 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-informed Decoding: Adaptive Information-Driven Branching
May 10, 2026Large language models (LLMs) achieve remarkable generative performance, yet their output quality is dependent on the decoding strategy. While sampling-based methods (e.g., top-k, nucleus) and search-and-select based methods (e.g., beam search, best-of-n, majority voting) can improve upon greedy decoding, both approaches suffer from limitations: sampling generally commits to a single path, while search often expends excessive computation regardless of task complexity. To address these, we introduce Entropy-informed decoding (EDEN), a plug-and-play, model-agnostic decoding framework that adaptively allocates computation based on the model's own uncertainty, approximating higher-width beam search with fewer expansions. At each generation step, EDEN estimates the entropy of the output token distribution and adjusts the branching factor monotonically with the entropy, expanding more candidates in high-entropy regions and following a greedier path in low-entropy regions, improving token efficiency. Experiments across complex tasks, including mathematical reasoning, code generation, and scientific questions, demonstrate that EDEN consistently improves output quality over existing decoding strategies, achieving better accuracy-expansion trade-offs than fixed-width beam search. By treating next-token selection as a noisy maximisation problem, we prove that branching factors monotone in entropy are guaranteed to find better (i.e. more probable) continuations than any fixed branching factor within the same total expansion budget, and derive explicit regret rates characterising the benefit of the adaptive allocation.
Learning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
ADAGE: A generic two-layer framework for adaptive agent based modelling
Jan 16, 2025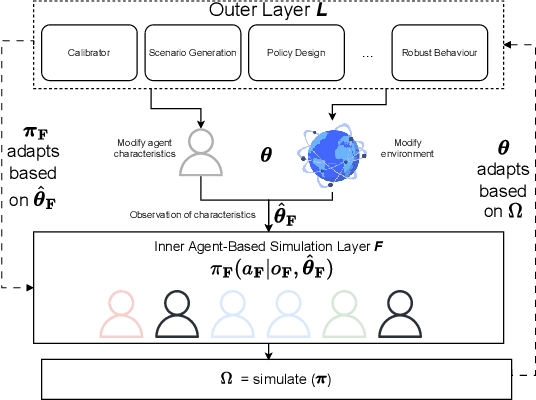

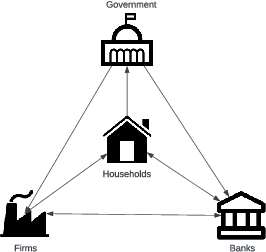

Agent-based models (ABMs) are valuable for modelling complex, potentially out-of-equilibria scenarios. However, ABMs have long suffered from the Lucas critique, stating that agent behaviour should adapt to environmental changes. Furthermore, the environment itself often adapts to these behavioural changes, creating a complex bi-level adaptation problem. Recent progress integrating multi-agent reinforcement learning into ABMs introduces adaptive agent behaviour, beginning to address the first part of this critique, however, the approaches are still relatively ad hoc, lacking a general formulation, and furthermore, do not tackle the second aspect of simultaneously adapting environmental level characteristics in addition to the agent behaviours. In this work, we develop a generic two-layer framework for ADaptive AGEnt based modelling (ADAGE) for addressing these problems. This framework formalises the bi-level problem as a Stackelberg game with conditional behavioural policies, providing a consolidated framework for adaptive agent-based modelling based on solving a coupled set of non-linear equations. We demonstrate how this generic approach encapsulates several common (previously viewed as distinct) ABM tasks, such as policy design, calibration, scenario generation, and robust behavioural learning under one unified framework. We provide example simulations on multiple complex economic and financial environments, showing the strength of the novel framework under these canonical settings, addressing long-standing critiques of traditional ABMs.
$\texttt{FORM}$: Learning Expressive and Transferable First-Order Logic Reward Machines
Dec 31, 2024Reward machines (RMs) are an effective approach for addressing non-Markovian rewards in reinforcement learning (RL) through finite-state machines. Traditional RMs, which label edges with propositional logic formulae, inherit the limited expressivity of propositional logic. This limitation hinders the learnability and transferability of RMs since complex tasks will require numerous states and edges. To overcome these challenges, we propose First-Order Reward Machines ($\texttt{FORM}$s), which use first-order logic to label edges, resulting in more compact and transferable RMs. We introduce a novel method for $\textbf{learning}$ $\texttt{FORM}$s and a multi-agent formulation for $\textbf{exploiting}$ them and facilitate their transferability, where multiple agents collaboratively learn policies for a shared $\texttt{FORM}$. Our experimental results demonstrate the scalability of $\texttt{FORM}$s with respect to traditional RMs. Specifically, we show that $\texttt{FORM}$s can be effectively learnt for tasks where traditional RM learning approaches fail. We also show significant improvements in learning speed and task transferability thanks to the multi-agent learning framework and the abstraction provided by the first-order language.
Simulate and Optimise: A two-layer mortgage simulator for designing novel mortgage assistance products
Nov 01, 2024



We develop a novel two-layer approach for optimising mortgage relief products through a simulated multi-agent mortgage environment. While the approach is generic, here the environment is calibrated to the US mortgage market based on publicly available census data and regulatory guidelines. Through the simulation layer, we assess the resilience of households to exogenous income shocks, while the optimisation layer explores strategies to improve the robustness of households to these shocks by making novel mortgage assistance products available to households. Households in the simulation are adaptive, learning to make mortgage-related decisions (such as product enrolment or strategic foreclosures) that maximize their utility, balancing their available liquidity and equity. We show how this novel two-layer simulation approach can successfully design novel mortgage assistance products to improve household resilience to exogenous shocks, and balance the costs of providing such products through post-hoc analysis. Previously, such analysis could only be conducted through expensive pilot studies involving real participants, demonstrating the benefit of the approach for designing and evaluating financial products.
Learning Robust Reward Machines from Noisy Labels
Aug 27, 2024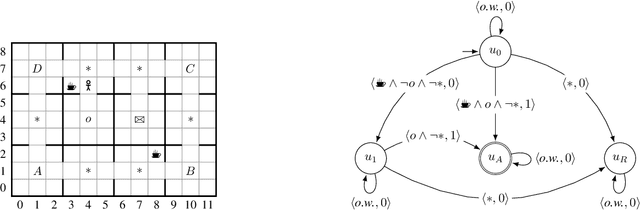
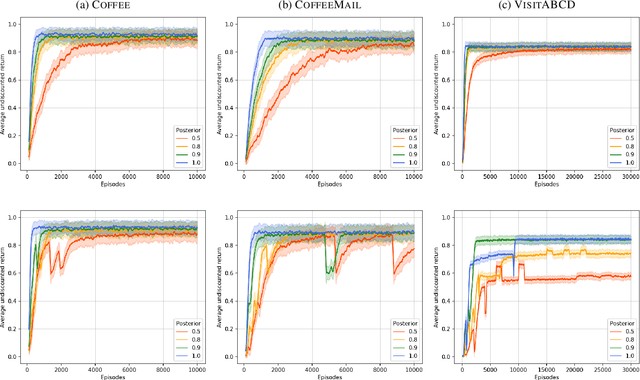
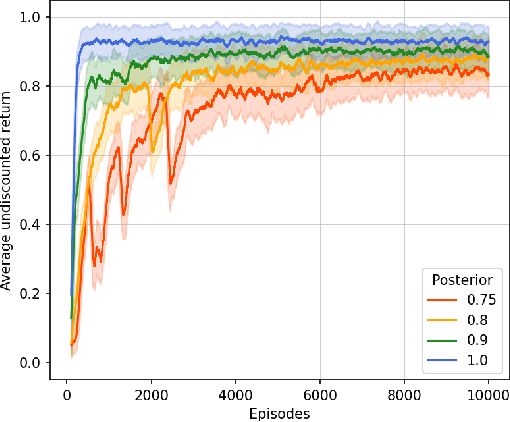
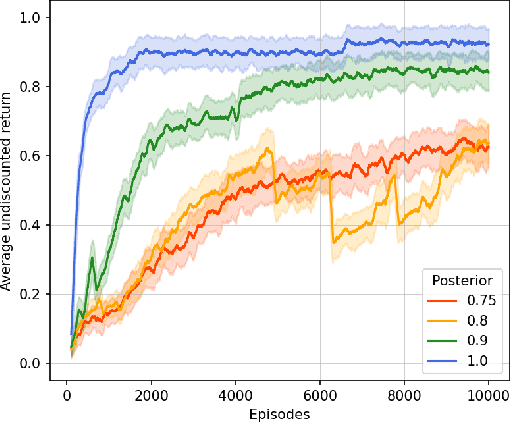
This paper presents PROB-IRM, an approach that learns robust reward machines (RMs) for reinforcement learning (RL) agents from noisy execution traces. The key aspect of RM-driven RL is the exploitation of a finite-state machine that decomposes the agent's task into different subtasks. PROB-IRM uses a state-of-the-art inductive logic programming framework robust to noisy examples to learn RMs from noisy traces using the Bayesian posterior degree of beliefs, thus ensuring robustness against inconsistencies. Pivotal for the results is the interleaving between RM learning and policy learning: a new RM is learned whenever the RL agent generates a trace that is believed not to be accepted by the current RM. To speed up the training of the RL agent, PROB-IRM employs a probabilistic formulation of reward shaping that uses the posterior Bayesian beliefs derived from the traces. Our experimental analysis shows that PROB-IRM can learn (potentially imperfect) RMs from noisy traces and exploit them to train an RL agent to solve its tasks successfully. Despite the complexity of learning the RM from noisy traces, agents trained with PROB-IRM perform comparably to agents provided with handcrafted RMs.
On the Sample Efficiency of Abstractions and Potential-Based Reward Shaping in Reinforcement Learning
Apr 11, 2024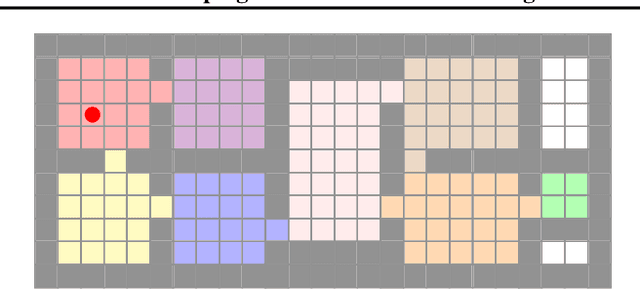
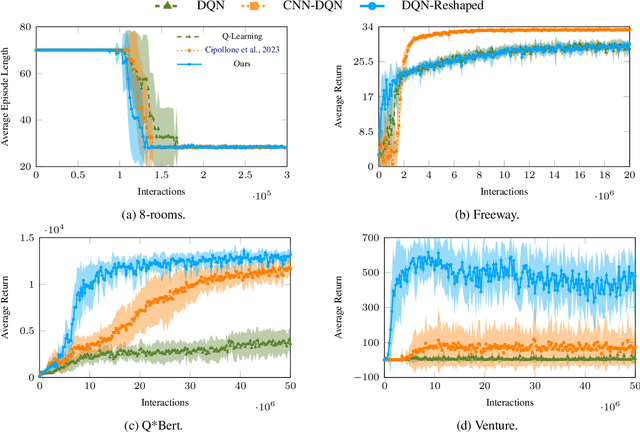
The use of Potential Based Reward Shaping (PBRS) has shown great promise in the ongoing research effort to tackle sample inefficiency in Reinforcement Learning (RL). However, the choice of the potential function is critical for this technique to be effective. Additionally, RL techniques are usually constrained to use a finite horizon for computational limitations. This introduces a bias when using PBRS, thus adding an additional layer of complexity. In this paper, we leverage abstractions to automatically produce a "good" potential function. We analyse the bias induced by finite horizons in the context of PBRS producing novel insights. Finally, to asses sample efficiency and performance impact, we evaluate our approach on four environments including a goal-oriented navigation task and three Arcade Learning Environments (ALE) games demonstrating that we can reach the same level of performance as CNN-based solutions with a simple fully-connected network.
Learning Reward Machines in Cooperative Multi-Agent Tasks
Mar 31, 2023This paper presents a novel approach to Multi-Agent Reinforcement Learning (MARL) that combines cooperative task decomposition with the learning of reward machines (RMs) encoding the structure of the sub-tasks. The proposed method helps deal with the non-Markovian nature of the rewards in partially observable environments and improves the interpretability of the learnt policies required to complete the cooperative task. The RMs associated with each sub-task are learnt in a decentralised manner and then used to guide the behaviour of each agent. By doing so, the complexity of a cooperative multi-agent problem is reduced, allowing for more effective learning. The results suggest that our approach is a promising direction for future research in MARL, especially in complex environments with large state spaces and multiple agents.
Inapplicable Actions Learning for Knowledge Transfer in Reinforcement Learning
Nov 28, 2022



Reinforcement Learning (RL) algorithms are known to scale poorly to environments with many available actions, requiring numerous samples to learn an optimal policy. The traditional approach of considering the same fixed action space in every possible state implies that the agent must understand, while also learning to maximize its reward, to ignore irrelevant actions such as $\textit{inapplicable actions}$ (i.e. actions that have no effect on the environment when performed in a given state). Knowing this information can help reduce the sample complexity of RL algorithms by masking the inapplicable actions from the policy distribution to only explore actions relevant to finding an optimal policy. This is typically done in an ad-hoc manner with hand-crafted domain logic added to the RL algorithm. In this paper, we propose a more systematic approach to introduce this knowledge into the algorithm. We (i) standardize the way knowledge can be manually specified to the agent; and (ii) present a new framework to autonomously learn these state-dependent action constraints jointly with the policy. We show experimentally that learning inapplicable actions greatly improves the sample efficiency of the algorithm by providing a reliable signal to mask out irrelevant actions. Moreover, we demonstrate that thanks to the transferability of the knowledge acquired, it can be reused in other tasks to make the learning process more efficient.
Towards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022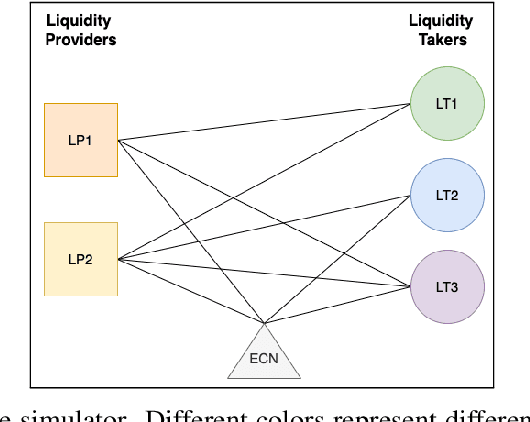

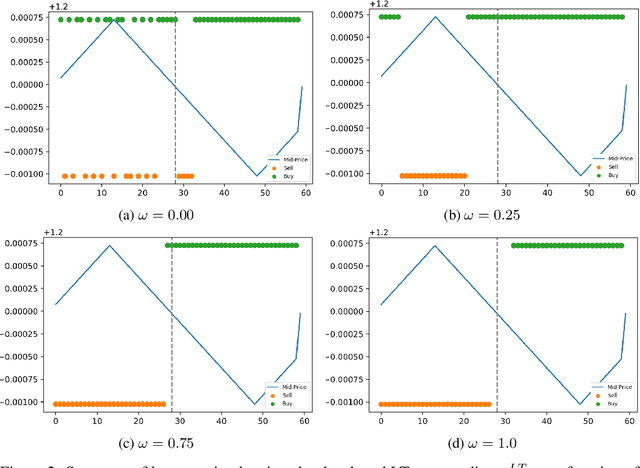

We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.