 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Reward Machines from Noisy Labels
Aug 27, 2024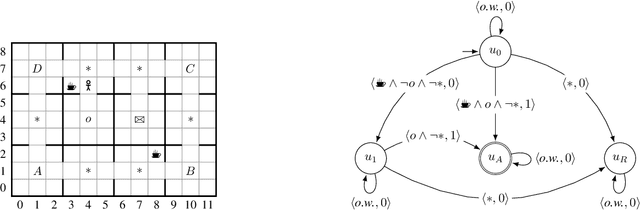
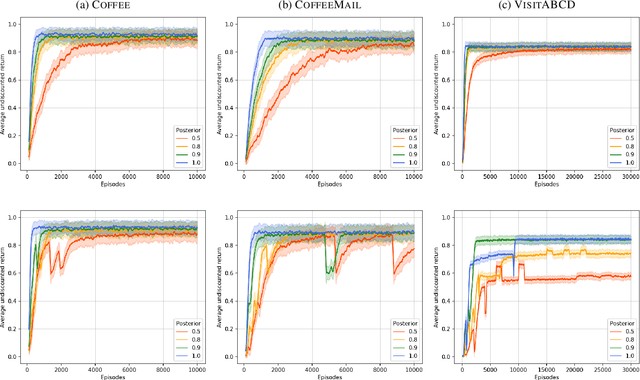
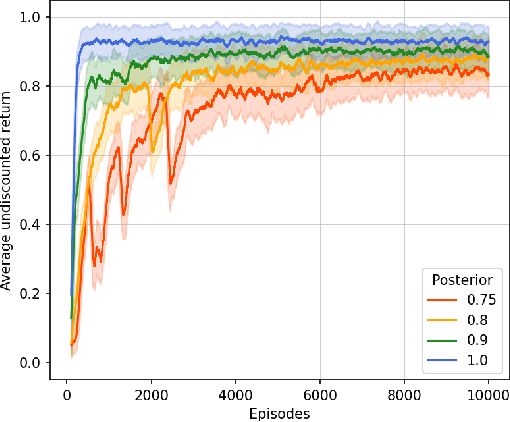
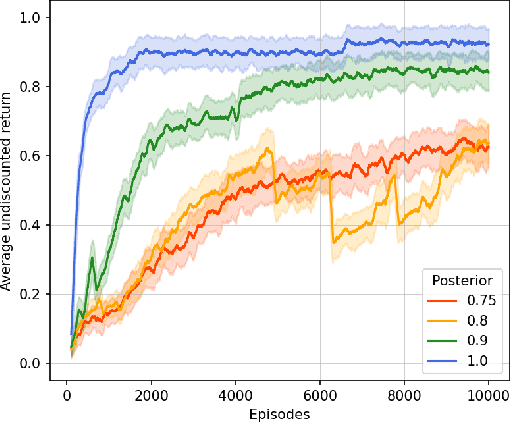
This paper presents PROB-IRM, an approach that learns robust reward machines (RMs) for reinforcement learning (RL) agents from noisy execution traces. The key aspect of RM-driven RL is the exploitation of a finite-state machine that decomposes the agent's task into different subtasks. PROB-IRM uses a state-of-the-art inductive logic programming framework robust to noisy examples to learn RMs from noisy traces using the Bayesian posterior degree of beliefs, thus ensuring robustness against inconsistencies. Pivotal for the results is the interleaving between RM learning and policy learning: a new RM is learned whenever the RL agent generates a trace that is believed not to be accepted by the current RM. To speed up the training of the RL agent, PROB-IRM employs a probabilistic formulation of reward shaping that uses the posterior Bayesian beliefs derived from the traces. Our experimental analysis shows that PROB-IRM can learn (potentially imperfect) RMs from noisy traces and exploit them to train an RL agent to solve its tasks successfully. Despite the complexity of learning the RM from noisy traces, agents trained with PROB-IRM perform comparably to agents provided with handcrafted RMs.
Adversarial Attacks to Reward Machine-based Reinforcement Learning
Nov 15, 2023



In recent years, Reward Machines (RMs) have stood out as a simple yet effective automata-based formalism for exposing and exploiting task structure in reinforcement learning settings. Despite their relevance, little to no attention has been directed to the study of their security implications and robustness to adversarial scenarios, likely due to their recent appearance in the literature. With my thesis, I aim to provide the first analysis of the security of RM-based reinforcement learning techniques, with the hope of motivating further research in the field, and I propose and evaluate a novel class of attacks on RM-based techniques: blinding attacks.
Assessing the Robustness of Intelligence-Driven Reinforcement Learning
Nov 15, 2023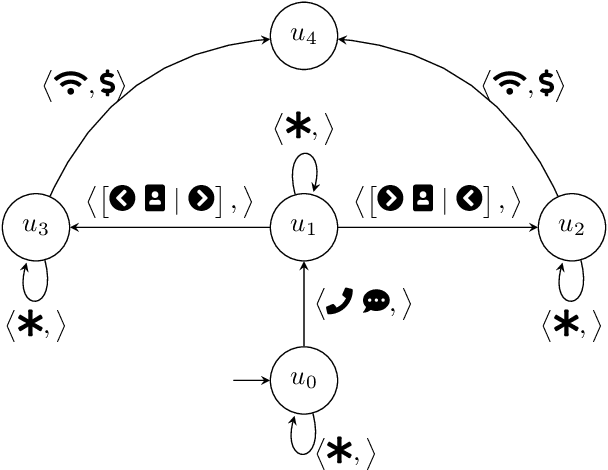
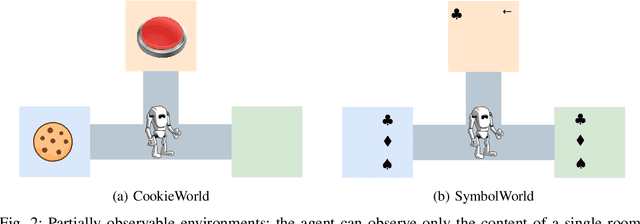
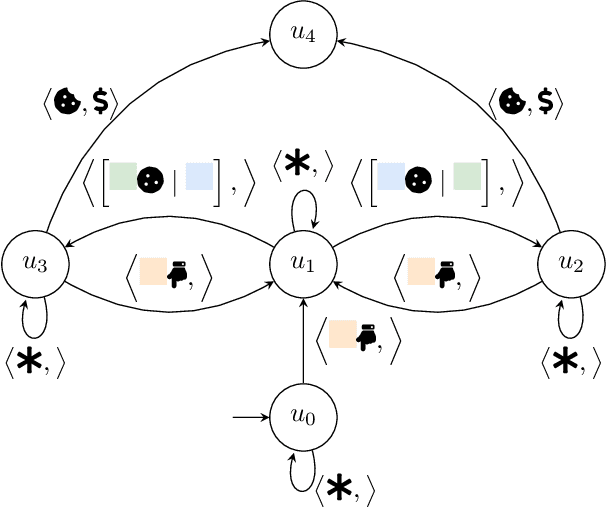
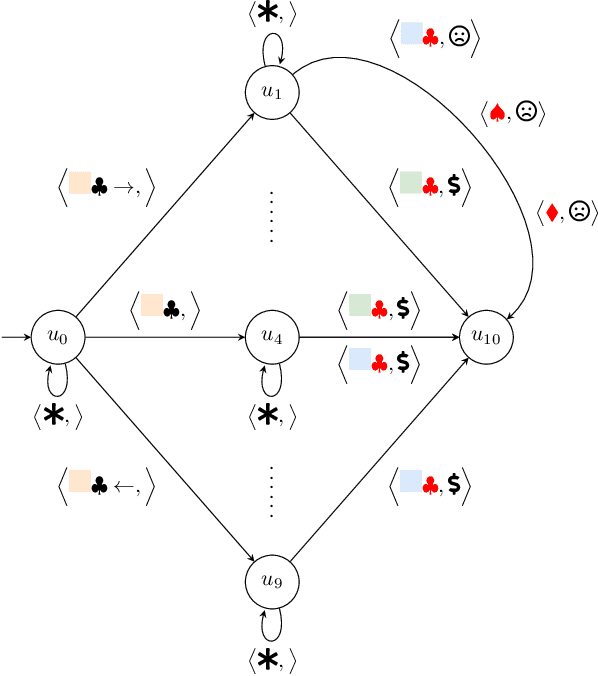
Robustness to noise is of utmost importance in reinforcement learning systems, particularly in military contexts where high stakes and uncertain environments prevail. Noise and uncertainty are inherent features of military operations, arising from factors such as incomplete information, adversarial actions, or unpredictable battlefield conditions. In RL, noise can critically impact decision-making, mission success, and the safety of personnel. Reward machines offer a powerful tool to express complex reward structures in RL tasks, enabling the design of tailored reinforcement signals that align with mission objectives. This paper considers the problem of the robustness of intelligence-driven reinforcement learning based on reward machines. The preliminary results presented suggest the need for further research in evidential reasoning and learning to harden current state-of-the-art reinforcement learning approaches before being mission-critical-ready.