 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Task Learning & Model Fusion for Efficient Language Model Guardrailing
Apr 29, 2025



The trend towards large language models (LLMs) for guardrailing against undesired behaviors is increasing and has shown promise for censoring user inputs. However, increased latency, memory consumption, hosting expenses and non-structured outputs can make their use prohibitive. In this work, we show that task-specific data generation can lead to fine-tuned classifiers that significantly outperform current state of the art (SoTA) while being orders of magnitude smaller. Secondly, we show that using a single model, \texttt{MultiTaskGuard}, that is pretrained on a large synthetically generated dataset with unique task instructions further improves generalization. Thirdly, our most performant models, \texttt{UniGuard}, are found using our proposed search-based model merging approach that finds an optimal set of parameters to combine single-policy models and multi-policy guardrail models. % On 7 public datasets and 4 guardrail benchmarks we created, our efficient guardrail classifiers improve over the best performing SoTA publicly available LLMs and 3$^{\text{rd}}$ party guardrail APIs in detecting unsafe and safe behaviors by an average F1 score improvement of \textbf{29.92} points over Aegis-LlamaGuard and \textbf{21.62} over \texttt{gpt-4o}, respectively. Lastly, our guardrail synthetic data generation process that uses custom task-specific guardrail poli
Know Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges
Mar 06, 2025



Large Language Model (LLM) based judges form the underpinnings of key safety evaluation processes such as offline benchmarking, automated red-teaming, and online guardrailing. This widespread requirement raises the crucial question: can we trust the evaluations of these evaluators? In this paper, we highlight two critical challenges that are typically overlooked: (i) evaluations in the wild where factors like prompt sensitivity and distribution shifts can affect performance and (ii) adversarial attacks that target the judge. We highlight the importance of these through a study of commonly used safety judges, showing that small changes such as the style of the model output can lead to jumps of up to 0.24 in the false negative rate on the same dataset, whereas adversarial attacks on the model generation can fool some judges into misclassifying 100% of harmful generations as safe ones. These findings reveal gaps in commonly used meta-evaluation benchmarks and weaknesses in the robustness of current LLM judges, indicating that low attack success under certain judges could create a false sense of security.
PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
Jul 23, 2024

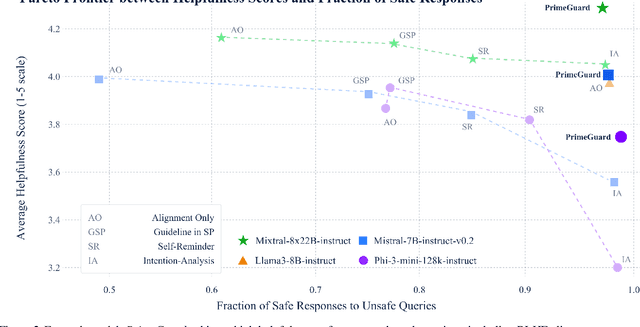

Deploying language models (LMs) necessitates outputs to be both high-quality and compliant with safety guidelines. Although Inference-Time Guardrails (ITG) offer solutions that shift model output distributions towards compliance, we find that current methods struggle in balancing safety with helpfulness. ITG Methods that safely address non-compliant queries exhibit lower helpfulness while those that prioritize helpfulness compromise on safety. We refer to this trade-off as the guardrail tax, analogous to the alignment tax. To address this, we propose PrimeGuard, a novel ITG method that utilizes structured control flow. PrimeGuard routes requests to different self-instantiations of the LM with varying instructions, leveraging its inherent instruction-following capabilities and in-context learning. Our tuning-free approach dynamically compiles system-designer guidelines for each query. We construct and release safe-eval, a diverse red-team safety benchmark. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, overcomes the guardrail tax by (1) significantly increasing resistance to iterative jailbreak attacks and (2) achieving state-of-the-art results in safety guardrailing while (3) matching helpfulness scores of alignment-tuned models. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, outperforms all competing baselines and overcomes the guardrail tax by improving the fraction of safe responses from 61% to 97% and increasing average helpfulness scores from 4.17 to 4.29 on the largest models, while reducing attack success rate from 100% to 8%. PrimeGuard implementation is available at https://github.com/dynamofl/PrimeGuard and safe-eval dataset is available at https://huggingface.co/datasets/dynamoai/safe_eval.
Navigating Data Heterogeneity in Federated Learning A Semi-Supervised Approach for Object Detection
Oct 27, 2023



Federated Learning (FL) has emerged as a potent framework for training models across distributed data sources while maintaining data privacy. Nevertheless, it faces challenges with limited high-quality labels and non-IID client data, particularly in applications like autonomous driving. To address these hurdles, we navigate the uncharted waters of Semi-Supervised Federated Object Detection (SSFOD). We present a pioneering SSFOD framework, designed for scenarios where labeled data reside only at the server while clients possess unlabeled data. Notably, our method represents the inaugural implementation of SSFOD for clients with 0% labeled non-IID data, a stark contrast to previous studies that maintain some subset of labels at each client. We propose FedSTO, a two-stage strategy encompassing Selective Training followed by Orthogonally enhanced full-parameter training, to effectively address data shift (e.g. weather conditions) between server and clients. Our contributions include selectively refining the backbone of the detector to avert overfitting, orthogonality regularization to boost representation divergence, and local EMA-driven pseudo label assignment to yield high-quality pseudo labels. Extensive validation on prominent autonomous driving datasets (BDD100K, Cityscapes, and SODA10M) attests to the efficacy of our approach, demonstrating state-of-the-art results. Remarkably, FedSTO, using just 20-30% of labels, performs nearly as well as fully-supervised centralized training methods.
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information?
Jul 31, 2023



Machine learning practitioners often fine-tune generative pre-trained models like GPT-3 to improve model performance at specific tasks. Previous works, however, suggest that fine-tuned machine learning models memorize and emit sensitive information from the original fine-tuning dataset. Companies such as OpenAI offer fine-tuning services for their models, but no prior work has conducted a memorization attack on any closed-source models. In this work, we simulate a privacy attack on GPT-3 using OpenAI's fine-tuning API. Our objective is to determine if personally identifiable information (PII) can be extracted from this model. We (1) explore the use of naive prompting methods on a GPT-3 fine-tuned classification model, and (2) we design a practical word generation task called Autocomplete to investigate the extent of PII memorization in fine-tuned GPT-3 within a real-world context. Our findings reveal that fine-tuning GPT3 for both tasks led to the model memorizing and disclosing critical personally identifiable information (PII) obtained from the underlying fine-tuning dataset. To encourage further research, we have made our codes and datasets publicly available on GitHub at: https://github.com/albertsun1/gpt3-pii-attacks
Collusion Resistant Federated Learning with Oblivious Distributed Differential Privacy
Feb 20, 2022
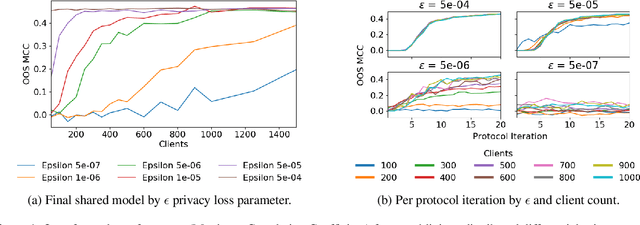
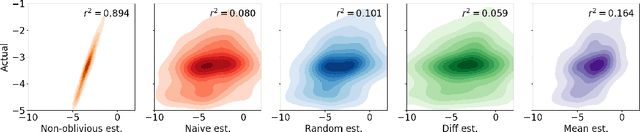
Privacy-preserving federated learning enables a population of distributed clients to jointly learn a shared model while keeping client training data private, even from an untrusted server. Prior works do not provide efficient solutions that protect against collusion attacks in which parties collaborate to expose an honest client's model parameters. We present an efficient mechanism based on oblivious distributed differential privacy that is the first to protect against such client collusion, including the "Sybil" attack in which a server preferentially selects compromised devices or simulates fake devices. We leverage the novel privacy mechanism to construct a secure federated learning protocol and prove the security of that protocol. We conclude with empirical analysis of the protocol's execution speed, learning accuracy, and privacy performance on two data sets within a realistic simulation of 5,000 distributed network clients.
Gradient Masked Averaging for Federated Learning
Jan 28, 2022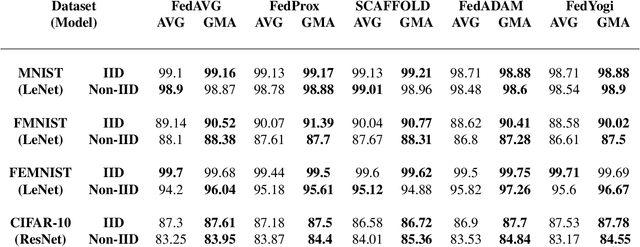
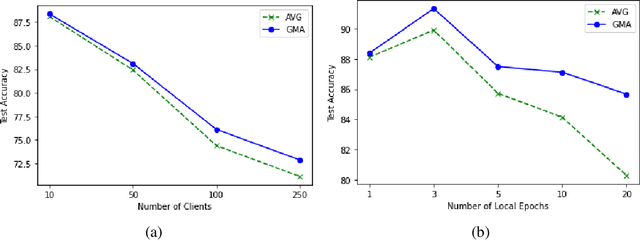

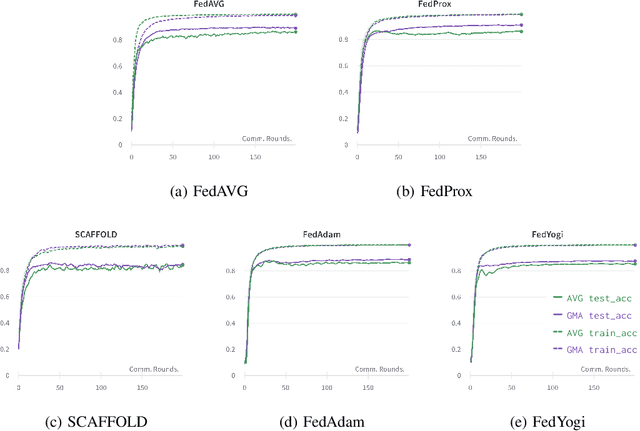
Federated learning is an emerging paradigm that permits a large number of clients with heterogeneous data to coordinate learning of a unified global model without the need to share data amongst each other. Standard federated learning algorithms involve averaging of model parameters or gradient updates to approximate the global model at the server. However, in heterogeneous settings averaging can result in information loss and lead to poor generalization due to the bias induced by dominant clients. We hypothesize that to generalize better across non-i.i.d datasets as in FL settings, the algorithms should focus on learning the invariant mechanism that is constant while ignoring spurious mechanisms that differ across clients. Inspired from recent work in the Out-of-Distribution literature, we propose a gradient masked averaging approach for federated learning as an alternative to the standard averaging of client updates. This client update aggregation technique can be adapted as a drop-in replacement in most existing federated algorithms. We perform extensive experiments with gradient masked approach on multiple FL algorithms with in-distribution, real-world, and out-of-distribution (as the worst case scenario) test dataset and show that it provides consistent improvements, particularly in the case of heterogeneous clients.
Multi-VFL: A Vertical Federated Learning System for Multiple Data and Label Owners
Jun 17, 2021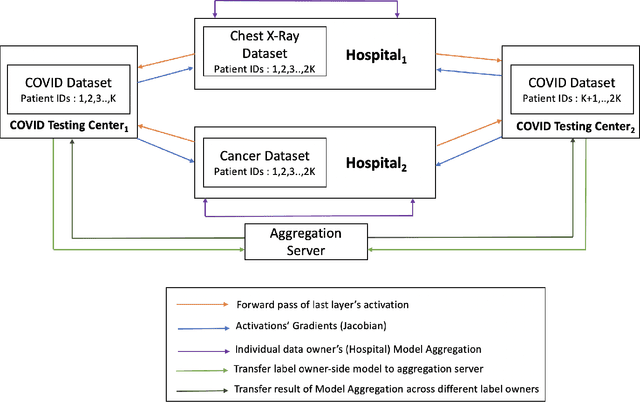


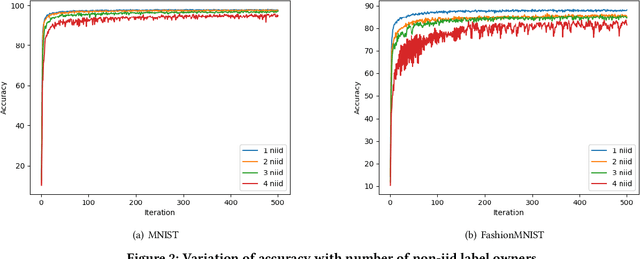
Vertical Federated Learning (VFL) refers to the collaborative training of a model on a dataset where the features of the dataset are split among multiple data owners, while label information is owned by a single data owner. In this paper, we propose a novel method, Multi Vertical Federated Learning (Multi-VFL), to train VFL models when there are multiple data and label owners. Our approach is the first to consider the setting where $D$-data owners (across which features are distributed) and $K$-label owners (across which labels are distributed) exist. This proposed configuration allows different entities to train and learn optimal models without having to share their data. Our framework makes use of split learning and adaptive federated optimizers to solve this problem. For empirical evaluation, we run experiments on the MNIST and FashionMNIST datasets. Our results show that using adaptive optimizers for model aggregation fastens convergence and improves accuracy.
Prior-Independent Auctions for the Demand Side of Federated Learning
Apr 13, 2021
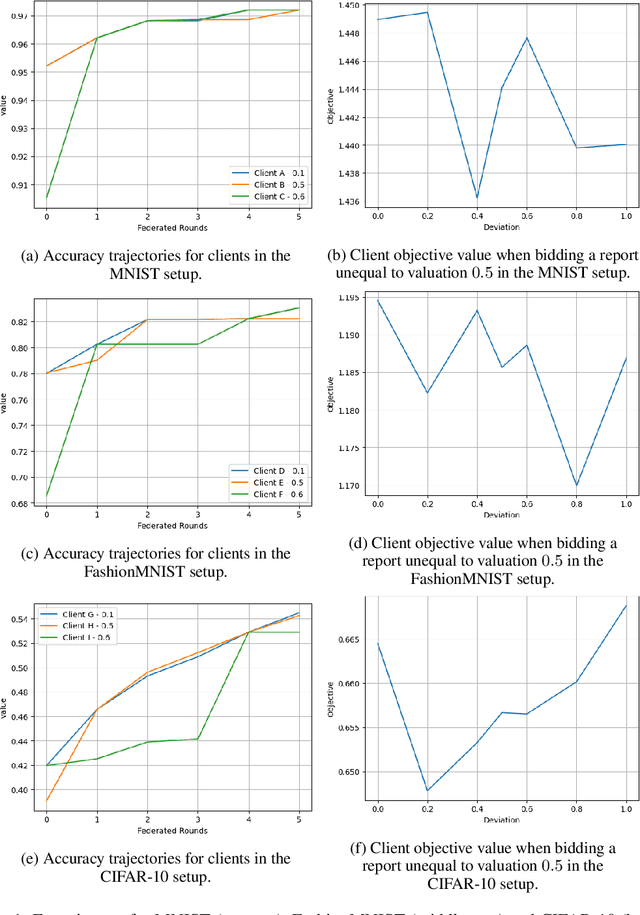
Federated learning (FL) is a paradigm that allows distributed clients to learn a shared machine learning model without sharing their sensitive training data. While largely decentralized, FL requires resources to fund a central orchestrator or to reimburse contributors of datasets to incentivize participation. Inspired by insights from prior-independent auction design, we propose a mechanism, FIPIA (Federated Incentive Payments via Prior-Independent Auctions), to collect monetary contributions from self-interested clients. The mechanism operates in the semi-honest trust model and works even if clients have a heterogeneous interest in receiving high-quality models, and the server does not know the clients' level of interest. We run experiments on the MNIST, FashionMNIST, and CIFAR-10 datasets to test clients' model quality under FIPIA and FIPIA's incentive properties.
Bias-Free FedGAN
Mar 17, 2021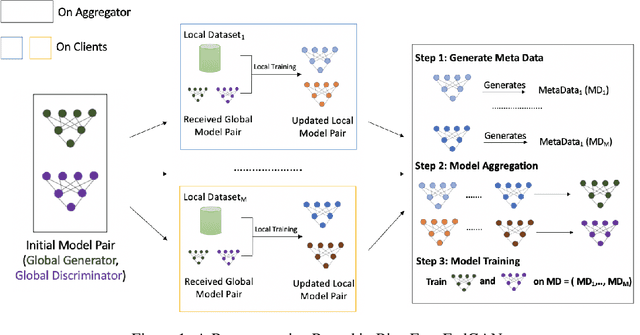

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.