 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Resource Efficient and Interpretable Bias Mitigation in Large Language Models
Dec 02, 2024Although large language models (LLMs) have demonstrated their effectiveness in a wide range of applications, they have also been observed to perpetuate unwanted biases present in the training data, potentially leading to harm for marginalized communities. In this paper, we mitigate bias by leveraging small biased and anti-biased expert models to obtain a debiasing signal that will be added to the LLM output at decoding-time. This approach combines resource efficiency with interpretability and can be optimized for mitigating specific types of bias, depending on the target use case. Experiments on mitigating gender, race, and religion biases show a reduction in bias on several local and global bias metrics while preserving language model performance.
Investigating Bias in Image Classification using Model Explanations
Dec 10, 2020

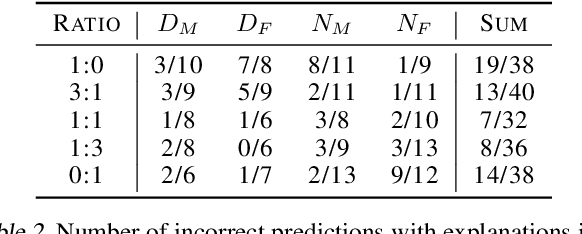
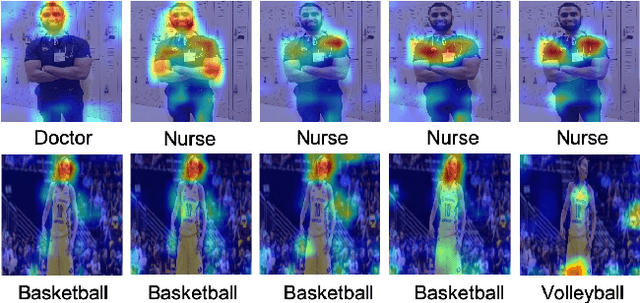
We evaluated whether model explanations could efficiently detect bias in image classification by highlighting discriminating features, thereby removing the reliance on sensitive attributes for fairness calculations. To this end, we formulated important characteristics for bias detection and observed how explanations change as the degree of bias in models change. The paper identifies strengths and best practices for detecting bias using explanations, as well as three main weaknesses: explanations poorly estimate the degree of bias, could potentially introduce additional bias into the analysis, and are sometimes inefficient in terms of human effort involved.
Clinical Text Summarization with Syntax-Based Negation and Semantic Concept Identification
Feb 29, 2020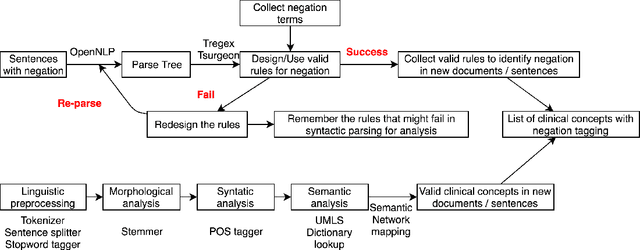


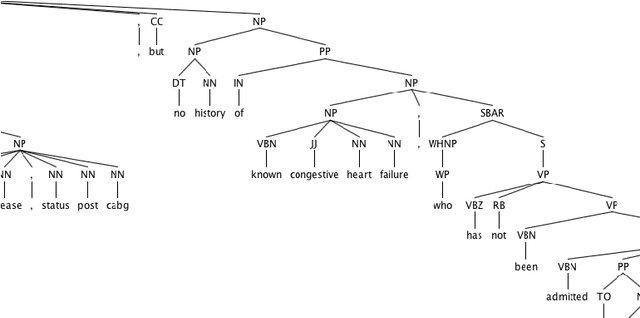
In the era of clinical information explosion, a good strategy for clinical text summarization is helpful to improve the clinical workflow. The ideal summarization strategy can preserve important information in the informative but less organized, ill-structured clinical narrative texts. Instead of using pure statistical learning approaches, which are difficult to interpret and explain, we utilized knowledge of computational linguistics with human experts-curated biomedical knowledge base to achieve the interpretable and meaningful clinical text summarization. Our research objective is to use the biomedical ontology with semantic information, and take the advantage from the language hierarchical structure, the constituency tree, in order to identify the correct clinical concepts and the corresponding negation information, which is critical for summarizing clinical concepts from narrative text. We achieved the clinically acceptable performance for both negation detection and concept identification, and the clinical concepts with common negated patterns can be identified and negated by the proposed method.
Towards Unsupervised Speech-to-Text Translation
Nov 04, 2018
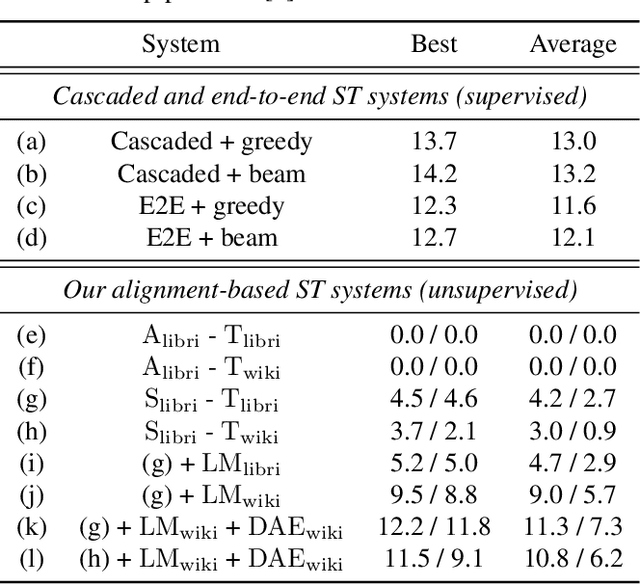
We present a framework for building speech-to-text translation (ST) systems using only monolingual speech and text corpora, in other words, speech utterances from a source language and independent text from a target language. As opposed to traditional cascaded systems and end-to-end architectures, our system does not require any labeled data (i.e., transcribed source audio or parallel source and target text corpora) during training, making it especially applicable to language pairs with very few or even zero bilingual resources. The framework initializes the ST system with a cross-modal bilingual dictionary inferred from the monolingual corpora, that maps every source speech segment corresponding to a spoken word to its target text translation. For unseen source speech utterances, the system first performs word-by-word translation on each speech segment in the utterance. The translation is improved by leveraging a language model and a sequence denoising autoencoder to provide prior knowledge about the target language. Experimental results show that our unsupervised system achieves comparable BLEU scores to supervised end-to-end models despite the lack of supervision. We also provide an ablation analysis to examine the utility of each component in our system.
Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces
Sep 20, 2018

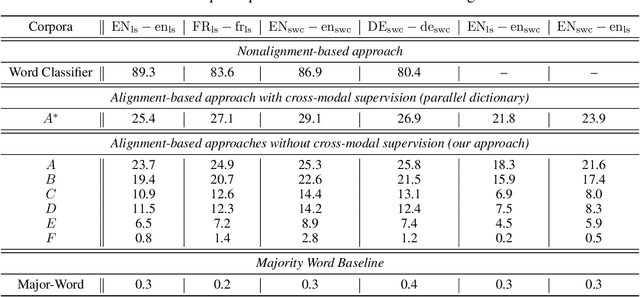

Recent research has shown that word embedding spaces learned from text corpora of different languages can be aligned without any parallel data supervision. Inspired by the success in unsupervised cross-lingual word embeddings, in this paper we target learning a cross-modal alignment between the embedding spaces of speech and text learned from corpora of their respective modalities in an unsupervised fashion. The proposed framework learns the individual speech and text embedding spaces, and attempts to align the two spaces via adversarial training, followed by a refinement procedure. We show how our framework could be used to perform spoken word classification and translation, and the results on these two tasks demonstrate that the performance of our unsupervised alignment approach is comparable to its supervised counterpart. Our framework is especially useful for developing automatic speech recognition (ASR) and speech-to-text translation systems for low- or zero-resource languages, which have little parallel audio-text data for training modern supervised ASR and speech-to-text translation models, but account for the majority of the languages spoken across the world.