 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimeGuard: Safe and Helpful LLMs through Tuning-Free Routing
Jul 23, 2024

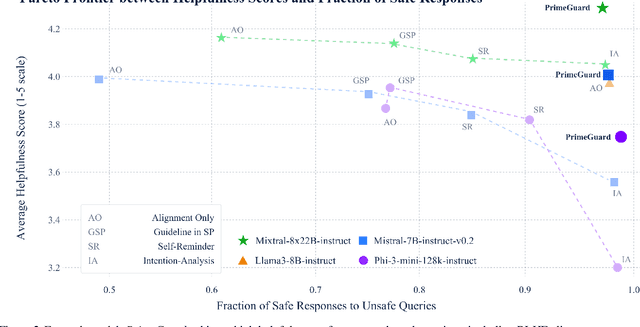

Deploying language models (LMs) necessitates outputs to be both high-quality and compliant with safety guidelines. Although Inference-Time Guardrails (ITG) offer solutions that shift model output distributions towards compliance, we find that current methods struggle in balancing safety with helpfulness. ITG Methods that safely address non-compliant queries exhibit lower helpfulness while those that prioritize helpfulness compromise on safety. We refer to this trade-off as the guardrail tax, analogous to the alignment tax. To address this, we propose PrimeGuard, a novel ITG method that utilizes structured control flow. PrimeGuard routes requests to different self-instantiations of the LM with varying instructions, leveraging its inherent instruction-following capabilities and in-context learning. Our tuning-free approach dynamically compiles system-designer guidelines for each query. We construct and release safe-eval, a diverse red-team safety benchmark. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, overcomes the guardrail tax by (1) significantly increasing resistance to iterative jailbreak attacks and (2) achieving state-of-the-art results in safety guardrailing while (3) matching helpfulness scores of alignment-tuned models. Extensive evaluations demonstrate that PrimeGuard, without fine-tuning, outperforms all competing baselines and overcomes the guardrail tax by improving the fraction of safe responses from 61% to 97% and increasing average helpfulness scores from 4.17 to 4.29 on the largest models, while reducing attack success rate from 100% to 8%. PrimeGuard implementation is available at https://github.com/dynamofl/PrimeGuard and safe-eval dataset is available at https://huggingface.co/datasets/dynamoai/safe_eval.
CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay
Feb 07, 2024



Large language models are increasingly solving tasks that are commonly believed to require human-level reasoning ability. However, these models still perform very poorly on benchmarks of general intelligence such as the Abstraction and Reasoning Corpus (ARC). In this paper, we approach ARC as a programming-by-examples problem, and introduce a novel and scalable method for language model self-improvement called Code Iteration (CodeIt). Our method iterates between 1) program sampling and hindsight relabeling, and 2) learning from prioritized experience replay. By relabeling the goal of an episode (i.e., the target program output given input) to the realized output produced by the sampled program, our method effectively deals with the extreme sparsity of rewards in program synthesis. Applying CodeIt to the ARC dataset, we demonstrate that prioritized hindsight replay, along with pre-training and data-augmentation, leads to successful inter-task generalization. CodeIt is the first neuro-symbolic approach that scales to the full ARC evaluation dataset. Our method solves 15% of ARC evaluation tasks, achieving state-of-the-art performance and outperforming existing neural and symbolic baselines.
Hierarchical Reinforcement Learning for Power Network Topology Control
Nov 03, 2023


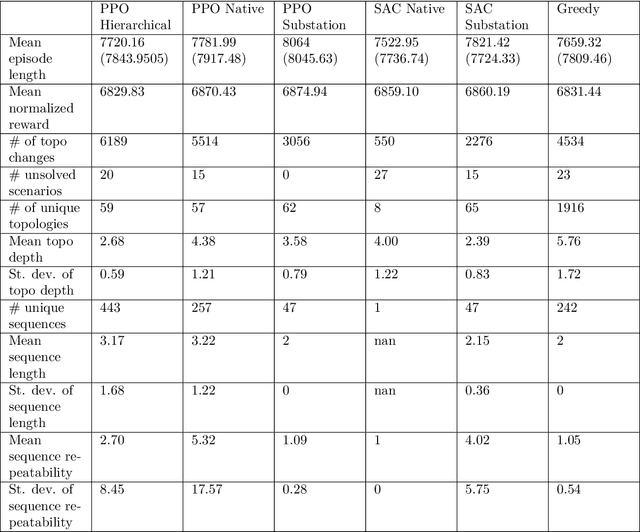
Learning in high-dimensional action spaces is a key challenge in applying reinforcement learning (RL) to real-world systems. In this paper, we study the possibility of controlling power networks using RL methods. Power networks are critical infrastructures that are complex to control. In particular, the combinatorial nature of the action space poses a challenge to both conventional optimizers and learned controllers. Hierarchical reinforcement learning (HRL) represents one approach to address this challenge. More precisely, a HRL framework for power network topology control is proposed. The HRL framework consists of three levels of action abstraction. At the highest level, there is the overall long-term task of power network operation, namely, keeping the power grid state within security constraints at all times, which is decomposed into two temporally extended actions: 'do nothing' versus 'propose a topology change'. At the intermediate level, the action space consists of all controllable substations. Finally, at the lowest level, the action space consists of all configurations of the chosen substation. By employing this HRL framework, several hierarchical power network agents are trained for the IEEE 14-bus network. Whereas at the highest level a purely rule-based policy is still chosen for all agents in this study, at the intermediate level the policy is trained using different state-of-the-art RL algorithms. At the lowest level, either an RL algorithm or a greedy algorithm is used. The performance of the different 3-level agents is compared with standard baseline (RL or greedy) approaches. A key finding is that the 3-level agent that employs RL both at the intermediate and the lowest level outperforms all other agents on the most difficult task. Our code is publicly available.