 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog Summarisation for Defect Evolution Analysis
Mar 13, 2024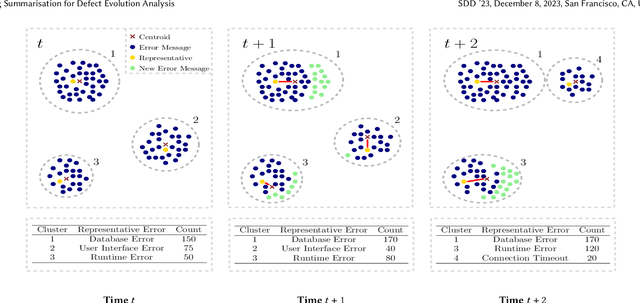
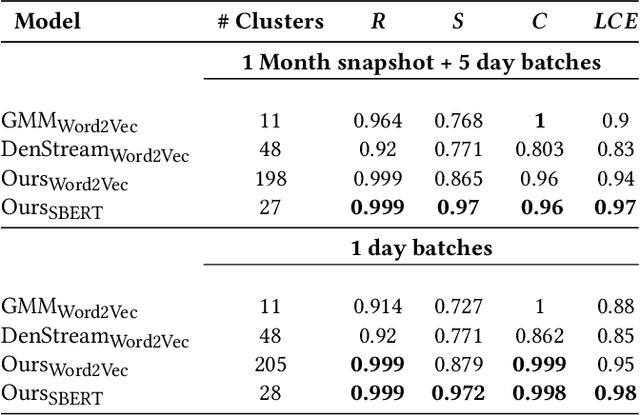
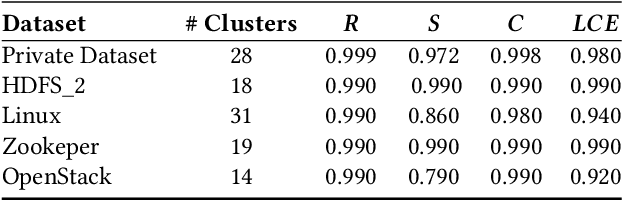
Log analysis and monitoring are essential aspects in software maintenance and identifying defects. In particular, the temporal nature and vast size of log data leads to an interesting and important research question: How can logs be summarised and monitored over time? While this has been a fundamental topic of research in the software engineering community, work has typically focused on heuristic-, syntax-, or static-based methods. In this work, we suggest an online semantic-based clustering approach to error logs that dynamically updates the log clusters to enable monitoring code error life-cycles. We also introduce a novel metric to evaluate the performance of temporal log clusters. We test our system and evaluation metric with an industrial dataset and find that our solution outperforms similar systems. We hope that our work encourages further temporal exploration in defect datasets.
Reductive MDPs: A Perspective Beyond Temporal Horizons
May 15, 2022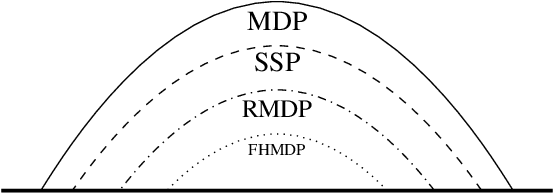
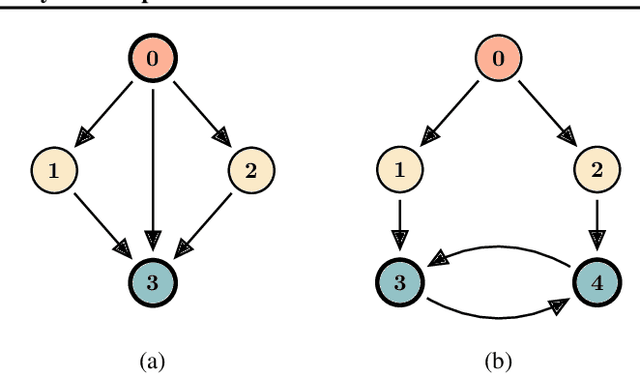
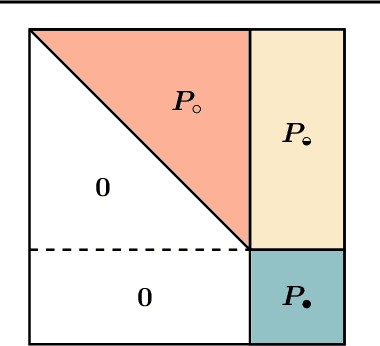
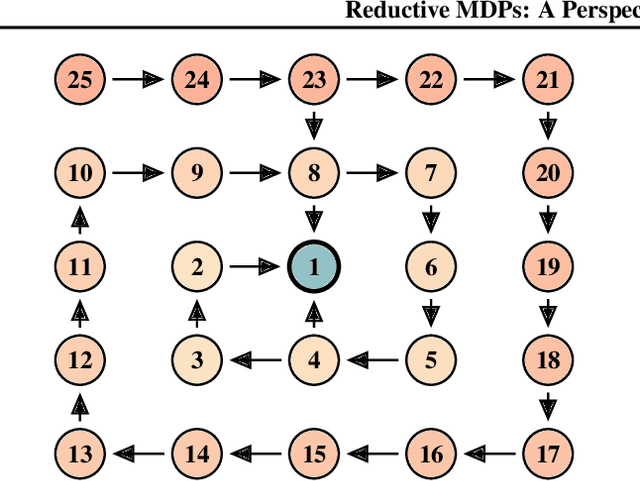
Solving general Markov decision processes (MDPs) is a computationally hard problem. Solving finite-horizon MDPs, on the other hand, is highly tractable with well known polynomial-time algorithms. What drives this extreme disparity, and do problems exist that lie between these diametrically opposed complexities? In this paper we identify and analyse a sub-class of stochastic shortest path problems (SSPs) for general state-action spaces whose dynamics satisfy a particular drift condition. This construction generalises the traditional, temporal notion of a horizon via decreasing reachability: a property called reductivity. It is shown that optimal policies can be recovered in polynomial-time for reductive SSPs -- via an extension of backwards induction -- with an efficient analogue in reductive MDPs. The practical considerations of the proposed approach are discussed, and numerical verification provided on a canonical optimal liquidation problem.
Playing Games in the Dark: An approach for cross-modality transfer in reinforcement learning
Nov 28, 2019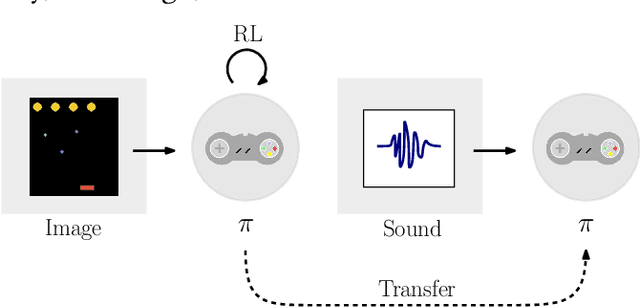
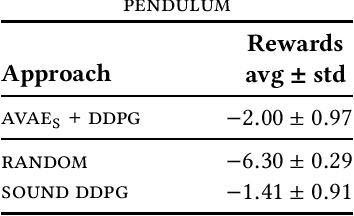
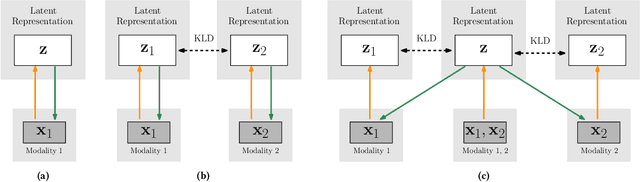

In this work we explore the use of latent representations obtained from multiple input sensory modalities (such as images or sounds) in allowing an agent to learn and exploit policies over different subsets of input modalities. We propose a three-stage architecture that allows a reinforcement learning agent trained over a given sensory modality, to execute its task on a different sensory modality-for example, learning a visual policy over image inputs, and then execute such policy when only sound inputs are available. We show that the generalized policies achieve better out-of-the-box performance when compared to different baselines. Moreover, we show this holds in different OpenAI gym and video game environments, even when using different multimodal generative models and reinforcement learning algorithms.