 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeontic Policies for Runtime Governance of Agentic AI Systems
Jun 17, 2026Autonomous agentic AI systems driven by Large Language Models (LLMs) introduce a new class of security, privacy, and compliance challenges: an agent that can invoke tools, manipulate data, install software, and coordinate with peer agents across organizational boundaries must be constrained not just by authentication and access control, but by the full structure of enterprise governance. This includes specifying what agents are permitted and prohibited from doing, what they areobliged to do after certain actions (e.g., notify the CISO), under what conditions a standing obligation may be waived, and which rules take precedence when policies conflict. This governance problem exceeds what current policy engines provide. Systems such as XACML, Rego, and Cedar address only the permit/prohibit subset of this governance structure. They do not provide obligation lifecycle management, meta-policy conflict resolution, dispensations that waive obligations in specific circumstances, and ontological reasoning over domain class hierarchies commonly found in applications such as healthcare, cybersecurity, or data privacy. We propose AgenticRei, which realizes key governance requirements such as obligations, dispensations, policy conflict resolutions, and reasoning over policies, as well as the basic permit/prohibit constraints. We use a deontic policy language built on the Rei framework, expressed as OWL (Web Ontology Language) and evaluated at runtime by a high-performance logic engine entirely outside the LLM. The same pipeline governs both tool invocations by the agent and agent-to-agent messages. We show through examples that deontic policies capture governance constraints around security and privacy that mostly cannot be expressed in current production engines. Our approach composes naturally with industry-standard frameworks like A2AS.
Forget to Generalize: Iterative Adaptation for Generalization in Federated Learning
Feb 04, 2026The Web is naturally heterogeneous with user devices, geographic regions, browsing patterns, and contexts all leading to highly diverse, unique datasets. Federated Learning (FL) is an important paradigm for the Web because it enables privacy-preserving, collaborative machine learning across diverse user devices, web services and clients without needing to centralize sensitive data. However, its performance degrades severely under non-IID client distributions that is prevalent in real-world web systems. In this work, we propose a new training paradigm - Iterative Federated Adaptation (IFA) - that enhances generalization in heterogeneous federated settings through generation-wise forget and evolve strategy. Specifically, we divide training into multiple generations and, at the end of each, select a fraction of model parameters (a) randomly or (b) from the later layers of the model and reinitialize them. This iterative forget and evolve schedule allows the model to escape local minima and preserve globally relevant representations. Extensive experiments on CIFAR-10, MIT-Indoors, and Stanford Dogs datasets show that the proposed approach improves global accuracy, especially when the data cross clients are Non-IID. This method can be implemented on top any federated algorithm to improve its generalization performance. We observe an average of 21.5%improvement across datasets. This work advances the vision of scalable, privacy-preserving intelligence for real-world heterogeneous and distributed web systems.
Investigating Model Editing for Unlearning in Large Language Models
Dec 23, 2025



Machine unlearning aims to remove unwanted information from a model, but many methods are inefficient for LLMs with large numbers of parameters or fail to fully remove the intended information without degrading performance on knowledge that should be retained. Model editing algorithms solve a similar problem of changing information in models, but they focus on redirecting inputs to a new target rather than removing that information altogether. In this work, we explore the editing algorithms ROME, IKE, and WISE and design new editing targets for an unlearning setting. Through this investigation, we show that model editing approaches can exceed baseline unlearning methods in terms of quality of forgetting depending on the setting. Like traditional unlearning techniques, they struggle to encapsulate the scope of what is to be unlearned without damage to the overall model performance.
Towards Resource Efficient and Interpretable Bias Mitigation in Large Language Models
Dec 02, 2024



Although large language models (LLMs) have demonstrated their effectiveness in a wide range of applications, they have also been observed to perpetuate unwanted biases present in the training data, potentially leading to harm for marginalized communities. In this paper, we mitigate bias by leveraging small biased and anti-biased expert models to obtain a debiasing signal that will be added to the LLM output at decoding-time. This approach combines resource efficiency with interpretability and can be optimized for mitigating specific types of bias, depending on the target use case. Experiments on mitigating gender, race, and religion biases show a reduction in bias on several local and global bias metrics while preserving language model performance.
Multi-VFL: A Vertical Federated Learning System for Multiple Data and Label Owners
Jun 17, 2021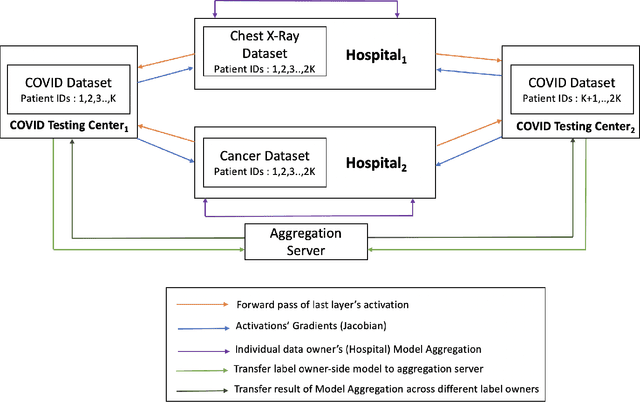


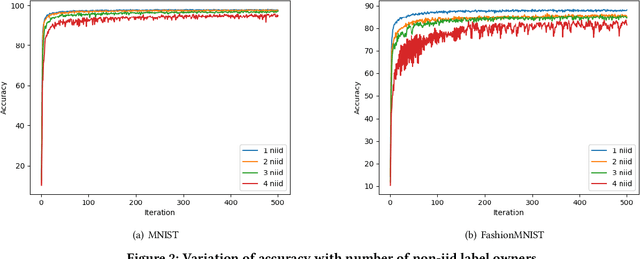
Vertical Federated Learning (VFL) refers to the collaborative training of a model on a dataset where the features of the dataset are split among multiple data owners, while label information is owned by a single data owner. In this paper, we propose a novel method, Multi Vertical Federated Learning (Multi-VFL), to train VFL models when there are multiple data and label owners. Our approach is the first to consider the setting where $D$-data owners (across which features are distributed) and $K$-label owners (across which labels are distributed) exist. This proposed configuration allows different entities to train and learn optimal models without having to share their data. Our framework makes use of split learning and adaptive federated optimizers to solve this problem. For empirical evaluation, we run experiments on the MNIST and FashionMNIST datasets. Our results show that using adaptive optimizers for model aggregation fastens convergence and improves accuracy.
Bias-Free FedGAN
Mar 17, 2021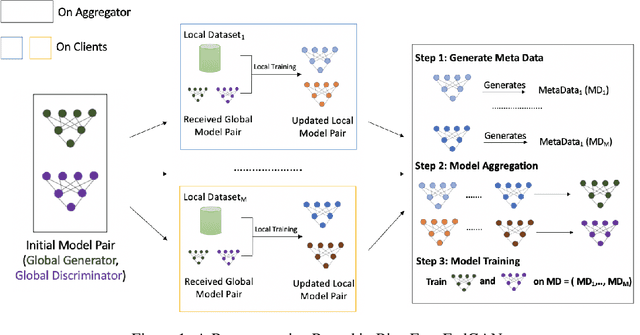

Federated Generative Adversarial Network (FedGAN) is a communication-efficient approach to train a GAN across distributed clients without clients having to share their sensitive training data. In this paper, we experimentally show that FedGAN generates biased data points under non-independent-and-identically-distributed (non-iid) settings. Also, we propose Bias-Free FedGAN, an approach to generate bias-free synthetic datasets using FedGAN. Bias-Free FedGAN has the same communication cost as that of FedGAN. Experimental results on image datasets (MNIST and FashionMNIST) validate our claims.
Investigating Bias in Image Classification using Model Explanations
Dec 10, 2020

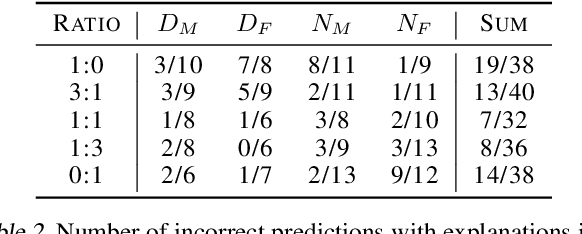
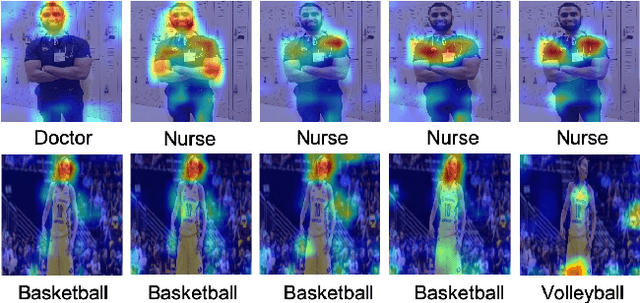
We evaluated whether model explanations could efficiently detect bias in image classification by highlighting discriminating features, thereby removing the reliance on sensitive attributes for fairness calculations. To this end, we formulated important characteristics for bias detection and observed how explanations change as the degree of bias in models change. The paper identifies strengths and best practices for detecting bias using explanations, as well as three main weaknesses: explanations poorly estimate the degree of bias, could potentially introduce additional bias into the analysis, and are sometimes inefficient in terms of human effort involved.
DPD-InfoGAN: Differentially Private Distributed InfoGAN
Oct 24, 2020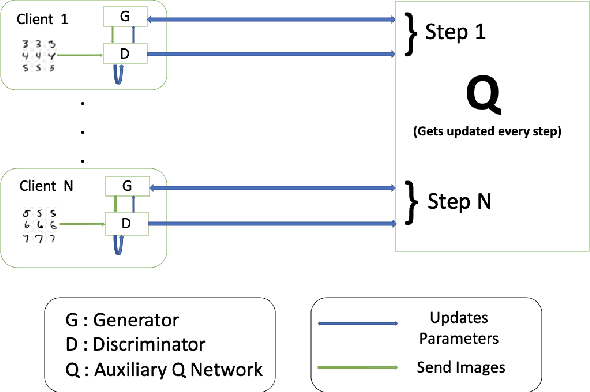
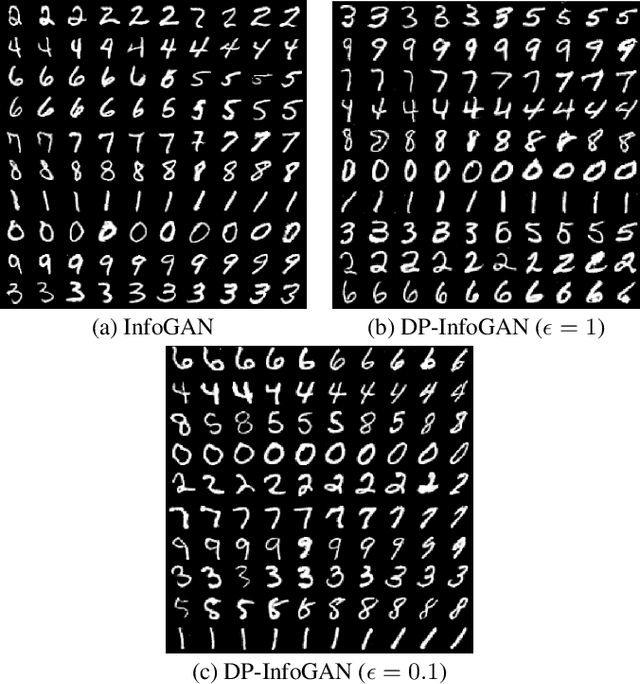


Generative Adversarial Networks (GANs) are deep learning architectures capable of generating synthetic datasets. Despite producing high-quality synthetic images, the default GAN has no control over the kinds of images it generates. The Information Maximizing GAN (InfoGAN) is a variant of the default GAN that introduces feature-control variables that are automatically learned by the framework, hence providing greater control over the different kinds of images produced. Due to the high model complexity of InfoGAN, the generative distribution tends to be concentrated around the training data points. This is a critical problem as the models may inadvertently expose the sensitive and private information present in the dataset. To address this problem, we propose a differentially private version of InfoGAN (DP-InfoGAN). We also extend our framework to a distributed setting (DPD-InfoGAN) to allow clients to learn different attributes present in other clients' datasets in a privacy-preserving manner. In our experiments, we show that both DP-InfoGAN and DPD-InfoGAN can synthesize high-quality images with flexible control over image attributes while preserving privacy.
BlockFLow: An Accountable and Privacy-Preserving Solution for Federated Learning
Jul 08, 2020



Federated learning enables the development of a machine learning model among collaborating agents without requiring them to share their underlying data. However, malicious agents who train on random data, or worse, on datasets with the result classes inverted, can weaken the combined model. BlockFLow is an accountable federated learning system that is fully decentralized and privacy-preserving. Its primary goal is to reward agents proportional to the quality of their contribution while protecting the privacy of the underlying datasets and being resilient to malicious adversaries. Specifically, BlockFLow incorporates differential privacy, introduces a novel auditing mechanism for model contribution, and uses Ethereum smart contracts to incentivize good behavior. Unlike existing auditing and accountability methods for federated learning systems, our system does not require a centralized test dataset, sharing of datasets between the agents, or one or more trusted auditors; it is fully decentralized and resilient up to a 50% collusion attack in a malicious trust model. When run on the public Ethereum blockchain, BlockFLow uses the results from the audit to reward parties with cryptocurrency based on the quality of their contribution. We evaluated BlockFLow on two datasets that offer classification tasks solvable via logistic regression models. Our results show that the resultant auditing scores reflect the quality of the honest agents' datasets. Moreover, the scores from dishonest agents are statistically lower than those from the honest agents. These results, along with the reasonable blockchain costs, demonstrate the effectiveness of BlockFLow as an accountable federated learning system.
PrivacyFL: A simulator for privacy-preserving and secure federated learning
Feb 19, 2020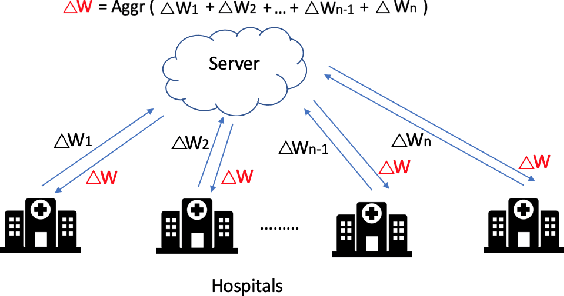

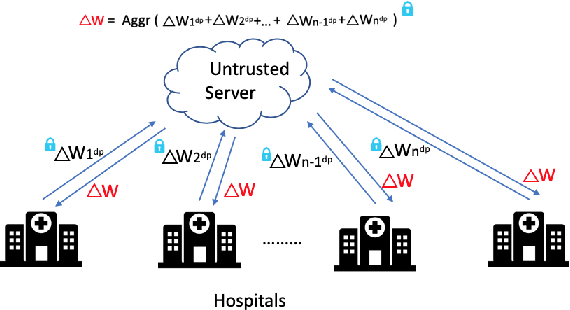
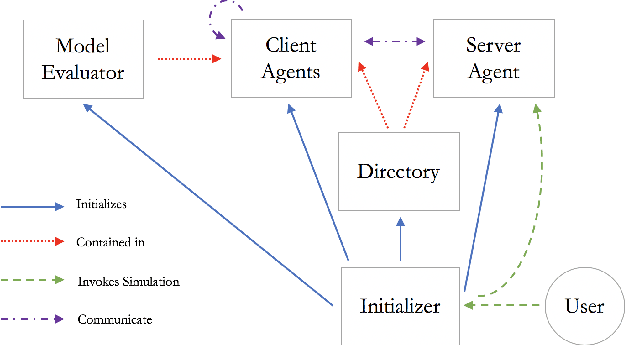
Federated learning is a technique that enables distributed clients to collaboratively learn a shared machine learning model while keeping their training data localized. This reduces data privacy risks, however, privacy concerns still exist since it is possible to leak information about the training dataset from the trained model's weights or parameters. Setting up a federated learning environment, especially with security and privacy guarantees, is a time-consuming process with numerous configurations and parameters that can be manipulated. In order to help clients ensure that collaboration is feasible and to check that it improves their model accuracy, a real-world simulator for privacy-preserving and secure federated learning is required. In this paper, we introduce PrivacyFL, which is an extensible, easily configurable and scalable simulator for federated learning environments. Its key features include latency simulation, robustness to client departure, support for both centralized and decentralized learning, and configurable privacy and security mechanisms based on differential privacy and secure multiparty computation. In this paper, we motivate our research, describe the architecture of the simulator and associated protocols, and discuss its evaluation in numerous scenarios that highlight its wide range of functionality and its advantages. Our paper addresses a significant real-world problem: checking the feasibility of participating in a federated learning environment under a variety of circumstances. It also has a strong practical impact because organizations such as hospitals, banks, and research institutes, which have large amounts of sensitive data and would like to collaborate, would greatly benefit from having a system that enables them to do so in a privacy-preserving and secure manner.