 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022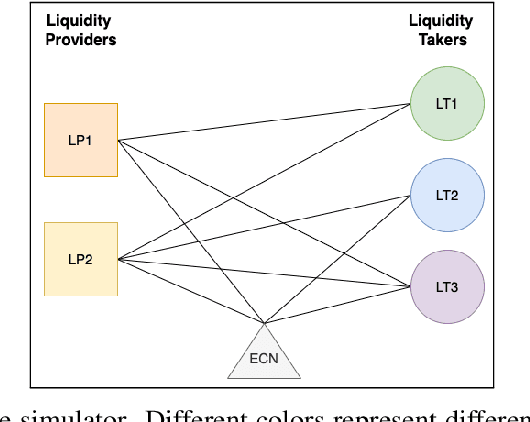

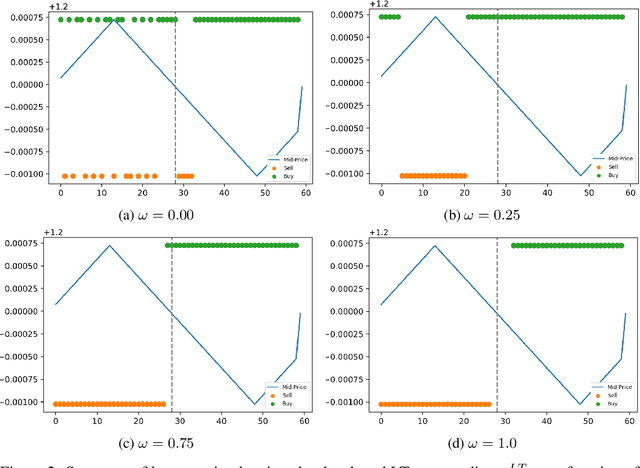

We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.
Reductive MDPs: A Perspective Beyond Temporal Horizons
May 15, 2022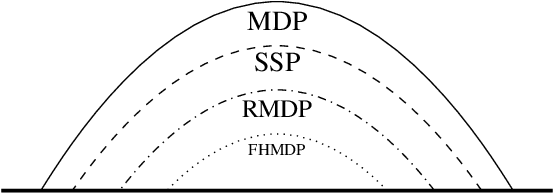
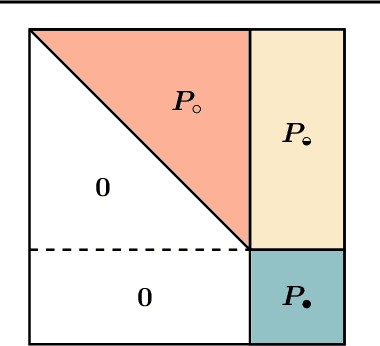
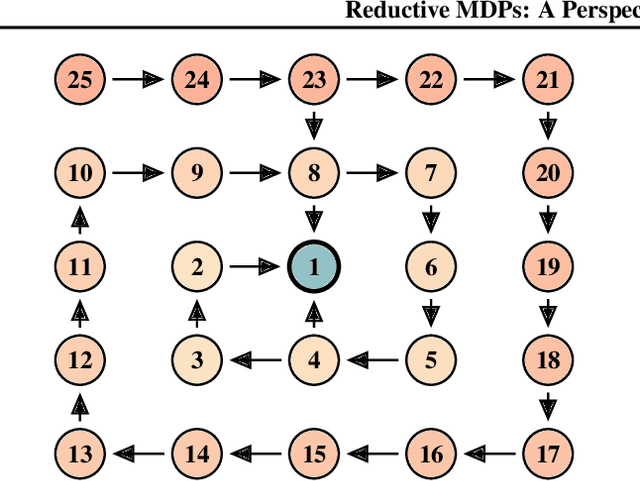
Solving general Markov decision processes (MDPs) is a computationally hard problem. Solving finite-horizon MDPs, on the other hand, is highly tractable with well known polynomial-time algorithms. What drives this extreme disparity, and do problems exist that lie between these diametrically opposed complexities? In this paper we identify and analyse a sub-class of stochastic shortest path problems (SSPs) for general state-action spaces whose dynamics satisfy a particular drift condition. This construction generalises the traditional, temporal notion of a horizon via decreasing reachability: a property called reductivity. It is shown that optimal policies can be recovered in polynomial-time for reductive SSPs -- via an extension of backwards induction -- with an efficient analogue in reductive MDPs. The practical considerations of the proposed approach are discussed, and numerical verification provided on a canonical optimal liquidation problem.
Towards a fully RL-based Market Simulator
Nov 08, 2021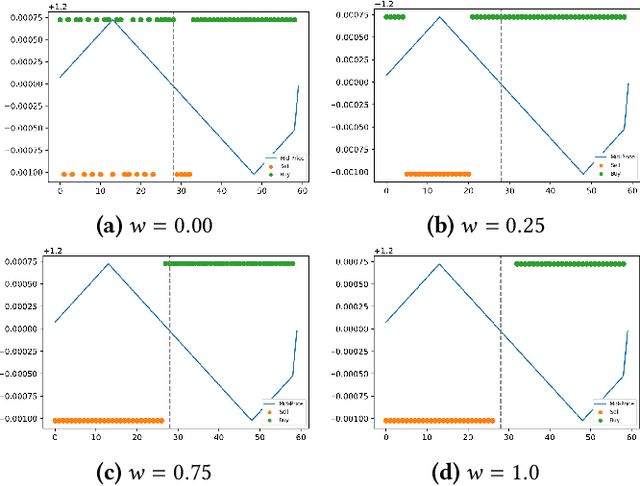
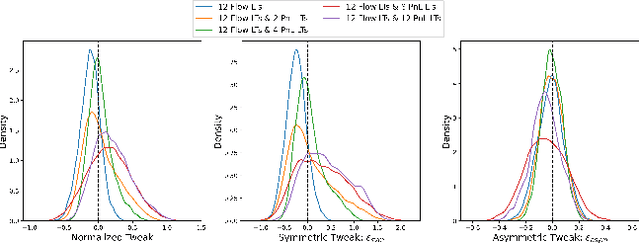
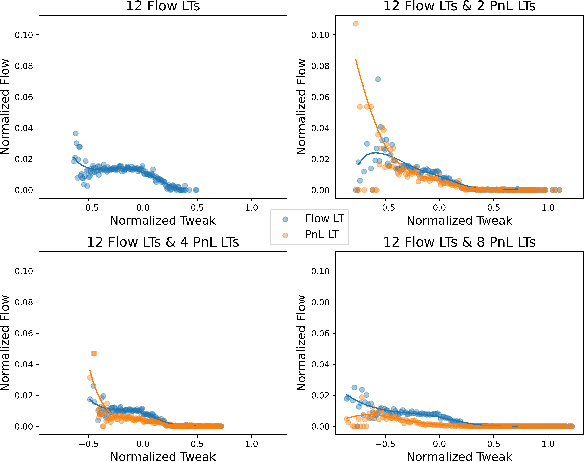
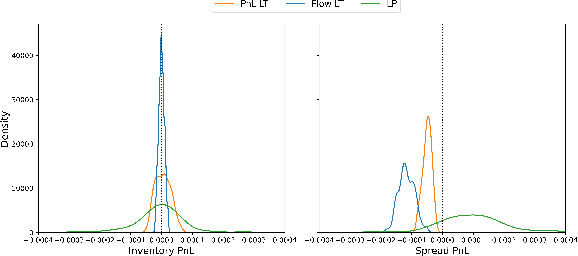
We present a new financial framework where two families of RL-based agents representing the Liquidity Providers and Liquidity Takers learn simultaneously to satisfy their objective. Thanks to a parametrized reward formulation and the use of Deep RL, each group learns a shared policy able to generalize and interpolate over a wide range of behaviors. This is a step towards a fully RL-based market simulator replicating complex market conditions particularly suited to study the dynamics of the financial market under various scenarios.
Graph Reasoning with Context-Aware Linearization for Interpretable Fact Extraction and Verification
Sep 25, 2021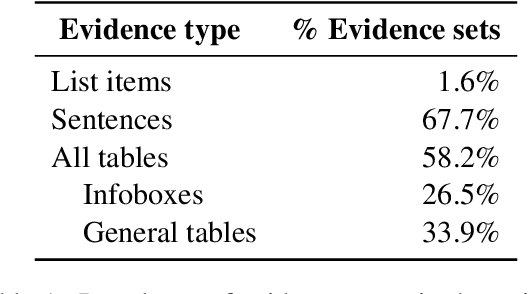
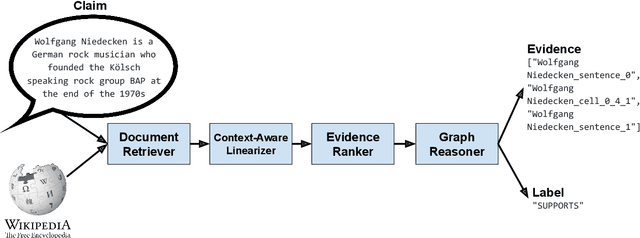

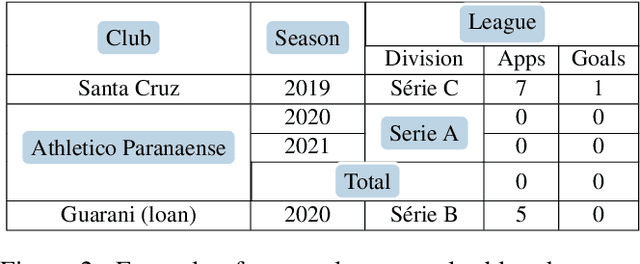
This paper presents an end-to-end system for fact extraction and verification using textual and tabular evidence, the performance of which we demonstrate on the FEVEROUS dataset. We experiment with both a multi-task learning paradigm to jointly train a graph attention network for both the task of evidence extraction and veracity prediction, as well as a single objective graph model for solely learning veracity prediction and separate evidence extraction. In both instances, we employ a framework for per-cell linearization of tabular evidence, thus allowing us to treat evidence from tables as sequences. The templates we employ for linearizing tables capture the context as well as the content of table data. We furthermore provide a case study to show the interpretability our approach. Our best performing system achieves a FEVEROUS score of 0.23 and 53% label accuracy on the blind test data.
Counterfactual Explanations for Arbitrary Regression Models
Jun 29, 2021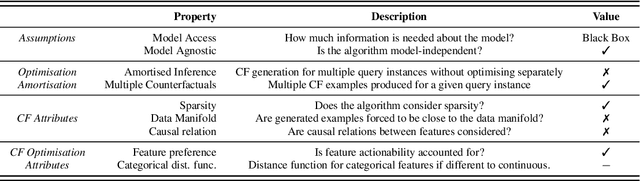
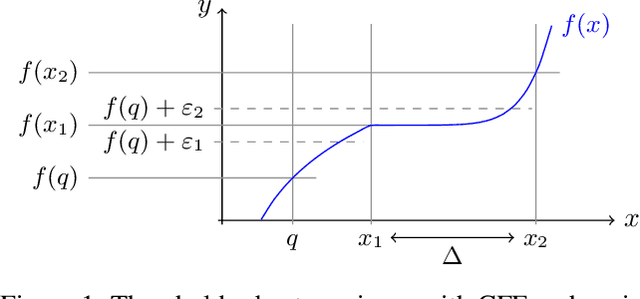
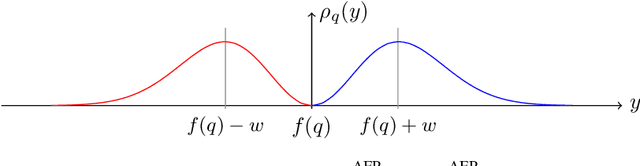
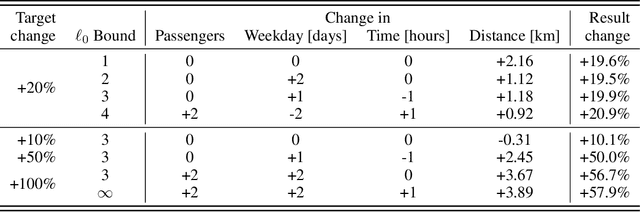
We present a new method for counterfactual explanations (CFEs) based on Bayesian optimisation that applies to both classification and regression models. Our method is a globally convergent search algorithm with support for arbitrary regression models and constraints like feature sparsity and actionable recourse, and furthermore can answer multiple counterfactual questions in parallel while learning from previous queries. We formulate CFE search for regression models in a rigorous mathematical framework using differentiable potentials, which resolves robustness issues in threshold-based objectives. We prove that in this framework, (a) verifying the existence of counterfactuals is NP-complete; and (b) that finding instances using such potentials is CLS-complete. We describe a unified algorithm for CFEs using a specialised acquisition function that composes both expected improvement and an exponential-polynomial (EP) family with desirable properties. Our evaluation on real-world benchmark domains demonstrate high sample-efficiency and precision.
Consensus Multiplicative Weights Update: Learning to Learn using Projector-based Game Signatures
Jun 04, 2021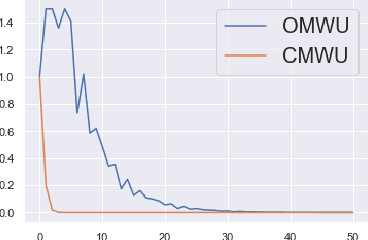

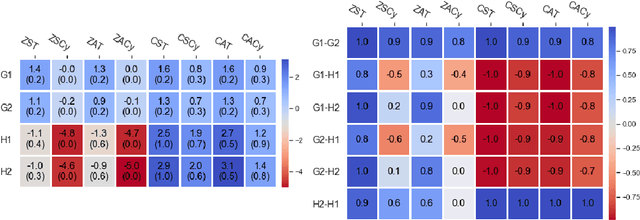
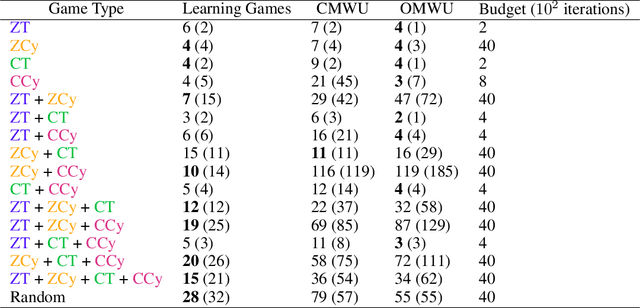
Recently, Optimistic Multiplicative Weights Update (OMWU) was proven to be the first constant step-size algorithm in the online no-regret framework to enjoy last-iterate convergence to Nash Equilibria in the constrained zero-sum bimatrix case, where weights represent the probabilities of playing pure strategies. We introduce the second such algorithm, \textit{Consensus MWU}, for which we prove local convergence and show empirically that it enjoys faster and more robust convergence than OMWU. Our algorithm shows the importance of a new object, the \textit{simplex Hessian}, as well as of the interaction of the game with the (eigen)space of vectors summing to zero, which we believe future research can build on. As for OMWU, CMWU has convergence guarantees in the zero-sum case only, but Cheung and Piliouras (2020) recently showed that OMWU and MWU display opposite convergence properties depending on whether the game is zero-sum or cooperative. Inspired by this work and the recent literature on learning to optimize for single functions, we extend CMWU to non zero-sum games by introducing a new framework for online learning in games, where the update rule's gradient and Hessian coefficients along a trajectory are learnt by a reinforcement learning policy that is conditioned on the nature of the game: \textit{the game signature}. We construct the latter using a new canonical decomposition of two-player games into eight components corresponding to commutative projection operators, generalizing and unifying recent game concepts studied in the literature. We show empirically that our new learning policy is able to exploit the game signature across a wide range of game types.
Causal Policy Gradients
Feb 20, 2021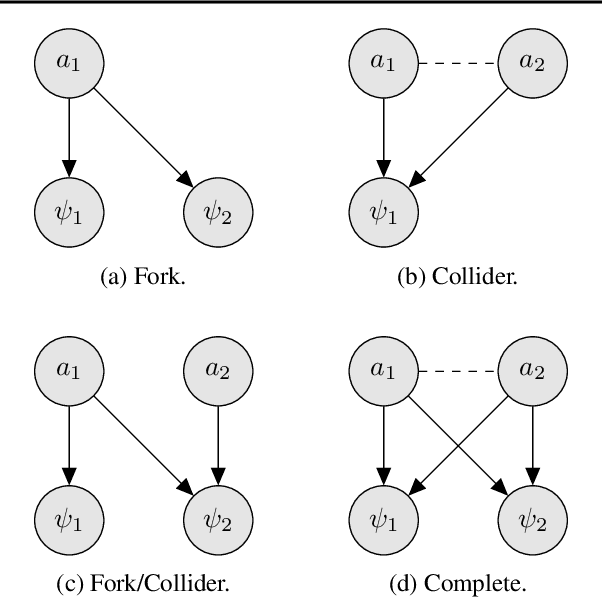
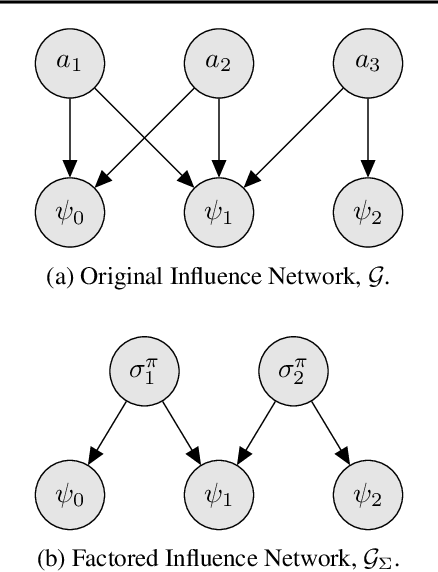
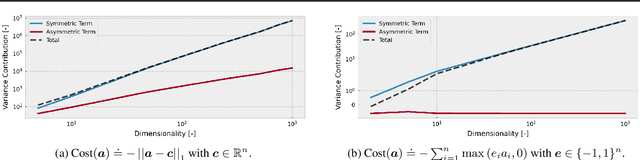
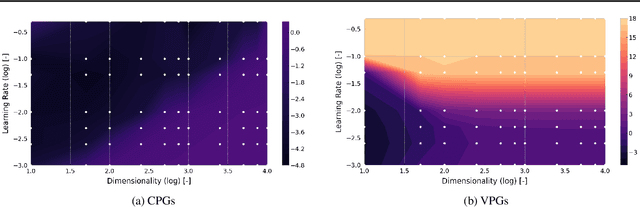
Policy gradient methods can solve complex tasks but often fail when the dimensionality of the action-space or objective multiplicity grow very large. This occurs, in part, because the variance on score-based gradient estimators scales quadratically with the number of targets. In this paper, we propose a causal baseline which exploits independence structure encoded in a novel action-target influence network. Causal policy gradients (CPGs), which follow, provide a common framework for analysing key state-of-the-art algorithms, are shown to generalise traditional policy gradients, and yield a principled way of incorporating prior knowledge of a problem domain's generative processes. We provide an analysis of the proposed estimator and identify the conditions under which variance is guaranteed to improve. The algorithmic aspects of CPGs are also discussed, including optimal policy factorisations, their complexity, and the use of conditioning to efficiently scale to extremely large, concurrent tasks. The performance advantages for two variants of the algorithm are demonstrated on large-scale bandit and concurrent inventory management problems.
A Natural Actor-Critic Algorithm with Downside Risk Constraints
Jul 08, 2020
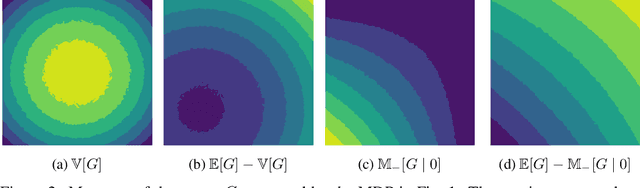
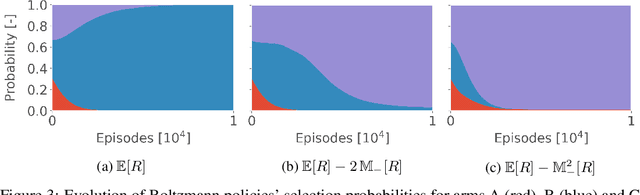
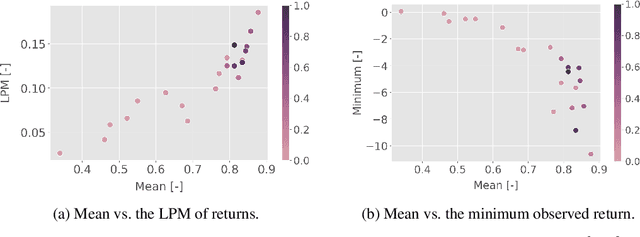
Existing work on risk-sensitive reinforcement learning - both for symmetric and downside risk measures - has typically used direct Monte-Carlo estimation of policy gradients. While this approach yields unbiased gradient estimates, it also suffers from high variance and decreased sample efficiency compared to temporal-difference methods. In this paper, we study prediction and control with aversion to downside risk which we gauge by the lower partial moment of the return. We introduce a new Bellman equation that upper bounds the lower partial moment, circumventing its non-linearity. We prove that this proxy for the lower partial moment is a contraction, and provide intuition into the stability of the algorithm by variance decomposition. This allows sample-efficient, on-line estimation of partial moments. For risk-sensitive control, we instantiate Reward Constrained Policy Optimization, a recent actor-critic method for finding constrained policies, with our proxy for the lower partial moment. We extend the method to use natural policy gradients and demonstrate the effectiveness of our approach on three benchmark problems for risk-sensitive reinforcement learning.
Robust Market Making via Adversarial Reinforcement Learning
Mar 03, 2020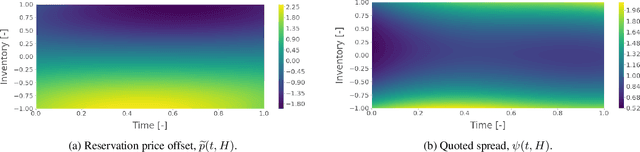
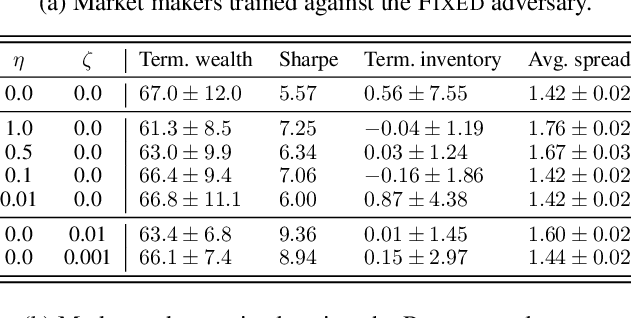
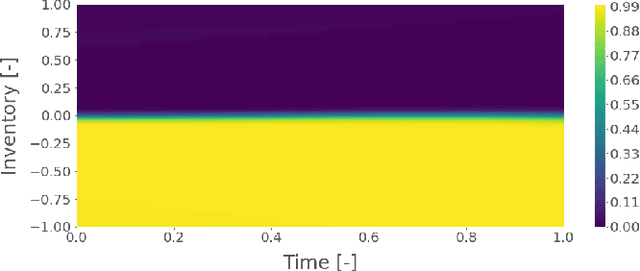
We show that adversarial reinforcement learning (ARL) can be used to produce market marking agents that are robust to adversarial and adaptively chosen market conditions. To apply ARL, we turn the well-studied single-agent model of Avellaneda and Stoikov [2008] into a discrete-time zero-sum game between a market maker and adversary, a proxy for other market participants who would like to profit at the market maker's expense. We empirically compare two conventional single-agent RL agents with ARL, and show that our ARL approach leads to: 1) the emergence of naturally risk-averse behaviour without constraints or domain-specific penalties; 2) significant improvements in performance across a set of standard metrics, evaluated with or without an adversary in the test environment, and; 3) improved robustness to model uncertainty. We empirically demonstrate that our ARL method consistently converges, and we prove for several special cases that the profiles that we converge to are Nash equilibria in a corresponding simplified single-stage game.
Market Making via Reinforcement Learning
Apr 11, 2018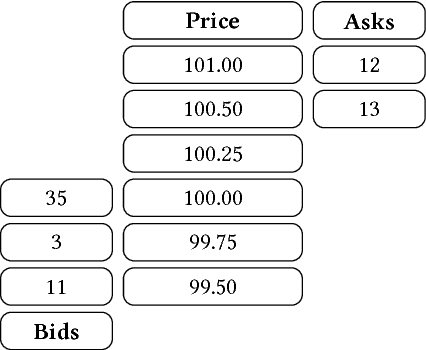

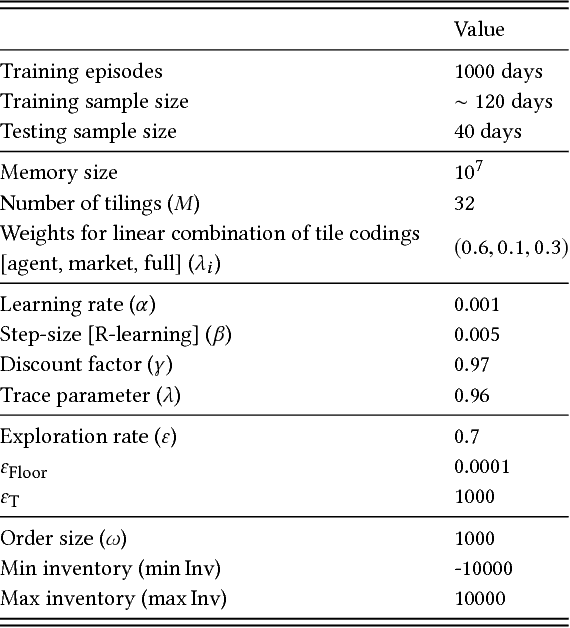
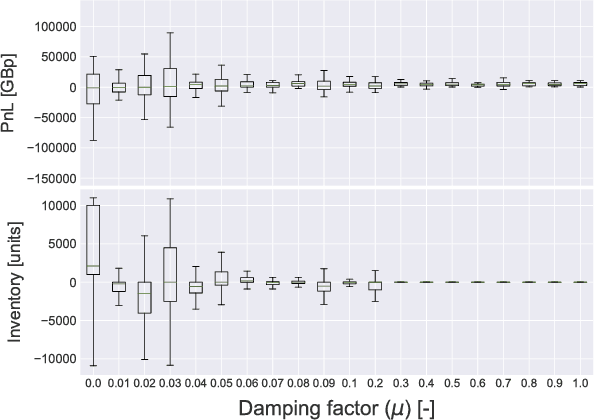
Market making is a fundamental trading problem in which an agent provides liquidity by continually offering to buy and sell a security. The problem is challenging due to inventory risk, the risk of accumulating an unfavourable position and ultimately losing money. In this paper, we develop a high-fidelity simulation of limit order book markets, and use it to design a market making agent using temporal-difference reinforcement learning. We use a linear combination of tile codings as a value function approximator, and design a custom reward function that controls inventory risk. We demonstrate the effectiveness of our approach by showing that our agent outperforms both simple benchmark strategies and a recent online learning approach from the literature.