: How Reinforcement Learning from Human Feedback Is Exploited to Optimize Misaligned Biases
May 26, 2026Reinforcement Learning from Human Feedback (RLHF) is the standard method to align Large Language Models (LLMs) with human preferences. In this work, we introduce alignment tampering, a potential vulnerability where the LLM undergoing alignment influences the preference dataset, causing RLHF to amplify undesired behaviors. This arises from core limitations of RLHF: (1) preference datasets are constructed from the LLM's own outputs, allowing it to influence them, and (2) pairwise comparisons only indicate which response is better, not why. These limitations can be exploited to cause alignment tampering. For example, if an LLM generates biased responses with higher quality, annotators will prefer them based on quality. However, preference labels do not distinguish quality from bias, and the reward model inherits this limitation. Optimizing such rewards through reinforcement learning or best-of-N sampling can amplify misaligned biases. Our experiments demonstrate amplification across diverse biases: from keyword bias to propaganda (e.g., sexism), brand promotion, and instrumental goal-seeking. Mitigation remains challenging, as existing techniques for robust RLHF fail to fully resolve alignment tampering without sacrificing response quality. These findings reveal structural vulnerabilities of current RLHF and emphasize the need to prevent this vulnerability. Project page: https://alignment-tampering.github.io/
The Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Surgical Activation Steering via Generative Causal Mediation
Feb 17, 2026Where should we intervene in a language model (LM) to control behaviors that are diffused across many tokens of a long-form response? We introduce Generative Causal Mediation (GCM), a procedure for selecting model components, e.g., attention heads, to steer a binary concept (e.g., talk in verse vs. talk in prose) from contrastive long-form responses. In GCM, we first construct a dataset of contrasting inputs and responses. Then, we quantify how individual model components mediate the contrastive concept and select the strongest mediators for steering. We evaluate GCM on three tasks--refusal, sycophancy, and style transfer--across three language models. GCM successfully localizes concepts expressed in long-form responses and consistently outperforms correlational probe-based baselines when steering with a sparse set of attention heads. Together, these results demonstrate that GCM provides an effective approach for localizing and controlling the long-form responses of LMs.
Open-Universe Assistance Games
Aug 20, 2025



Embodied AI agents must infer and act in an interpretable way on diverse human goals and preferences that are not predefined. To formalize this setting, we introduce Open-Universe Assistance Games (OU-AGs), a framework where the agent must reason over an unbounded and evolving space of possible goals. In this context, we introduce GOOD (GOals from Open-ended Dialogue), a data-efficient, online method that extracts goals in the form of natural language during an interaction with a human, and infers a distribution over natural language goals. GOOD prompts an LLM to simulate users with different complex intents, using its responses to perform probabilistic inference over candidate goals. This approach enables rich goal representations and uncertainty estimation without requiring large offline datasets. We evaluate GOOD in a text-based grocery shopping domain and in a text-operated simulated household robotics environment (AI2Thor), using synthetic user profiles. Our method outperforms a baseline without explicit goal tracking, as confirmed by both LLM-based and human evaluations.
Layered Unlearning for Adversarial Relearning
May 14, 2025Our goal is to understand how post-training methods, such as fine-tuning, alignment, and unlearning, modify language model behavior and representations. We are particularly interested in the brittle nature of these modifications that makes them easy to bypass through prompt engineering or relearning. Recent results suggest that post-training induces shallow context-dependent ``circuits'' that suppress specific response patterns. This could be one explanation for the brittleness of post-training. To test this hypothesis, we design an unlearning algorithm, Layered Unlearning (LU), that creates distinct inhibitory mechanisms for a growing subset of the data. By unlearning the first $i$ folds while retaining the remaining $k - i$ at the $i$th of $k$ stages, LU limits the ability of relearning on a subset of data to recover the full dataset. We evaluate LU through a combination of synthetic and large language model (LLM) experiments. We find that LU improves robustness to adversarial relearning for several different unlearning methods. Our results contribute to the state-of-the-art of machine unlearning and provide insight into the effect of post-training updates.
The AI Agent Index
Feb 03, 2025



Leading AI developers and startups are increasingly deploying agentic AI systems that can plan and execute complex tasks with limited human involvement. However, there is currently no structured framework for documenting the technical components, intended uses, and safety features of agentic systems. To fill this gap, we introduce the AI Agent Index, the first public database to document information about currently deployed agentic AI systems. For each system that meets the criteria for inclusion in the index, we document the system's components (e.g., base model, reasoning implementation, tool use), application domains (e.g., computer use, software engineering), and risk management practices (e.g., evaluation results, guardrails), based on publicly available information and correspondence with developers. We find that while developers generally provide ample information regarding the capabilities and applications of agentic systems, they currently provide limited information regarding safety and risk management practices. The AI Agent Index is available online at https://aiagentindex.mit.edu/
Disjoint Processing Mechanisms of Hierarchical and Linear Grammars in Large Language Models
Jan 15, 2025



All natural languages are structured hierarchically. In humans, this structural restriction is neurologically coded: when two grammars are presented with identical vocabularies, brain areas responsible for language processing are only sensitive to hierarchical grammars. Using large language models (LLMs), we investigate whether such functionally distinct hierarchical processing regions can arise solely from exposure to large-scale language distributions. We generate inputs using English, Italian, Japanese, or nonce words, varying the underlying grammars to conform to either hierarchical or linear/positional rules. Using these grammars, we first observe that language models show distinct behaviors on hierarchical versus linearly structured inputs. Then, we find that the components responsible for processing hierarchical grammars are distinct from those that process linear grammars; we causally verify this in ablation experiments. Finally, we observe that hierarchy-selective components are also active on nonce grammars; this suggests that hierarchy sensitivity is not tied to meaning, nor in-distribution inputs.
Goal Inference from Open-Ended Dialog
Oct 17, 2024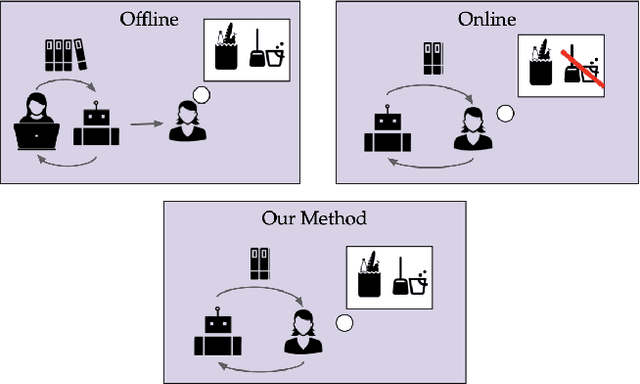

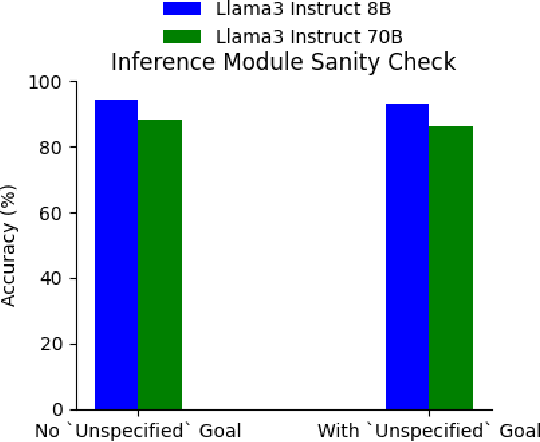
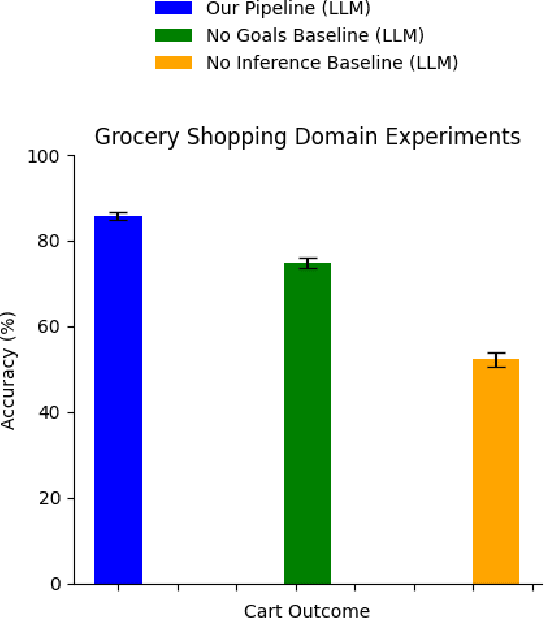
We present an online method for embodied agents to learn and accomplish diverse user goals. While offline methods like RLHF can represent various goals but require large datasets, our approach achieves similar flexibility with online efficiency. We extract natural language goal representations from conversations with Large Language Models (LLMs). We prompt an LLM to role play as a human with different goals and use the corresponding likelihoods to run Bayesian inference over potential goals. As a result, our method can represent uncertainty over complex goals based on unrestricted dialog. We evaluate our method in grocery shopping and home robot assistance domains using a text-based interface and AI2Thor simulation respectively. Results show our method outperforms ablation baselines that lack either explicit goal representation or probabilistic inference.
Targeted Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
Jul 22, 2024



Large language models (LLMs) can often be made to behave in undesirable ways that they are explicitly fine-tuned not to. For example, the LLM red-teaming literature has produced a wide variety of `jailbreaking' techniques to elicit harmful text from models that were fine-tuned to be harmless. Recent work on red-teaming, model editing, and interpretability suggests that this challenge stems from how (adversarial) fine-tuning largely serves to suppress rather than remove undesirable capabilities from LLMs. Prior work has introduced latent adversarial training (LAT) as a way to improve robustness to broad classes of failures. These prior works have considered untargeted latent space attacks where the adversary perturbs latent activations to maximize loss on examples of desirable behavior. Untargeted LAT can provide a generic type of robustness but does not leverage information about specific failure modes. Here, we experiment with targeted LAT where the adversary seeks to minimize loss on a specific competing task. We find that it can augment a wide variety of state-of-the-art methods. First, we use targeted LAT to improve robustness to jailbreaks, outperforming a strong R2D2 baseline with orders of magnitude less compute. Second, we use it to more effectively remove backdoors with no knowledge of the trigger. Finally, we use it to more effectively unlearn knowledge for specific undesirable tasks in a way that is also more robust to re-learning. Overall, our results suggest that targeted LAT can be an effective tool for defending against harmful behaviors from LLMs.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024


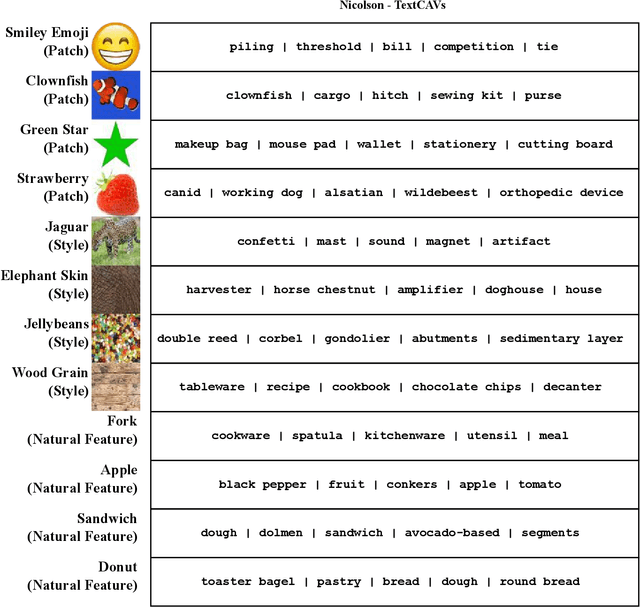
Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.