 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordination Graphs for Constrained Multi-Agent Reinforcement Learning
Jun 01, 2026Constrained Multi-agent reinforcement learning (CMARL) faces two intertwined challenges: the joint action space grows exponentially with the number of agents, and additional requirements couple agents in ways that reward structure alone does not capture. We introduce Coordination Graphs for Constrained Multi-Agent Reinforcement Learning (CG-CMARL), a framework that addresses both challenges by combining coordination graphs with Lagrangian duality. The system decomposes the joint problem into pairwise regions, each served by a set of shared Q-functions, one for the primary objective and one for each of the constraints, so that the number of learned models is independent of the number of agents. At execution time, Max-Sum message passing coordinates actions across the factor graph, while a Lagrangian multiplier controls the objective--constraint tradeoff, allowing a single trained model to trace a Pareto front without retraining. We provide convergence guarantees under mild conditions, together with a compositional error bound that decomposes into separate interpretable sources, each traceable to a specific design choice and independently controllable. Experiments on cooperative navigation tasks (where teams of up to 10 agents must coordinate to reach target positions while satisfying pairwise constraints) show that our method produces Pareto fronts dominating established baselines trained at fixed reward-shaping ratios, while scaling to team sizes where centralized approaches become intractable.
The Terminal Representation in Reinforcement Learning
May 29, 2026Representation learning is a powerful tool for spatio-temporal abstraction within reinforcement learning (RL). Two well established approaches are through the successor representation (SR) and the default representation (DR). The SR encodes states by the future trajectories they induce, capturing information flow decoupled from reward. The DR builds on this by weighting trajectories with reward, integrating credit-assignment structure into the representation. Eigenvectors of both representations have been used to support a range of downstream tasks -- including option discovery, reward shaping, transfer learning, and exploration. We introduce a structurally distinct formulation: the terminal representation (TR). The TR encodes reward-weighted trajectories similarly to the DR, but can be learned as a lower-dimensionality object, and can be used directly for the mentioned applications without eigenvector computations. Eigendecomposition also imposes the assumption of symmetric transition dynamics, which the TR can bypass. In this work we develop the theoretical foundations of the TR: its derivation, convergence of two learning algorithms, its use for zero-shot compositionality, and equivalences between alternative reward formulations. We further show the TR is embedded in the top DR eigenvector, allowing it to capture the same underlying knowledge without eigendecomposition. Additionally, we provide empirical evidence of the TR as a viable alternative to existing representations in subsidiary applications, while requiring less computational overhead to learn, store, and use.
Scalable Constrained Multi-Agent Reinforcement Learning via State Augmentation and Consensus for Separable Dynamics
May 28, 2026We present a distributed approach for constrained Multi-Agent Reinforcement Learning (MARL) that combines state-augmented policy learning with distributed consensus over dual variables. Our method targets systems where agents have separable dynamics but must coordinate to satisfy global resource constraints, a setting in which, as we demonstrate empirically, independent learning fails to produce feasible solutions because agents cannot determine appropriate individual contributions toward collective constraint satisfaction. The key technical contribution is showing that lightweight neighbor-to-neighbor consensus over Lagrange multipliers suffices for globally coordinated constraint enforcement while preserving the scalability of independent training. Each agent learns a single augmented policy offline, conditioned on both its local state and a dual variable encoding constraint feedback. During execution, agents reach agreement on this dual variable through local communication alone. We prove that under mild connectivity assumptions, the consensus error among agents' multipliers is bounded, and show that this translates to a bounded constraint violation that decreases with graph connectivity and the number of consensus rounds. Unlike centralized training with decentralized execution (CTDE) approaches, whose complexity grows at least quadratically with agent count, our method scales linearly in both training and execution. Experiments on smart grid demand response demonstrate that consensus coordination is \emph{essential for feasibility}: without it, agents satisfy grid capacity constraints only by indefinitely postponing demand, a degenerate non-solution. With consensus, agents converge to a shared dual variable and satisfy both grid constraints and demand fulfillment, scaling to thousands of agents while CTDE baselines are limited to dozens.
Sampling-guided exploration of active feature selection policies
Mar 16, 2026Determining the most appropriate features for machine learning predictive models is challenging regarding performance and feature acquisition costs. In particular, global feature choice is limited given that some features will only benefit a subset of instances. In previous work, we proposed a reinforcement learning approach to sequentially recommend which modality to acquire next to reach the best information/cost ratio, based on the instance-specific information already acquired. We formulated the problem as a Markov Decision Process where the state's dimensionality changes during the episode, avoiding data imputation, contrary to existing works. However, this only allowed processing a small number of features, as all possible combinations of features were considered. Here, we address these limitations with two contributions: 1) we expand our framework to larger datasets with a heuristic-based strategy that focuses on the most promising feature combinations, and 2) we introduce a post-fit regularisation strategy that reduces the number of different feature combinations, leading to compact sequences of decisions. We tested our method on four binary classification datasets (one involving high-dimensional variables), the largest of which had 56 features and 4500 samples. We obtained better performance than state-of-the-art methods, both in terms of accuracy and policy complexity.
Intermediate Results on the Complexity of STRIPS$_{1}^{1}$
Feb 09, 2026This paper is based on Bylander's results on the computational complexity of propositional STRIPS planning. He showed that when only ground literals are permitted, determining plan existence is PSPACE-complete even if operators are limited to two preconditions and two postconditions. While NP-hardness is settled, it is unknown whether propositional STRIPS with operators that only have one precondition and one effect is NP-complete. We shed light on the question whether this small solution hypothesis for STRIPS$^1_1$ is true, calling a SAT solver for small instances, introducing the literal graph, and mapping it to Petri nets.
Learning The Minimum Action Distance
Jun 10, 2025This paper presents a state representation framework for Markov decision processes (MDPs) that can be learned solely from state trajectories, requiring neither reward signals nor the actions executed by the agent. We propose learning the minimum action distance (MAD), defined as the minimum number of actions required to transition between states, as a fundamental metric that captures the underlying structure of an environment. MAD naturally enables critical downstream tasks such as goal-conditioned reinforcement learning and reward shaping by providing a dense, geometrically meaningful measure of progress. Our self-supervised learning approach constructs an embedding space where the distances between embedded state pairs correspond to their MAD, accommodating both symmetric and asymmetric approximations. We evaluate the framework on a comprehensive suite of environments with known MAD values, encompassing both deterministic and stochastic dynamics, as well as discrete and continuous state spaces, and environments with noisy observations. Empirical results demonstrate that the proposed approach not only efficiently learns accurate MAD representations across these diverse settings but also significantly outperforms existing state representation methods in terms of representation quality.
Distances for Markov chains from sample streams
May 23, 2025Bisimulation metrics are powerful tools for measuring similarities between stochastic processes, and specifically Markov chains. Recent advances have uncovered that bisimulation metrics are, in fact, optimal-transport distances, which has enabled the development of fast algorithms for computing such metrics with provable accuracy and runtime guarantees. However, these recent methods, as well as all previously known methods, assume full knowledge of the transition dynamics. This is often an impractical assumption in most real-world scenarios, where typically only sample trajectories are available. In this work, we propose a stochastic optimization method that addresses this limitation and estimates bisimulation metrics based on sample access, without requiring explicit transition models. Our approach is derived from a new linear programming (LP) formulation of bisimulation metrics, which we solve using a stochastic primal-dual optimization method. We provide theoretical guarantees on the sample complexity of the algorithm and validate its effectiveness through a series of empirical evaluations.
Provably Efficient Exploration in Reward Machines with Low Regret
Dec 26, 2024



We study reinforcement learning (RL) for decision processes with non-Markovian reward, in which high-level knowledge of the task in the form of reward machines is available to the learner. We consider probabilistic reward machines with initially unknown dynamics, and investigate RL under the average-reward criterion, where the learning performance is assessed through the notion of regret. Our main algorithmic contribution is a model-based RL algorithm for decision processes involving probabilistic reward machines that is capable of exploiting the structure induced by such machines. We further derive high-probability and non-asymptotic bounds on its regret and demonstrate the gain in terms of regret over existing algorithms that could be applied, but obliviously to the structure. We also present a regret lower bound for the studied setting. To the best of our knowledge, the proposed algorithm constitutes the first attempt to tailor and analyze regret specifically for RL with probabilistic reward machines.
Tractable Offline Learning of Regular Decision Processes
Sep 04, 2024



This work studies offline Reinforcement Learning (RL) in a class of non-Markovian environments called Regular Decision Processes (RDPs). In RDPs, the unknown dependency of future observations and rewards from the past interactions can be captured by some hidden finite-state automaton. For this reason, many RDP algorithms first reconstruct this unknown dependency using automata learning techniques. In this paper, we show that it is possible to overcome two strong limitations of previous offline RL algorithms for RDPs, notably RegORL. This can be accomplished via the introduction of two original techniques: the development of a new pseudometric based on formal languages, which removes a problematic dependency on $L_\infty^\mathsf{p}$-distinguishability parameters, and the adoption of Count-Min-Sketch (CMS), instead of naive counting. The former reduces the number of samples required in environments that are characterized by a low complexity in language-theoretic terms. The latter alleviates the memory requirements for long planning horizons. We derive the PAC sample complexity bounds associated to each of these techniques, and we validate the approach experimentally.
Hierarchical Average-Reward Linearly-solvable Markov Decision Processes
Jul 09, 2024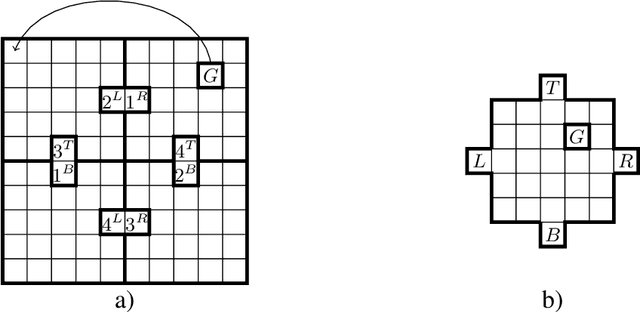
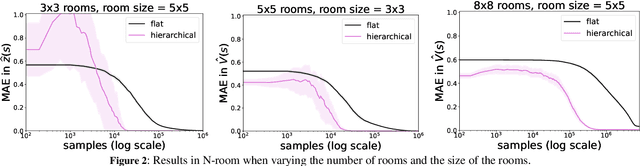
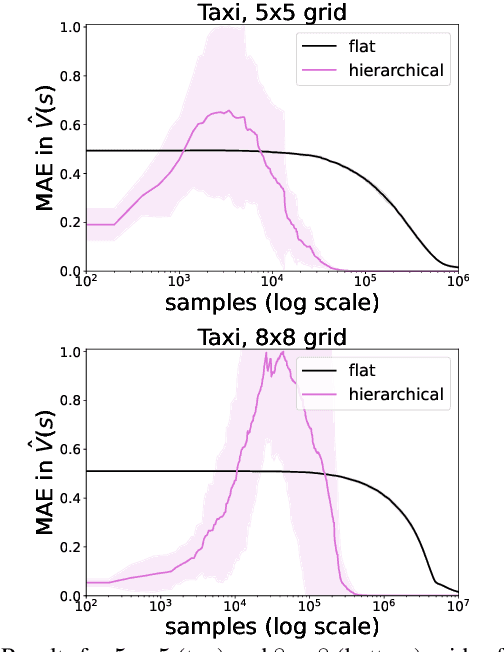
We introduce a novel approach to hierarchical reinforcement learning for Linearly-solvable Markov Decision Processes (LMDPs) in the infinite-horizon average-reward setting. Unlike previous work, our approach allows learning low-level and high-level tasks simultaneously, without imposing limiting restrictions on the low-level tasks. Our method relies on partitions of the state space that create smaller subtasks that are easier to solve, and the equivalence between such partitions to learn more efficiently. We then exploit the compositionality of low-level tasks to exactly represent the value function of the high-level task. Experiments show that our approach can outperform flat average-reward reinforcement learning by one or several orders of magnitude.