 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Fixed Tasks: Unsupervised Environment Design for Task-Level Pairs
Nov 16, 2025Training general agents to follow complex instructions (tasks) in intricate environments (levels) remains a core challenge in reinforcement learning. Random sampling of task-level pairs often produces unsolvable combinations, highlighting the need to co-design tasks and levels. While unsupervised environment design (UED) has proven effective at automatically designing level curricula, prior work has only considered a fixed task. We present ATLAS (Aligning Tasks and Levels for Autocurricula of Specifications), a novel method that generates joint autocurricula over tasks and levels. Our approach builds upon UED to automatically produce solvable yet challenging task-level pairs for policy training. To evaluate ATLAS and drive progress in the field, we introduce an evaluation suite that models tasks as reward machines in Minigrid levels. Experiments demonstrate that ATLAS vastly outperforms random sampling approaches, particularly when sampling solvable pairs is unlikely. We further show that mutations leveraging the structure of both tasks and levels accelerate convergence to performant policies.
$\texttt{FORM}$: Learning Expressive and Transferable First-Order Logic Reward Machines
Dec 31, 2024Reward machines (RMs) are an effective approach for addressing non-Markovian rewards in reinforcement learning (RL) through finite-state machines. Traditional RMs, which label edges with propositional logic formulae, inherit the limited expressivity of propositional logic. This limitation hinders the learnability and transferability of RMs since complex tasks will require numerous states and edges. To overcome these challenges, we propose First-Order Reward Machines ($\texttt{FORM}$s), which use first-order logic to label edges, resulting in more compact and transferable RMs. We introduce a novel method for $\textbf{learning}$ $\texttt{FORM}$s and a multi-agent formulation for $\textbf{exploiting}$ them and facilitate their transferability, where multiple agents collaboratively learn policies for a shared $\texttt{FORM}$. Our experimental results demonstrate the scalability of $\texttt{FORM}$s with respect to traditional RMs. Specifically, we show that $\texttt{FORM}$s can be effectively learnt for tasks where traditional RM learning approaches fail. We also show significant improvements in learning speed and task transferability thanks to the multi-agent learning framework and the abstraction provided by the first-order language.
Learning Robust Reward Machines from Noisy Labels
Aug 27, 2024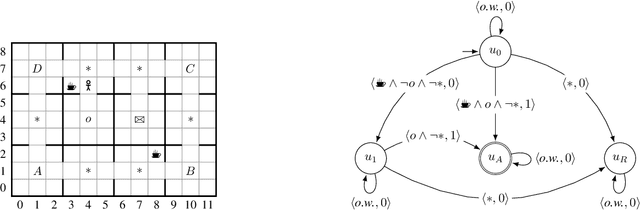
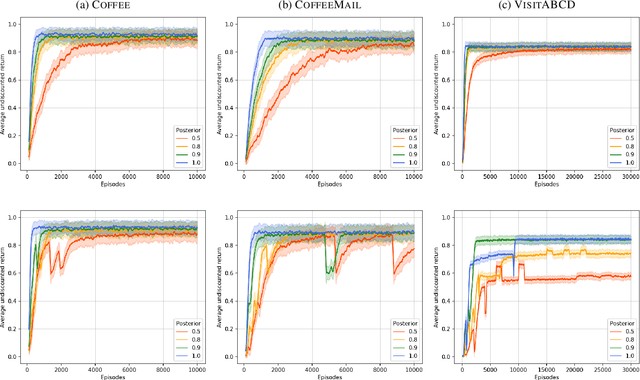
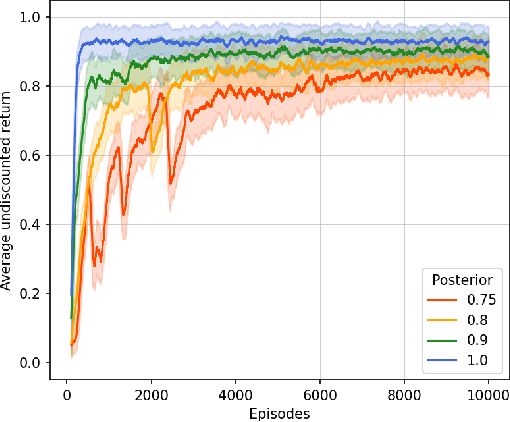
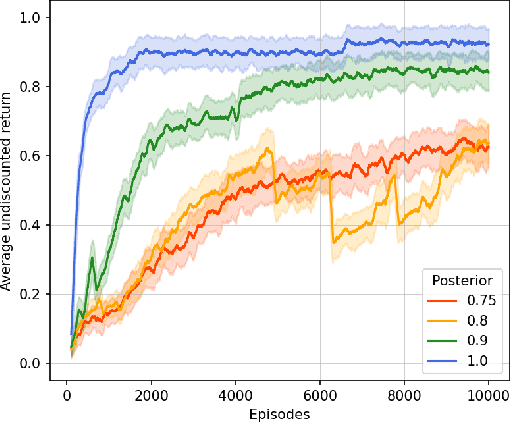
This paper presents PROB-IRM, an approach that learns robust reward machines (RMs) for reinforcement learning (RL) agents from noisy execution traces. The key aspect of RM-driven RL is the exploitation of a finite-state machine that decomposes the agent's task into different subtasks. PROB-IRM uses a state-of-the-art inductive logic programming framework robust to noisy examples to learn RMs from noisy traces using the Bayesian posterior degree of beliefs, thus ensuring robustness against inconsistencies. Pivotal for the results is the interleaving between RM learning and policy learning: a new RM is learned whenever the RL agent generates a trace that is believed not to be accepted by the current RM. To speed up the training of the RL agent, PROB-IRM employs a probabilistic formulation of reward shaping that uses the posterior Bayesian beliefs derived from the traces. Our experimental analysis shows that PROB-IRM can learn (potentially imperfect) RMs from noisy traces and exploit them to train an RL agent to solve its tasks successfully. Despite the complexity of learning the RM from noisy traces, agents trained with PROB-IRM perform comparably to agents provided with handcrafted RMs.
Jumanji: a Diverse Suite of Scalable Reinforcement Learning Environments in JAX
Jun 16, 2023Open-source reinforcement learning (RL) environments have played a crucial role in driving progress in the development of AI algorithms. In modern RL research, there is a need for simulated environments that are performant, scalable, and modular to enable their utilization in a wider range of potential real-world applications. Therefore, we present Jumanji, a suite of diverse RL environments specifically designed to be fast, flexible, and scalable. Jumanji provides a suite of environments focusing on combinatorial problems frequently encountered in industry, as well as challenging general decision-making tasks. By leveraging the efficiency of JAX and hardware accelerators like GPUs and TPUs, Jumanji enables rapid iteration of research ideas and large-scale experimentation, ultimately empowering more capable agents. Unlike existing RL environment suites, Jumanji is highly customizable, allowing users to tailor the initial state distribution and problem complexity to their needs. Furthermore, we provide actor-critic baselines for each environment, accompanied by preliminary findings on scaling and generalization scenarios. Jumanji aims to set a new standard for speed, adaptability, and scalability of RL environments.
Learning Reward Machines in Cooperative Multi-Agent Tasks
Mar 31, 2023This paper presents a novel approach to Multi-Agent Reinforcement Learning (MARL) that combines cooperative task decomposition with the learning of reward machines (RMs) encoding the structure of the sub-tasks. The proposed method helps deal with the non-Markovian nature of the rewards in partially observable environments and improves the interpretability of the learnt policies required to complete the cooperative task. The RMs associated with each sub-task are learnt in a decentralised manner and then used to guide the behaviour of each agent. By doing so, the complexity of a cooperative multi-agent problem is reduced, allowing for more effective learning. The results suggest that our approach is a promising direction for future research in MARL, especially in complex environments with large state spaces and multiple agents.
Population-Based Reinforcement Learning for Combinatorial Optimization
Oct 07, 2022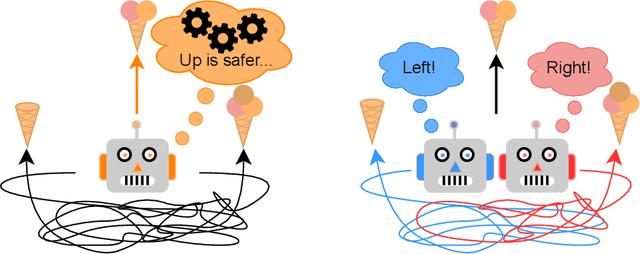

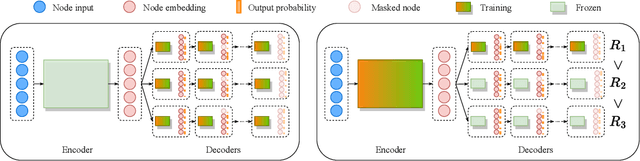
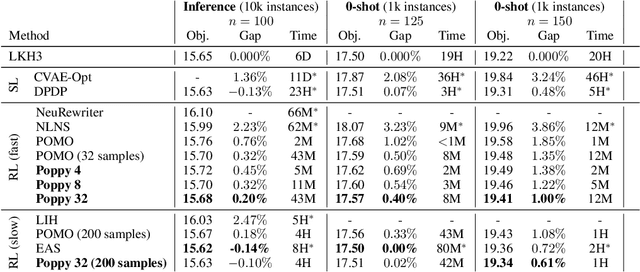
Applying reinforcement learning (RL) to combinatorial optimization problems is attractive as it removes the need for expert knowledge or pre-solved instances. However, it is unrealistic to expect an agent to solve these (often NP-)hard problems in a single shot at inference due to their inherent complexity. Thus, leading approaches often implement additional search strategies, from stochastic sampling and beam-search to explicit fine-tuning. In this paper, we argue for the benefits of learning a population of complementary policies, which can be simultaneously rolled out at inference. To this end, we introduce Poppy, a simple theoretically grounded training procedure for populations. Instead of relying on a predefined or hand-crafted notion of diversity, Poppy induces an unsupervised specialization targeted solely at maximizing the performance of the population. We show that Poppy produces a set of complementary policies, and obtains state-of-the-art RL results on three popular NP-hard problems: the traveling salesman (TSP), the capacitated vehicle routing (CVRP), and 0-1 knapsack (KP) problems. On TSP specifically, Poppy outperforms the previous state-of-the-art, dividing the optimality gap by 5 while reducing the inference time by more than an order of magnitude.
Hierarchies of Reward Machines
May 31, 2022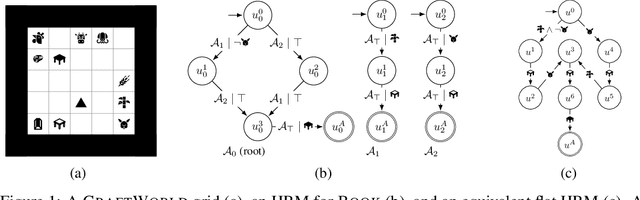


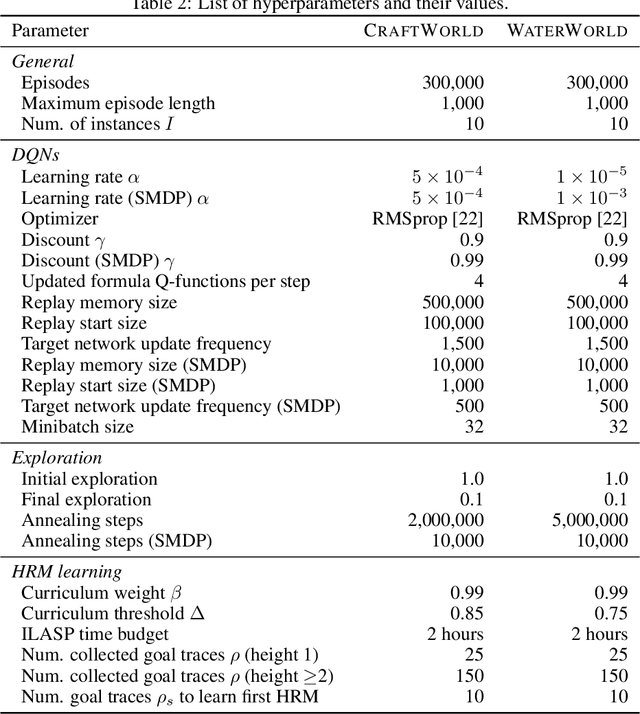
Reward machines (RMs) are a recent formalism for representing the reward function of a reinforcement learning task through a finite-state machine whose edges encode landmarks of the task using high-level events. The structure of RMs enables the decomposition of a task into simpler and independently solvable subtasks that help tackle long-horizon and/or sparse reward tasks. We propose a formalism for further abstracting the subtask structure by endowing an RM with the ability to call other RMs, thus composing a hierarchy of RMs (HRM). We exploit HRMs by treating each call to an RM as an independently solvable subtask using the options framework, and describe a curriculum-based method to induce HRMs from example traces observed by the agent. Our experiments reveal that exploiting a handcrafted HRM leads to faster convergence than with a flat HRM, and that learning an HRM is more scalable than learning an equivalent flat HRM.
Induction and Exploitation of Subgoal Automata for Reinforcement Learning
Sep 08, 2020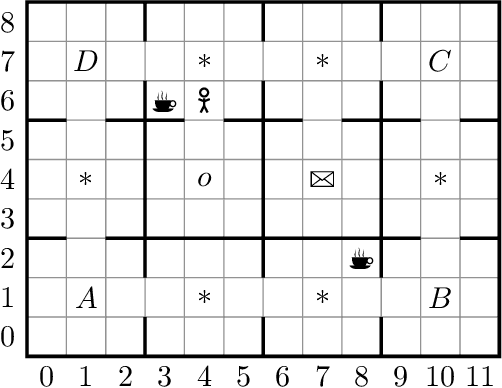
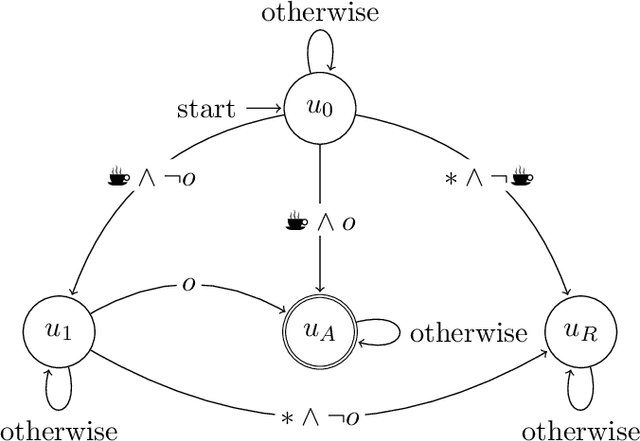

In this paper we present ISA, an approach for learning and exploiting subgoals in episodic reinforcement learning (RL) tasks. ISA interleaves reinforcement learning with the induction of a subgoal automaton, an automaton whose edges are labeled by the task's subgoals expressed as propositional logic formulas over a set of high-level events. A subgoal automaton also consists of two special states: a state indicating the successful completion of the task, and a state indicating that the task has finished without succeeding. A state-of-the-art inductive logic programming system is used to learn a subgoal automaton that covers the traces of high-level events observed by the RL agent. When the currently exploited automaton does not correctly recognize a trace, the automaton learner induces a new automaton that covers that trace. The interleaving process guarantees the induction of automata with the minimum number of states, and applies a symmetry breaking mechanism to shrink the search space whilst remaining complete. We evaluate ISA in several grid-world and continuous state space problems using different RL algorithms that leverage the automaton structures. We provide an in-depth empirical analysis of the automaton learning process performance in terms of the traces, the symmetric breaking and specific restrictions imposed on the final learnable automaton. For each class of RL problem, we show that the learned automata can be successfully exploited to learn policies that reach the goal, achieving an average reward comparable to the case where automata are not learned but handcrafted and given beforehand.
Induction of Subgoal Automata for Reinforcement Learning
Nov 29, 2019

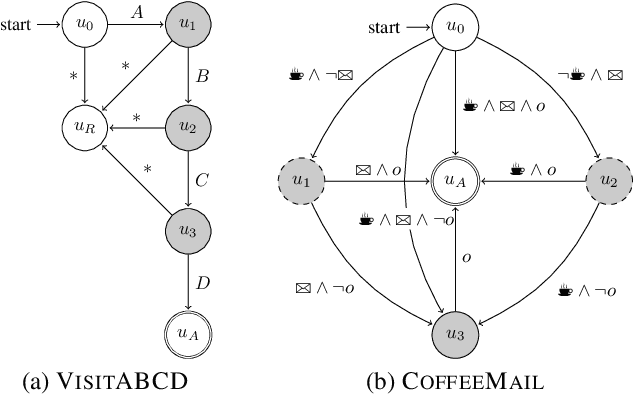
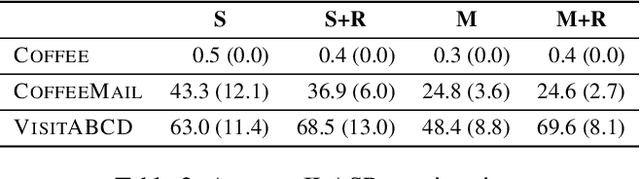
In this work we present ISA, a novel approach for learning and exploiting subgoals in reinforcement learning (RL). Our method relies on inducing an automaton whose transitions are subgoals expressed as propositional formulas over a set of observable events. A state-of-the-art inductive logic programming system is used to learn the automaton from observation traces perceived by the RL agent. The reinforcement learning and automaton learning processes are interleaved: a new refined automaton is learned whenever the RL agent generates a trace not recognized by the current automaton. We evaluate ISA in several gridworld problems and show that it performs similarly to a method for which automata are given in advance. We also show that the learned automata can be exploited to speed up convergence through reward shaping and transfer learning across multiple tasks. Finally, we analyze the running time and the number of traces that ISA needs to learn an automata, and the impact that the number of observable events has on the learner's performance.
Solving Multiagent Planning Problems with Concurrent Conditional Effects
Jun 19, 2019
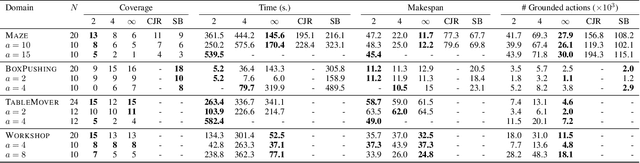
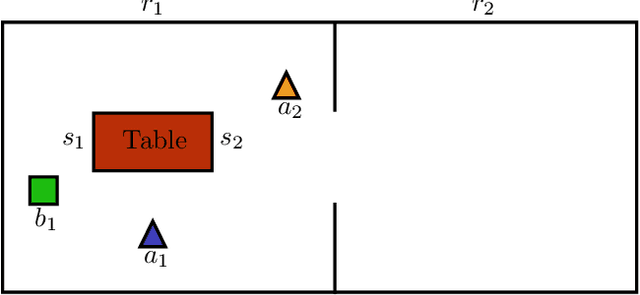
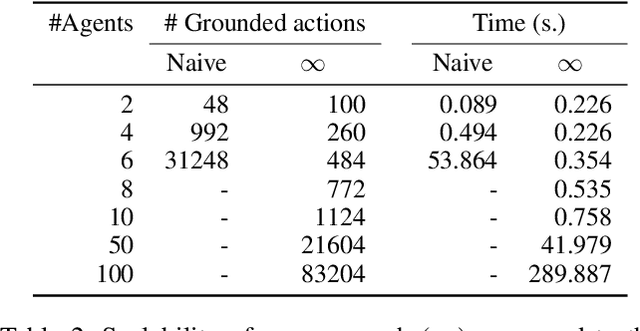
In this work we present a novel approach to solving concurrent multiagent planning problems in which several agents act in parallel. Our approach relies on a compilation from concurrent multiagent planning to classical planning, allowing us to use an off-the-shelf classical planner to solve the original multiagent problem. The solution can be directly interpreted as a concurrent plan that satisfies a given set of concurrency constraints, while avoiding the exponential blowup associated with concurrent actions. Our planner is the first to handle action effects that are conditional on what other agents are doing. Theoretically, we show that the compilation is sound and complete. Empirically, we show that our compilation can solve challenging multiagent planning problems that require concurrent actions.