 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Program Synthesis with Neurally Interpreted Languages
Apr 20, 2026A central challenge in program induction has long been the trade-off between symbolic and neural approaches. Symbolic methods offer compositional generalisation and data efficiency, yet their scalability is constrained by formalisms such as domain-specific languages (DSLs), which are labour-intensive to create and may not transfer to new domains. In contrast, neural networks flexibly learn from data but tend to generalise poorly in compositional and out-of-distribution settings. We bridge this divide with an instance of a Latent Adaptation Network architecture named Neural Language Interpreter (NLI), which learns its own discrete, symbolic-like programming language end-to-end. NLI autonomously discovers a vocabulary of primitive operations and uses a novel differentiable neural executor to interpret variable-length sequences of these primitives. This allows NLI to represent programs that are not bound to a constant number of computation steps, enabling it to solve more complex problems than those seen during training. To make these discrete, compositional program structures amenable to gradient-based optimisation, we employ the Gumbel-Softmax relaxation, enabling the entire model to be trained end-to-end. Crucially, this same differentiability enables powerful test-time adaptation. At inference, NLI's program inductor provides an initial program guess. This guess is then refined via gradient descent through the neural executor, enabling efficient search for the neural program that best explains the given data. We demonstrate that NLI outperforms in-context learning, test-time training, and continuous latent program networks on tasks that require combinatorial generalisation and rapid adaptation to unseen tasks. Our results establish a new path toward models that combine the compositionality of discrete languages with the gradient-based search and end-to-end learning of neural networks.
The Unfairness of Multifactorial Bias in Recommendation
Jan 19, 2026Popularity bias and positivity bias are two prominent sources of bias in recommender systems. Both arise from input data, propagate through recommendation models, and lead to unfair or suboptimal outcomes. Popularity bias occurs when a small subset of items receives most interactions, while positivity bias stems from the over-representation of high rating values. Although each bias has been studied independently, their combined effect, to which we refer to as multifactorial bias, remains underexplored. In this work, we examine how multifactorial bias influences item-side fairness, focusing on exposure bias, which reflects the unequal visibility of items in recommendation outputs. Through simulation studies, we find that positivity bias is disproportionately concentrated on popular items, further amplifying their over-exposure. Motivated by this insight, we adapt a percentile-based rating transformation as a pre-processing strategy to mitigate multifactorial bias. Experiments using six recommendation algorithms across four public datasets show that this approach improves exposure fairness with negligible accuracy loss. We also demonstrate that integrating this pre-processing step into post-processing fairness pipelines enhances their effectiveness and efficiency, enabling comparable or better fairness with reduced computational cost. These findings highlight the importance of addressing multifactorial bias and demonstrate the practical value of simple, data-driven pre-processing methods for improving fairness in recommender systems.
Making Universal Policies Universal
Feb 20, 2025


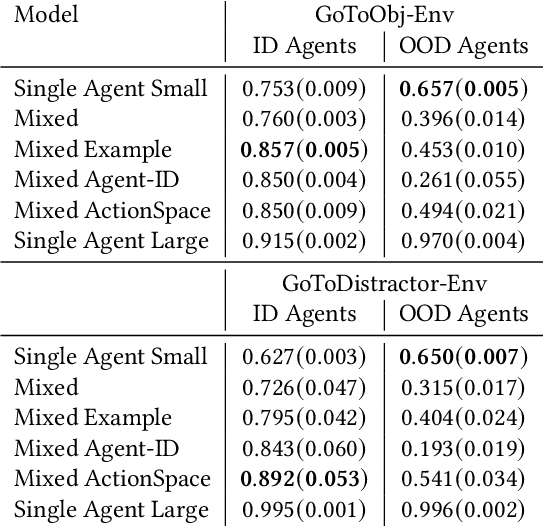
The development of a generalist agent capable of solving a wide range of sequential decision-making tasks remains a significant challenge. We address this problem in a cross-agent setup where agents share the same observation space but differ in their action spaces. Our approach builds on the universal policy framework, which decouples policy learning into two stages: a diffusion-based planner that generates observation sequences and an inverse dynamics model that assigns actions to these plans. We propose a method for training the planner on a joint dataset composed of trajectories from all agents. This method offers the benefit of positive transfer by pooling data from different agents, while the primary challenge lies in adapting shared plans to each agent's unique constraints. We evaluate our approach on the BabyAI environment, covering tasks of varying complexity, and demonstrate positive transfer across agents. Additionally, we examine the planner's generalisation ability to unseen agents and compare our method to traditional imitation learning approaches. By training on a pooled dataset from multiple agents, our universal policy achieves an improvement of up to $42.20\%$ in task completion accuracy compared to a policy trained on a dataset from a single agent.
Bridge the Inference Gaps of Neural Processes via Expectation Maximization
Jan 04, 2025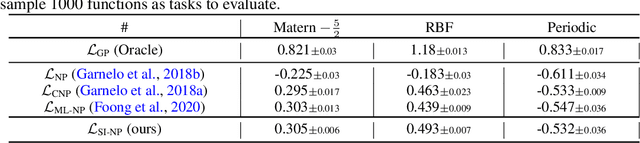
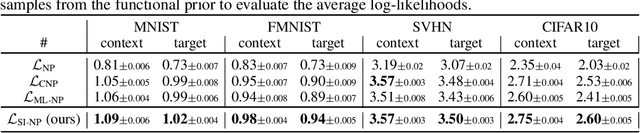

The neural process (NP) is a family of computationally efficient models for learning distributions over functions. However, it suffers from under-fitting and shows suboptimal performance in practice. Researchers have primarily focused on incorporating diverse structural inductive biases, \textit{e.g.} attention or convolution, in modeling. The topic of inference suboptimality and an analysis of the NP from the optimization objective perspective has hardly been studied in earlier work. To fix this issue, we propose a surrogate objective of the target log-likelihood of the meta dataset within the expectation maximization framework. The resulting model, referred to as the Self-normalized Importance weighted Neural Process (SI-NP), can learn a more accurate functional prior and has an improvement guarantee concerning the target log-likelihood. Experimental results show the competitive performance of SI-NP over other NPs objectives and illustrate that structural inductive biases, such as attention modules, can also augment our method to achieve SOTA performance. Our code is available at \url{https://github.com/hhq123gogogo/SI_NPs}.
Mitigating Exposure Bias in Online Learning to Rank Recommendation: A Novel Reward Model for Cascading Bandits
Aug 08, 2024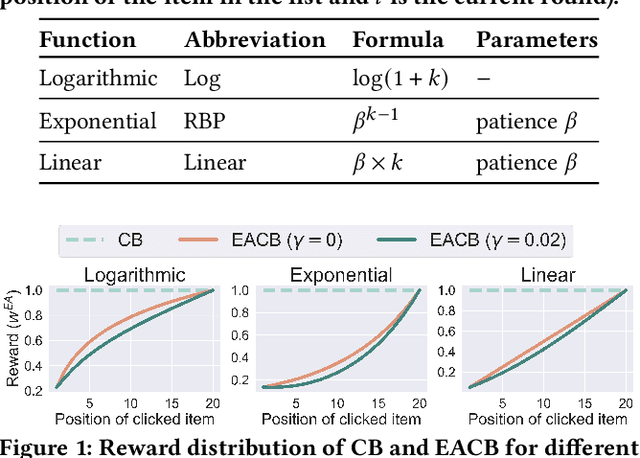

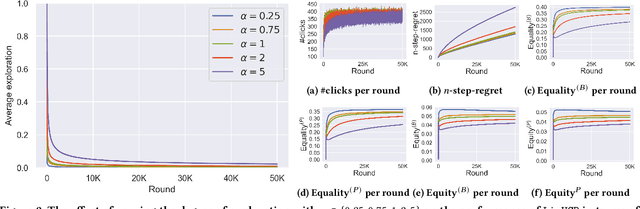
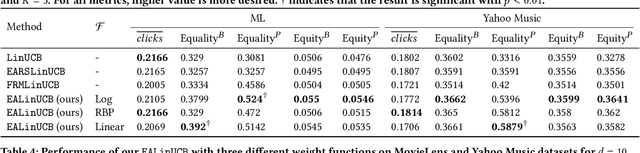
Exposure bias is a well-known issue in recommender systems where items and suppliers are not equally represented in the recommendation results. This bias becomes particularly problematic over time as a few items are repeatedly over-represented in recommendation lists, leading to a feedback loop that further amplifies this bias. Although extensive research has addressed this issue in model-based or neighborhood-based recommendation algorithms, less attention has been paid to online recommendation models, such as those based on top-K contextual bandits, where recommendation models are dynamically updated with ongoing user feedback. In this paper, we study exposure bias in a class of well-known contextual bandit algorithms known as Linear Cascading Bandits. We analyze these algorithms in their ability to handle exposure bias and provide a fair representation of items in the recommendation results. Our analysis reveals that these algorithms fail to mitigate exposure bias in the long run during the course of ongoing user interactions. We propose an Exposure-Aware reward model that updates the model parameters based on two factors: 1) implicit user feedback and 2) the position of the item in the recommendation list. The proposed model mitigates exposure bias by controlling the utility assigned to the items based on their exposure in the recommendation list. Our experiments with two real-world datasets show that our proposed reward model improves the exposure fairness of the linear cascading bandits over time while maintaining the recommendation accuracy. It also outperforms the current baselines. Finally, we prove a high probability upper regret bound for our proposed model, providing theoretical guarantees for its performance.
Going Beyond Popularity and Positivity Bias: Correcting for Multifactorial Bias in Recommender Systems
Apr 29, 2024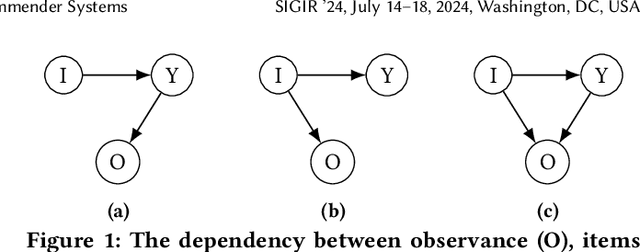
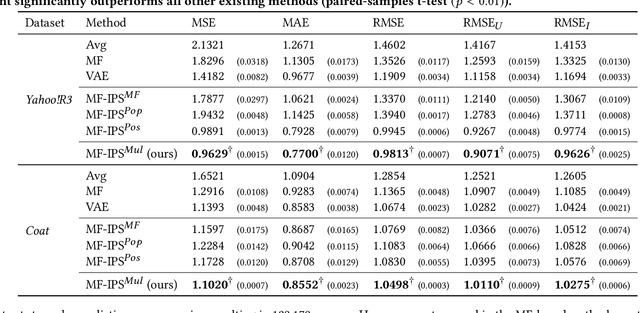
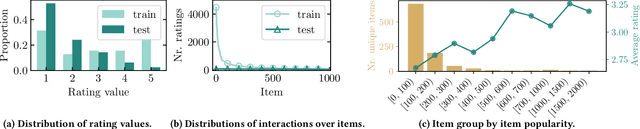
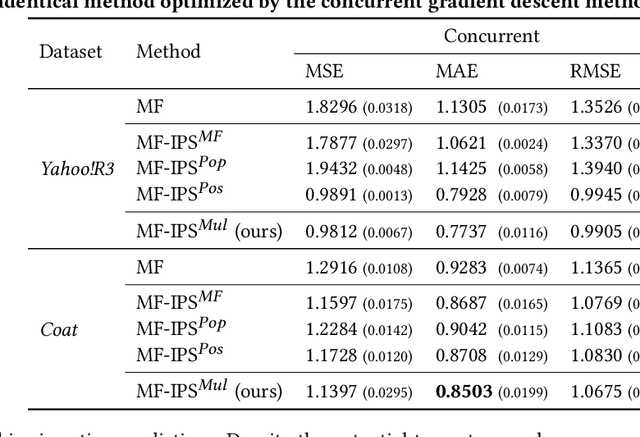
Two typical forms of bias in user interaction data with recommender systems (RSs) are popularity bias and positivity bias, which manifest themselves as the over-representation of interactions with popular items or items that users prefer, respectively. Debiasing methods aim to mitigate the effect of selection bias on the evaluation and optimization of RSs. However, existing debiasing methods only consider single-factor forms of bias, e.g., only the item (popularity) or only the rating value (positivity). This is in stark contrast with the real world where user selections are generally affected by multiple factors at once. In this work, we consider multifactorial selection bias in RSs. Our focus is on selection bias affected by both item and rating value factors, which is a generalization and combination of popularity and positivity bias. While the concept of multifactorial bias is intuitive, it brings a severe practical challenge as it requires substantially more data for accurate bias estimation. As a solution, we propose smoothing and alternating gradient descent techniques to reduce variance and improve the robustness of its optimization. Our experimental results reveal that, with our proposed techniques, multifactorial bias corrections are more effective and robust than single-factor counterparts on real-world and synthetic datasets.
Planning with a Learned Policy Basis to Optimally Solve Complex Tasks
Mar 22, 2024
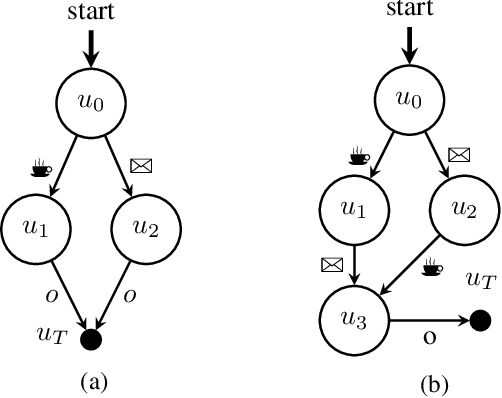
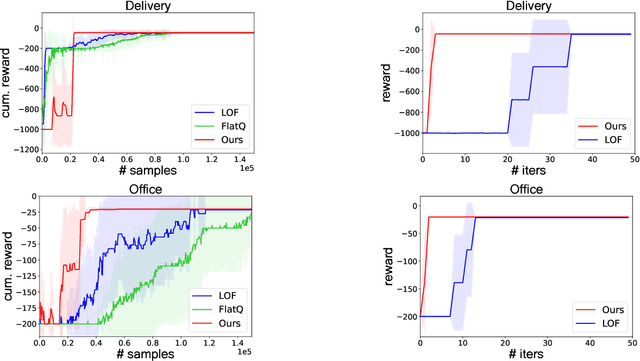
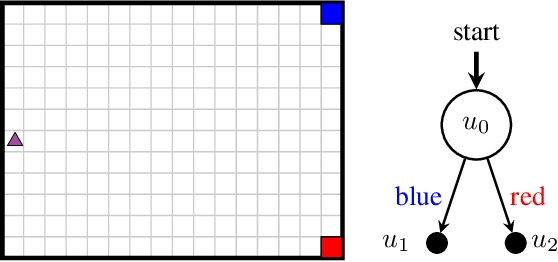
Conventional reinforcement learning (RL) methods can successfully solve a wide range of sequential decision problems. However, learning policies that can generalize predictably across multiple tasks in a setting with non-Markovian reward specifications is a challenging problem. We propose to use successor features to learn a policy basis so that each (sub)policy in it solves a well-defined subproblem. In a task described by a finite state automaton (FSA) that involves the same set of subproblems, the combination of these (sub)policies can then be used to generate an optimal solution without additional learning. In contrast to other methods that combine (sub)policies via planning, our method asymptotically attains global optimality, even in stochastic environments.
Hierarchical Reinforcement Learning for Power Network Topology Control
Nov 03, 2023


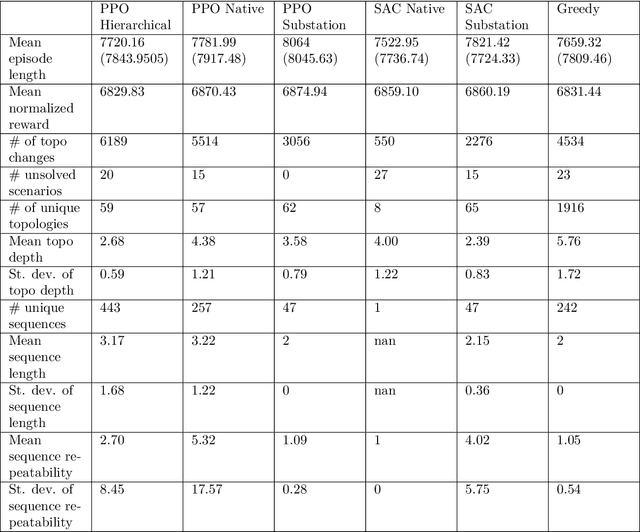
Learning in high-dimensional action spaces is a key challenge in applying reinforcement learning (RL) to real-world systems. In this paper, we study the possibility of controlling power networks using RL methods. Power networks are critical infrastructures that are complex to control. In particular, the combinatorial nature of the action space poses a challenge to both conventional optimizers and learned controllers. Hierarchical reinforcement learning (HRL) represents one approach to address this challenge. More precisely, a HRL framework for power network topology control is proposed. The HRL framework consists of three levels of action abstraction. At the highest level, there is the overall long-term task of power network operation, namely, keeping the power grid state within security constraints at all times, which is decomposed into two temporally extended actions: 'do nothing' versus 'propose a topology change'. At the intermediate level, the action space consists of all controllable substations. Finally, at the lowest level, the action space consists of all configurations of the chosen substation. By employing this HRL framework, several hierarchical power network agents are trained for the IEEE 14-bus network. Whereas at the highest level a purely rule-based policy is still chosen for all agents in this study, at the intermediate level the policy is trained using different state-of-the-art RL algorithms. At the lowest level, either an RL algorithm or a greedy algorithm is used. The performance of the different 3-level agents is compared with standard baseline (RL or greedy) approaches. A key finding is that the 3-level agent that employs RL both at the intermediate and the lowest level outperforms all other agents on the most difficult task. Our code is publicly available.
Learning Objective-Specific Active Learning Strategies with Attentive Neural Processes
Sep 11, 2023



Pool-based active learning (AL) is a promising technology for increasing data-efficiency of machine learning models. However, surveys show that performance of recent AL methods is very sensitive to the choice of dataset and training setting, making them unsuitable for general application. In order to tackle this problem, the field Learning Active Learning (LAL) suggests to learn the active learning strategy itself, allowing it to adapt to the given setting. In this work, we propose a novel LAL method for classification that exploits symmetry and independence properties of the active learning problem with an Attentive Conditional Neural Process model. Our approach is based on learning from a myopic oracle, which gives our model the ability to adapt to non-standard objectives, such as those that do not equally weight the error on all data points. We experimentally verify that our Neural Process model outperforms a variety of baselines in these settings. Finally, our experiments show that our model exhibits a tendency towards improved stability to changing datasets. However, performance is sensitive to choice of classifier and more work is necessary to reduce the performance the gap with the myopic oracle and to improve scalability. We present our work as a proof-of-concept for LAL on nonstandard objectives and hope our analysis and modelling considerations inspire future LAL work.
Uncoupled Learning of Differential Stackelberg Equilibria with Commitments
Feb 07, 2023A natural solution concept for many multiagent settings is the Stackelberg equilibrium, under which a ``leader'' agent selects a strategy that maximizes its own payoff assuming the ``follower'' chooses their best response to this strategy. Recent work has presented asymmetric learning updates that can be shown to converge to the \textit{differential} Stackelberg equilibria of two-player differentiable games. These updates are ``coupled'' in the sense that the leader requires some information about the follower's payoff function. Such coupled learning rules cannot be applied to \textit{ad hoc} interactive learning settings, and can be computationally impractical even in centralized training settings where the follower's payoffs are known. In this work, we present an ``uncoupled'' learning process under which each player's learning update only depends on their observations of the other's behavior. We prove that this process converges to a local Stackelberg equilibrium under similar conditions as previous coupled methods. We conclude with a discussion of the potential applications of our approach to human--AI cooperation and multi-agent reinforcement learning.