 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges
Mar 06, 2025



Large Language Model (LLM) based judges form the underpinnings of key safety evaluation processes such as offline benchmarking, automated red-teaming, and online guardrailing. This widespread requirement raises the crucial question: can we trust the evaluations of these evaluators? In this paper, we highlight two critical challenges that are typically overlooked: (i) evaluations in the wild where factors like prompt sensitivity and distribution shifts can affect performance and (ii) adversarial attacks that target the judge. We highlight the importance of these through a study of commonly used safety judges, showing that small changes such as the style of the model output can lead to jumps of up to 0.24 in the false negative rate on the same dataset, whereas adversarial attacks on the model generation can fool some judges into misclassifying 100% of harmful generations as safe ones. These findings reveal gaps in commonly used meta-evaluation benchmarks and weaknesses in the robustness of current LLM judges, indicating that low attack success under certain judges could create a false sense of security.
Towards Resource Efficient and Interpretable Bias Mitigation in Large Language Models
Dec 02, 2024



Although large language models (LLMs) have demonstrated their effectiveness in a wide range of applications, they have also been observed to perpetuate unwanted biases present in the training data, potentially leading to harm for marginalized communities. In this paper, we mitigate bias by leveraging small biased and anti-biased expert models to obtain a debiasing signal that will be added to the LLM output at decoding-time. This approach combines resource efficiency with interpretability and can be optimized for mitigating specific types of bias, depending on the target use case. Experiments on mitigating gender, race, and religion biases show a reduction in bias on several local and global bias metrics while preserving language model performance.
PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
Jul 23, 2024

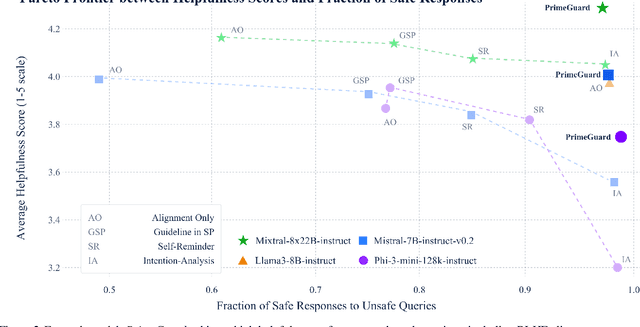

Deploying language models (LMs) necessitates outputs to be both high-quality and compliant with safety guidelines. Although Inference-Time Guardrails (ITG) offer solutions that shift model output distributions towards compliance, we find that current methods struggle in balancing safety with helpfulness. ITG Methods that safely address non-compliant queries exhibit lower helpfulness while those that prioritize helpfulness compromise on safety. We refer to this trade-off as the guardrail tax, analogous to the alignment tax. To address this, we propose PrimeGuard, a novel ITG method that utilizes structured control flow. PrimeGuard routes requests to different self-instantiations of the LM with varying instructions, leveraging its inherent instruction-following capabilities and in-context learning. Our tuning-free approach dynamically compiles system-designer guidelines for each query. We construct and release safe-eval, a diverse red-team safety benchmark. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, overcomes the guardrail tax by (1) significantly increasing resistance to iterative jailbreak attacks and (2) achieving state-of-the-art results in safety guardrailing while (3) matching helpfulness scores of alignment-tuned models. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, outperforms all competing baselines and overcomes the guardrail tax by improving the fraction of safe responses from 61% to 97% and increasing average helpfulness scores from 4.17 to 4.29 on the largest models, while reducing attack success rate from 100% to 8%. PrimeGuard implementation is available at https://github.com/dynamofl/PrimeGuard and safe-eval dataset is available at https://huggingface.co/datasets/dynamoai/safe_eval.
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information?
Jul 31, 2023



Machine learning practitioners often fine-tune generative pre-trained models like GPT-3 to improve model performance at specific tasks. Previous works, however, suggest that fine-tuned machine learning models memorize and emit sensitive information from the original fine-tuning dataset. Companies such as OpenAI offer fine-tuning services for their models, but no prior work has conducted a memorization attack on any closed-source models. In this work, we simulate a privacy attack on GPT-3 using OpenAI's fine-tuning API. Our objective is to determine if personally identifiable information (PII) can be extracted from this model. We (1) explore the use of naive prompting methods on a GPT-3 fine-tuned classification model, and (2) we design a practical word generation task called Autocomplete to investigate the extent of PII memorization in fine-tuned GPT-3 within a real-world context. Our findings reveal that fine-tuning GPT3 for both tasks led to the model memorizing and disclosing critical personally identifiable information (PII) obtained from the underlying fine-tuning dataset. To encourage further research, we have made our codes and datasets publicly available on GitHub at: https://github.com/albertsun1/gpt3-pii-attacks