 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Unified Multi-Task Learning & Model Fusion for Efficient Language Model Guardrailing
Apr 29, 2025



The trend towards large language models (LLMs) for guardrailing against undesired behaviors is increasing and has shown promise for censoring user inputs. However, increased latency, memory consumption, hosting expenses and non-structured outputs can make their use prohibitive. In this work, we show that task-specific data generation can lead to fine-tuned classifiers that significantly outperform current state of the art (SoTA) while being orders of magnitude smaller. Secondly, we show that using a single model, \texttt{MultiTaskGuard}, that is pretrained on a large synthetically generated dataset with unique task instructions further improves generalization. Thirdly, our most performant models, \texttt{UniGuard}, are found using our proposed search-based model merging approach that finds an optimal set of parameters to combine single-policy models and multi-policy guardrail models. % On 7 public datasets and 4 guardrail benchmarks we created, our efficient guardrail classifiers improve over the best performing SoTA publicly available LLMs and 3$^{\text{rd}}$ party guardrail APIs in detecting unsafe and safe behaviors by an average F1 score improvement of \textbf{29.92} points over Aegis-LlamaGuard and \textbf{21.62} over \texttt{gpt-4o}, respectively. Lastly, our guardrail synthetic data generation process that uses custom task-specific guardrail poli
Know Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges
Mar 06, 2025



Large Language Model (LLM) based judges form the underpinnings of key safety evaluation processes such as offline benchmarking, automated red-teaming, and online guardrailing. This widespread requirement raises the crucial question: can we trust the evaluations of these evaluators? In this paper, we highlight two critical challenges that are typically overlooked: (i) evaluations in the wild where factors like prompt sensitivity and distribution shifts can affect performance and (ii) adversarial attacks that target the judge. We highlight the importance of these through a study of commonly used safety judges, showing that small changes such as the style of the model output can lead to jumps of up to 0.24 in the false negative rate on the same dataset, whereas adversarial attacks on the model generation can fool some judges into misclassifying 100% of harmful generations as safe ones. These findings reveal gaps in commonly used meta-evaluation benchmarks and weaknesses in the robustness of current LLM judges, indicating that low attack success under certain judges could create a false sense of security.
PrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
Jul 23, 2024

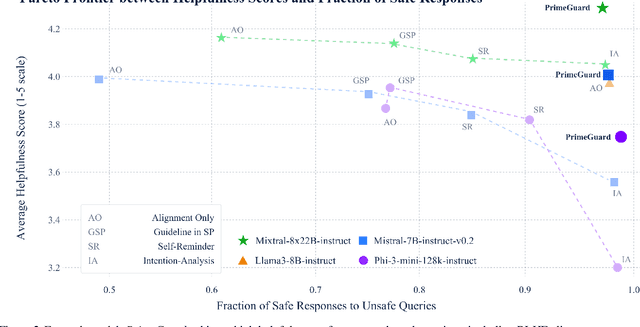

Deploying language models (LMs) necessitates outputs to be both high-quality and compliant with safety guidelines. Although Inference-Time Guardrails (ITG) offer solutions that shift model output distributions towards compliance, we find that current methods struggle in balancing safety with helpfulness. ITG Methods that safely address non-compliant queries exhibit lower helpfulness while those that prioritize helpfulness compromise on safety. We refer to this trade-off as the guardrail tax, analogous to the alignment tax. To address this, we propose PrimeGuard, a novel ITG method that utilizes structured control flow. PrimeGuard routes requests to different self-instantiations of the LM with varying instructions, leveraging its inherent instruction-following capabilities and in-context learning. Our tuning-free approach dynamically compiles system-designer guidelines for each query. We construct and release safe-eval, a diverse red-team safety benchmark. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, overcomes the guardrail tax by (1) significantly increasing resistance to iterative jailbreak attacks and (2) achieving state-of-the-art results in safety guardrailing while (3) matching helpfulness scores of alignment-tuned models. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, outperforms all competing baselines and overcomes the guardrail tax by improving the fraction of safe responses from 61% to 97% and increasing average helpfulness scores from 4.17 to 4.29 on the largest models, while reducing attack success rate from 100% to 8%. PrimeGuard implementation is available at https://github.com/dynamofl/PrimeGuard and safe-eval dataset is available at https://huggingface.co/datasets/dynamoai/safe_eval.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Navigating Data Heterogeneity in Federated Learning A Semi-Supervised Approach for Object Detection
Oct 27, 2023



Federated Learning (FL) has emerged as a potent framework for training models across distributed data sources while maintaining data privacy. Nevertheless, it faces challenges with limited high-quality labels and non-IID client data, particularly in applications like autonomous driving. To address these hurdles, we navigate the uncharted waters of Semi-Supervised Federated Object Detection (SSFOD). We present a pioneering SSFOD framework, designed for scenarios where labeled data reside only at the server while clients possess unlabeled data. Notably, our method represents the inaugural implementation of SSFOD for clients with 0% labeled non-IID data, a stark contrast to previous studies that maintain some subset of labels at each client. We propose FedSTO, a two-stage strategy encompassing Selective Training followed by Orthogonally enhanced full-parameter training, to effectively address data shift (e.g. weather conditions) between server and clients. Our contributions include selectively refining the backbone of the detector to avert overfitting, orthogonality regularization to boost representation divergence, and local EMA-driven pseudo label assignment to yield high-quality pseudo labels. Extensive validation on prominent autonomous driving datasets (BDD100K, Cityscapes, and SODA10M) attests to the efficacy of our approach, demonstrating state-of-the-art results. Remarkably, FedSTO, using just 20-30% of labels, performs nearly as well as fully-supervised centralized training methods.
Does fine-tuning GPT-3 with the OpenAI API leak personally-identifiable information?
Jul 31, 2023



Machine learning practitioners often fine-tune generative pre-trained models like GPT-3 to improve model performance at specific tasks. Previous works, however, suggest that fine-tuned machine learning models memorize and emit sensitive information from the original fine-tuning dataset. Companies such as OpenAI offer fine-tuning services for their models, but no prior work has conducted a memorization attack on any closed-source models. In this work, we simulate a privacy attack on GPT-3 using OpenAI's fine-tuning API. Our objective is to determine if personally identifiable information (PII) can be extracted from this model. We (1) explore the use of naive prompting methods on a GPT-3 fine-tuned classification model, and (2) we design a practical word generation task called Autocomplete to investigate the extent of PII memorization in fine-tuned GPT-3 within a real-world context. Our findings reveal that fine-tuning GPT3 for both tasks led to the model memorizing and disclosing critical personally identifiable information (PII) obtained from the underlying fine-tuning dataset. To encourage further research, we have made our codes and datasets publicly available on GitHub at: https://github.com/albertsun1/gpt3-pii-attacks
oneDNN Graph Compiler: A Hybrid Approach for High-Performance Deep Learning Compilation
Jan 03, 2023



With the rapid development of deep learning models and hardware support for dense computing, the deep learning (DL) workload characteristics changed significantly from a few hot spots on compute-intensive operations to a broad range of operations scattered across the models. Accelerating a few compute-intensive operations using the expert-tuned implementation of primitives does not fully exploit the performance potential of AI hardware. Various efforts are made to compile a full deep neural network (DNN) graph. One of the biggest challenges is to achieve end-to-end compilation by generating expert-level performance code for the dense compute-intensive operations and applying compilation optimization at the scope of DNN computation graph across multiple compute-intensive operations. We present oneDNN Graph Compiler, a tensor compiler that employs a hybrid approach of using techniques from both compiler optimization and expert-tuned kernels for high-performance code generation of the deep neural network graph. oneDNN Graph Compiler addresses unique optimization challenges in the deep learning domain, such as low-precision computation, aggressive fusion, optimization for static tensor shapes and memory layout, constant weight optimization, and memory buffer reuse. Experimental results demonstrate up to 2x performance gains over primitives-based optimization for performance-critical DNN computation graph patterns on Intel Xeon Scalable Processors.
TinyFedTL: Federated Transfer Learning on Tiny Devices
Oct 03, 2021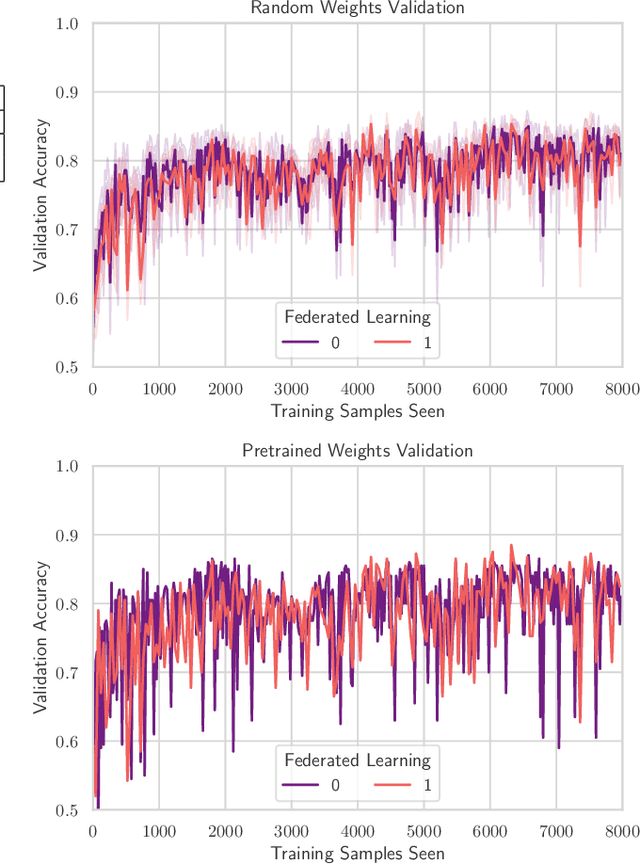
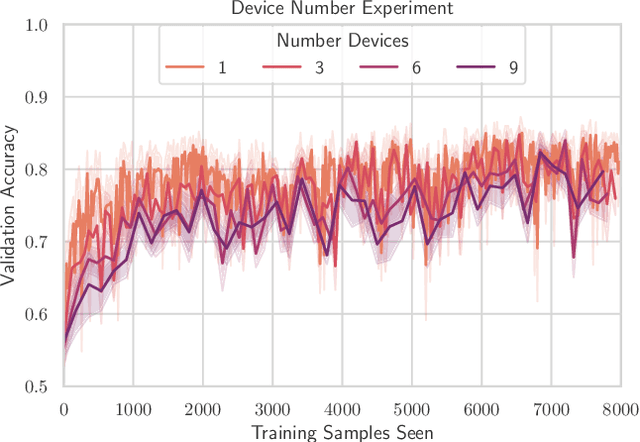
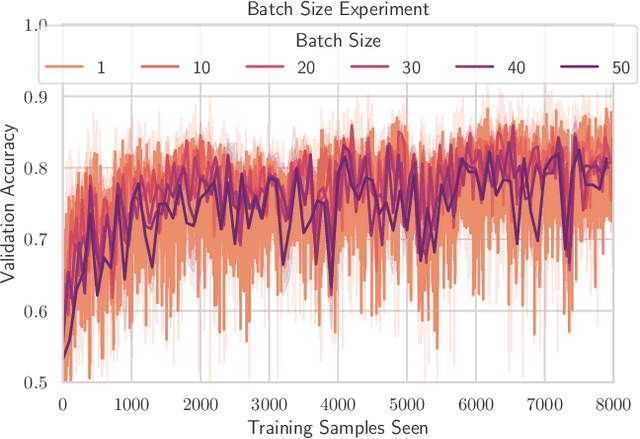
TinyML has rose to popularity in an era where data is everywhere. However, the data that is in most demand is subject to strict privacy and security guarantees. In addition, the deployment of TinyML hardware in the real world has significant memory and communication constraints that traditional ML fails to address. In light of these challenges, we present TinyFedTL, the first implementation of federated transfer learning on a resource-constrained microcontroller.
FedCD: Improving Performance in non-IID Federated Learning
Jun 22, 2020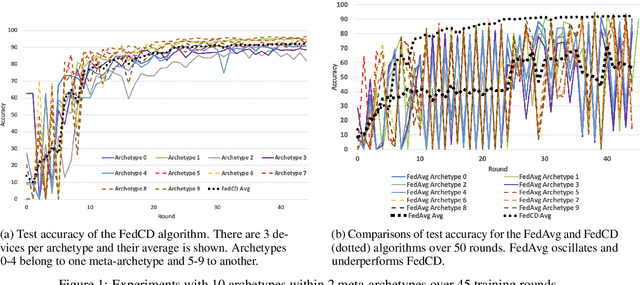
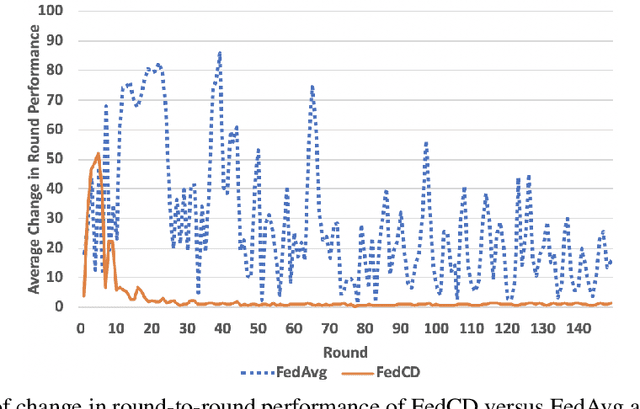
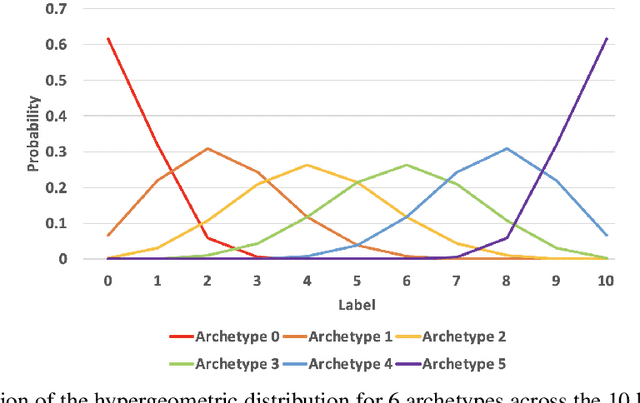
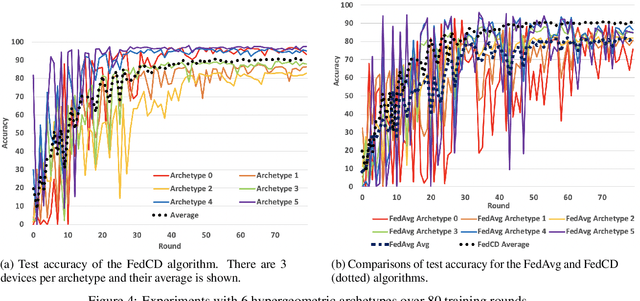
Federated learning has been widely applied to enable decentralized devices, which each have their own local data, to learn a shared model. However, learning from real-world data can be challenging, as it is rarely identically and independently distributed (IID) across edge devices (a key assumption for current high-performing and low-bandwidth algorithms). We present a novel approach, FedCD, which clones and deletes models to dynamically group devices with similar data. Experiments on the CIFAR-10 dataset show that FedCD achieves higher accuracy and faster convergence compared to a FedAvg baseline on non-IID data while incurring minimal computation, communication, and storage overheads.