 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Adversarial Regularization for Offline Preference Optimization
Jan 29, 2026Learning from human feedback typically relies on preference optimization that constrains policy updates through token-level regularization. However, preference optimization for language models is particularly challenging because token-space similarity does not imply semantic or behavioral similarity. To address this challenge, we leverage latent-space regularization for language model preference optimization. We introduce GANPO, which achieves latent-space regularization by penalizing divergence between the internal representations of a policy model and a reference model. Given that latent representations are not associated with explicit probability densities, we adopt an adversarial approach inspired by GANs to minimize latent-space divergence. We integrate GANPO as a regularizer into existing offline preference optimization objectives. Experiments across multiple model architectures and tasks show consistent improvements from latent-space regularization. Further, by comparing GANPO-induced inferential biases with those from token-level regularization, we find that GANPO provides more robust structural feedback under distributional shift and noise while maintaining comparable downstream performance with minor computational overhead.
Convex Markov Games: A Framework for Fairness, Imitation, and Creativity in Multi-Agent Learning
Oct 22, 2024



Expert imitation, behavioral diversity, and fairness preferences give rise to preferences in sequential decision making domains that do not decompose additively across time. We introduce the class of convex Markov games that allow general convex preferences over occupancy measures. Despite infinite time horizon and strictly higher generality than Markov games, pure strategy Nash equilibria exist under strict convexity. Furthermore, equilibria can be approximated efficiently by performing gradient descent on an upper bound of exploitability. Our experiments imitate human choices in ultimatum games, reveal novel solutions to the repeated prisoner's dilemma, and find fair solutions in a repeated asymmetric coordination game. In the prisoner's dilemma, our algorithm finds a policy profile that deviates from observed human play only slightly, yet achieves higher per-player utility while also being three orders of magnitude less exploitable.
Black-Box Access is Insufficient for Rigorous AI Audits
Jan 25, 2024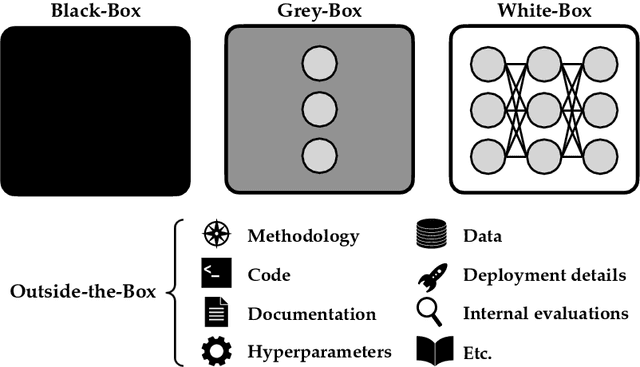
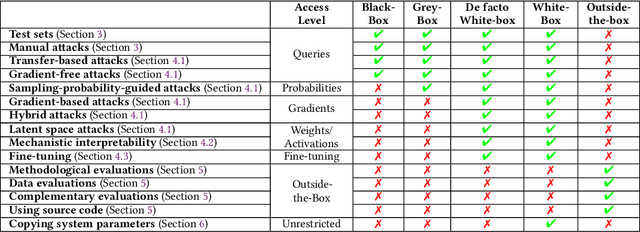
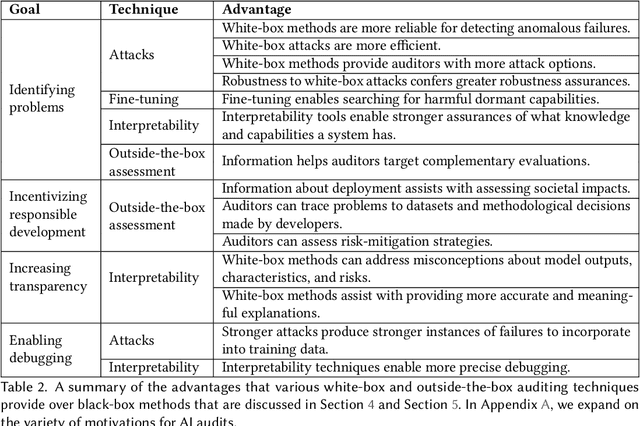
External audits of AI systems are increasingly recognized as a key mechanism for AI governance. The effectiveness of an audit, however, depends on the degree of system access granted to auditors. Recent audits of state-of-the-art AI systems have primarily relied on black-box access, in which auditors can only query the system and observe its outputs. However, white-box access to the system's inner workings (e.g., weights, activations, gradients) allows an auditor to perform stronger attacks, more thoroughly interpret models, and conduct fine-tuning. Meanwhile, outside-the-box access to its training and deployment information (e.g., methodology, code, documentation, hyperparameters, data, deployment details, findings from internal evaluations) allows for auditors to scrutinize the development process and design more targeted evaluations. In this paper, we examine the limitations of black-box audits and the advantages of white- and outside-the-box audits. We also discuss technical, physical, and legal safeguards for performing these audits with minimal security risks. Given that different forms of access can lead to very different levels of evaluation, we conclude that (1) transparency regarding the access and methods used by auditors is necessary to properly interpret audit results, and (2) white- and outside-the-box access allow for substantially more scrutiny than black-box access alone.
Recommending to Strategic Users
Feb 13, 2023



Recommendation systems are pervasive in the digital economy. An important assumption in many deployed systems is that user consumption reflects user preferences in a static sense: users consume the content they like with no other considerations in mind. However, as we document in a large-scale online survey, users do choose content strategically to influence the types of content they get recommended in the future. We model this user behavior as a two-stage noisy signalling game between the recommendation system and users: the recommendation system initially commits to a recommendation policy, presents content to the users during a cold start phase which the users choose to strategically consume in order to affect the types of content they will be recommended in a recommendation phase. We show that in equilibrium, users engage in behaviors that accentuate their differences to users of different preference profiles. In addition, (statistical) minorities out of fear of losing their minority content exposition may not consume content that is liked by mainstream users. We next propose three interventions that may improve recommendation quality (both on average and for minorities) when taking into account strategic consumption: (1) Adopting a recommendation system policy that uses preferences from a prior, (2) Communicating to users that universally liked ("mainstream") content will not be used as basis of recommendation, and (3) Serving content that is personalized-enough yet expected to be liked in the beginning. Finally, we describe a methodology to inform applied theory modeling with survey results.
Towards Psychologically-Grounded Dynamic Preference Models
Aug 06, 2022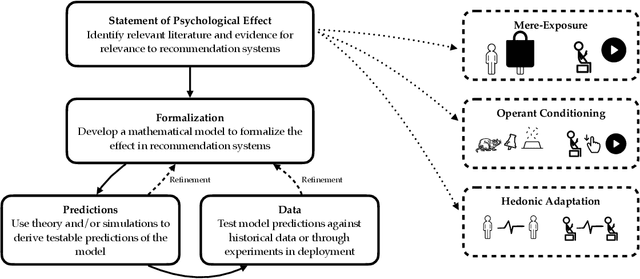
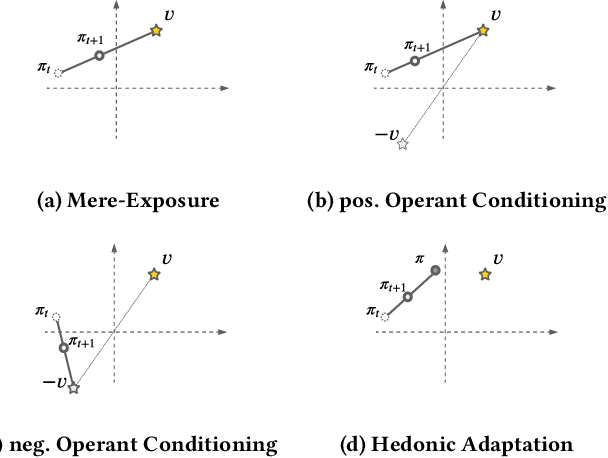
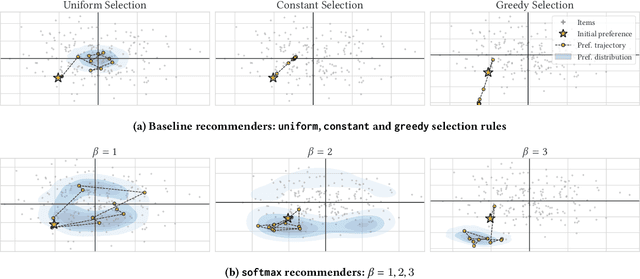
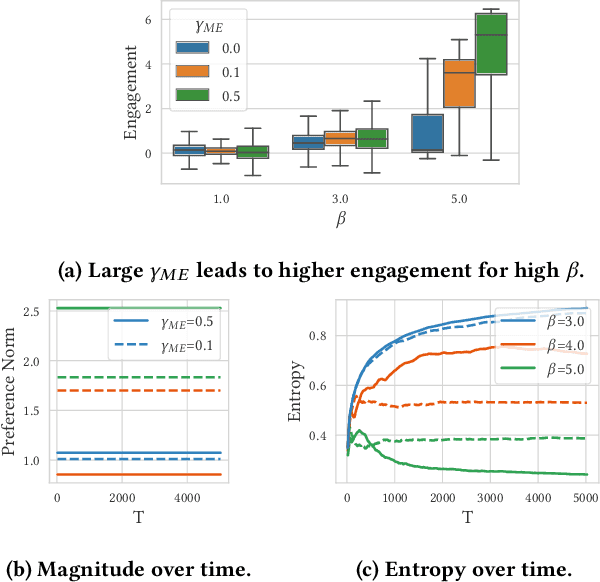
Designing recommendation systems that serve content aligned with time varying preferences requires proper accounting of the feedback effects of recommendations on human behavior and psychological condition. We argue that modeling the influence of recommendations on people's preferences must be grounded in psychologically plausible models. We contribute a methodology for developing grounded dynamic preference models. We demonstrate this method with models that capture three classic effects from the psychology literature: Mere-Exposure, Operant Conditioning, and Hedonic Adaptation. We conduct simulation-based studies to show that the psychological models manifest distinct behaviors that can inform system design. Our study has two direct implications for dynamic user modeling in recommendation systems. First, the methodology we outline is broadly applicable for psychologically grounding dynamic preference models. It allows us to critique recent contributions based on their limited discussion of psychological foundation and their implausible predictions. Second, we discuss implications of dynamic preference models for recommendation systems evaluation and design. In an example, we show that engagement and diversity metrics may be unable to capture desirable recommendation system performance.
Risk Aversion In Learning Algorithms and an Application To Recommendation Systems
May 10, 2022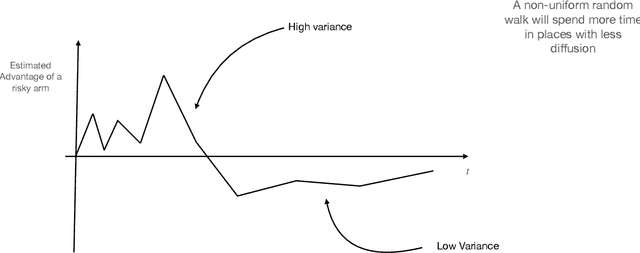
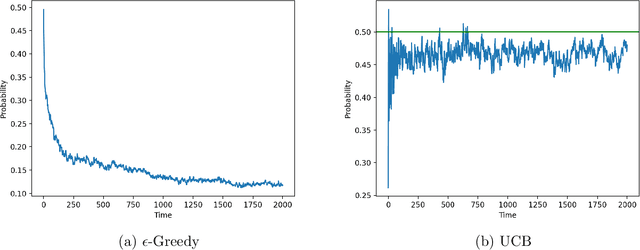
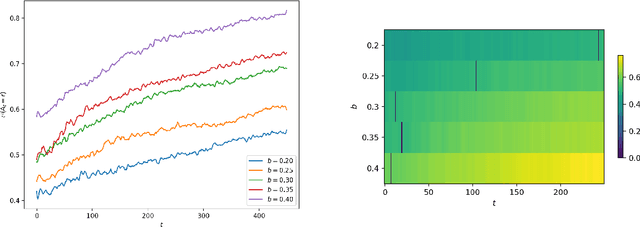
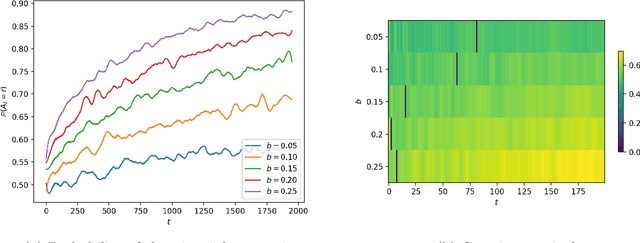
Consider a bandit learning environment. We demonstrate that popular learning algorithms such as Upper Confidence Band (UCB) and $\varepsilon$-Greedy exhibit risk aversion: when presented with two arms of the same expectation, but different variance, the algorithms tend to not choose the riskier, i.e. higher variance, arm. We prove that $\varepsilon$-Greedy chooses the risky arm with probability tending to $0$ when faced with a deterministic and a Rademacher-distributed arm. We show experimentally that UCB also shows risk-averse behavior, and that risk aversion is present persistently in early rounds of learning even if the riskier arm has a slightly higher expectation. We calibrate our model to a recommendation system and show that algorithmic risk aversion can decrease consumer surplus and increase homogeneity. We discuss several extensions to other bandit algorithms, reinforcement learning, and investigate the impacts of algorithmic risk aversion for decision theory.
Prior-Independent Auctions for the Demand Side of Federated Learning
Apr 13, 2021
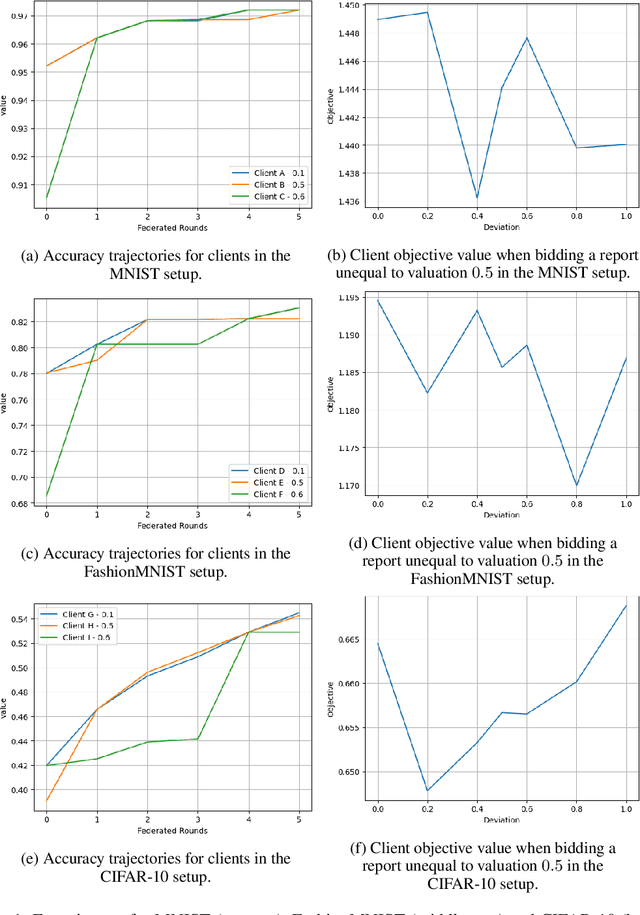
Federated learning (FL) is a paradigm that allows distributed clients to learn a shared machine learning model without sharing their sensitive training data. While largely decentralized, FL requires resources to fund a central orchestrator or to reimburse contributors of datasets to incentivize participation. Inspired by insights from prior-independent auction design, we propose a mechanism, FIPIA (Federated Incentive Payments via Prior-Independent Auctions), to collect monetary contributions from self-interested clients. The mechanism operates in the semi-honest trust model and works even if clients have a heterogeneous interest in receiving high-quality models, and the server does not know the clients' level of interest. We run experiments on the MNIST, FashionMNIST, and CIFAR-10 datasets to test clients' model quality under FIPIA and FIPIA's incentive properties.
Classification on Large Networks: A Quantitative Bound via Motifs and Graphons
Oct 24, 2017

When each data point is a large graph, graph statistics such as densities of certain subgraphs (motifs) can be used as feature vectors for machine learning. While intuitive, motif counts are expensive to compute and difficult to work with theoretically. Via graphon theory, we give an explicit quantitative bound for the ability of motif homomorphisms to distinguish large networks under both generative and sampling noise. Furthermore, we give similar bounds for the graph spectrum and connect it to homomorphism densities of cycles. This results in an easily computable classifier on graph data with theoretical performance guarantee. Our method yields competitive results on classification tasks for the autoimmune disease Lupus Erythematosus.