 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to explain yourself, when you can: Equipping Concept Bottleneck Models with the ability to abstain on their concept predictions
Nov 21, 2022



The Concept Bottleneck Models (CBMs) of Koh et al. [2020] provide a means to ensure that a neural network based classifier bases its predictions solely on human understandable concepts. The concept labels, or rationales as we refer to them, are learned by the concept labeling component of the CBM. Another component learns to predict the target classification label from these predicted concept labels. Unfortunately, these models are heavily reliant on human provided concept labels for each datapoint. To enable CBMs to behave robustly when these labels are not readily available, we show how to equip them with the ability to abstain from predicting concepts when the concept labeling component is uncertain. In other words, our model learns to provide rationales for its predictions, but only whenever it is sure the rationale is correct.
Towards learning to explain with concept bottleneck models: mitigating information leakage
Nov 07, 2022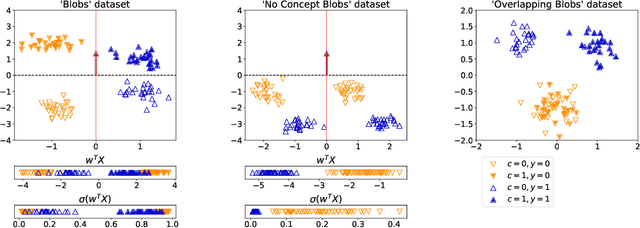
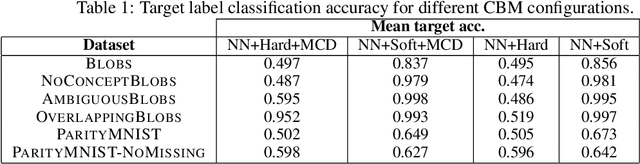
Concept bottleneck models perform classification by first predicting which of a list of human provided concepts are true about a datapoint. Then a downstream model uses these predicted concept labels to predict the target label. The predicted concepts act as a rationale for the target prediction. Model trust issues emerge in this paradigm when soft concept labels are used: it has previously been observed that extra information about the data distribution leaks into the concept predictions. In this work we show how Monte-Carlo Dropout can be used to attain soft concept predictions that do not contain leaked information.
Feature Importance for Time Series Data: Improving KernelSHAP
Oct 05, 2022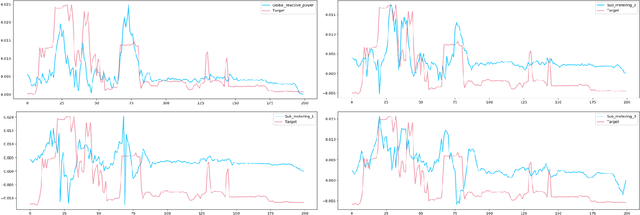
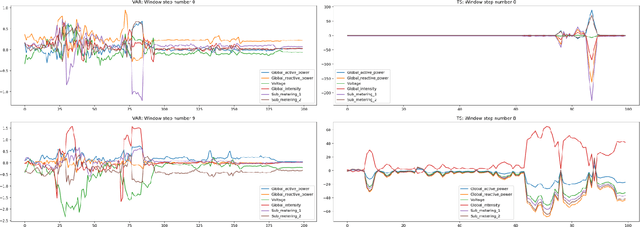
Feature importance techniques have enjoyed widespread attention in the explainable AI literature as a means of determining how trained machine learning models make their predictions. We consider Shapley value based approaches to feature importance, applied in the context of time series data. We present closed form solutions for the SHAP values of a number of time series models, including VARMAX. We also show how KernelSHAP can be applied to time series tasks, and how the feature importances that come from this technique can be combined to perform "event detection". Finally, we explore the use of Time Consistent Shapley values for feature importance.
Reductive MDPs: A Perspective Beyond Temporal Horizons
May 15, 2022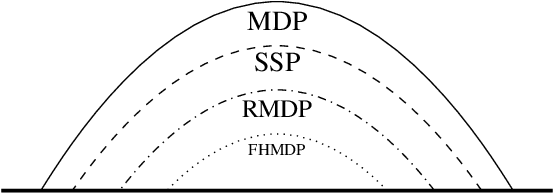
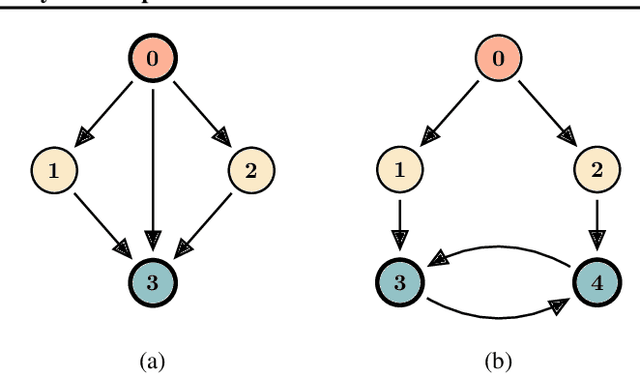
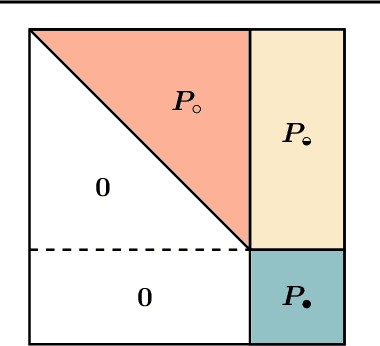
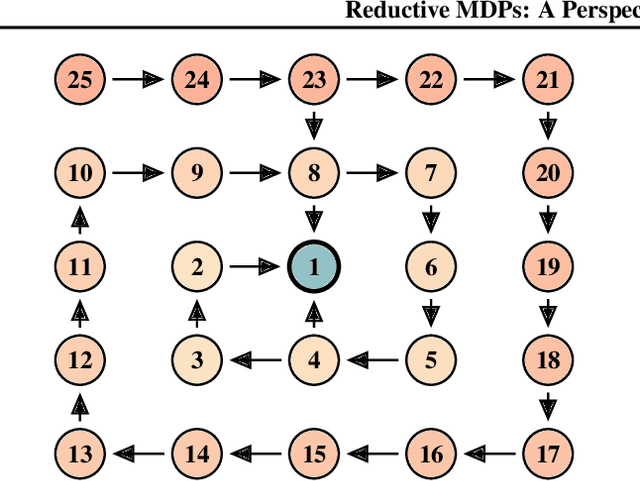
Solving general Markov decision processes (MDPs) is a computationally hard problem. Solving finite-horizon MDPs, on the other hand, is highly tractable with well known polynomial-time algorithms. What drives this extreme disparity, and do problems exist that lie between these diametrically opposed complexities? In this paper we identify and analyse a sub-class of stochastic shortest path problems (SSPs) for general state-action spaces whose dynamics satisfy a particular drift condition. This construction generalises the traditional, temporal notion of a horizon via decreasing reachability: a property called reductivity. It is shown that optimal policies can be recovered in polynomial-time for reductive SSPs -- via an extension of backwards induction -- with an efficient analogue in reductive MDPs. The practical considerations of the proposed approach are discussed, and numerical verification provided on a canonical optimal liquidation problem.
Asynchronous Collaborative Learning Across Data Silos
Mar 23, 2022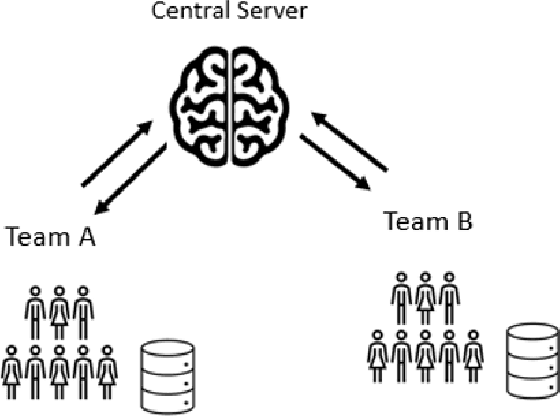
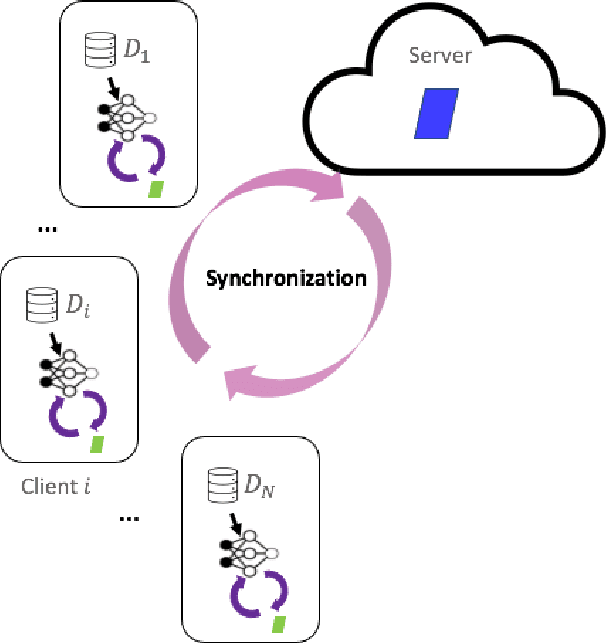
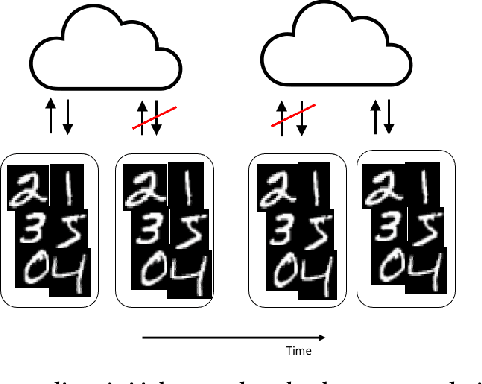
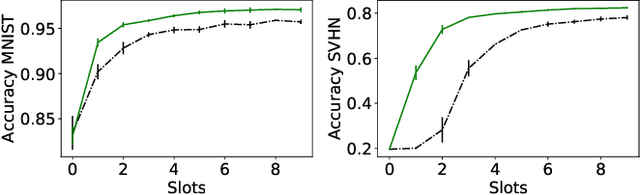
Machine learning algorithms can perform well when trained on large datasets. While large organisations often have considerable data assets, it can be difficult for these assets to be unified in a manner that makes training possible. Data is very often 'siloed' in different parts of the organisation, with little to no access between silos. This fragmentation of data assets is especially prevalent in heavily regulated industries like financial services or healthcare. In this paper we propose a framework to enable asynchronous collaborative training of machine learning models across data silos. This allows data science teams to collaboratively train a machine learning model, without sharing data with one another. Our proposed approach enhances conventional federated learning techniques to make them suitable for this asynchronous training in this intra-organisation, cross-silo setting. We validate our proposed approach via extensive experiments.
SURF: Improving classifiers in production by learning from busy and noisy end users
Oct 12, 2020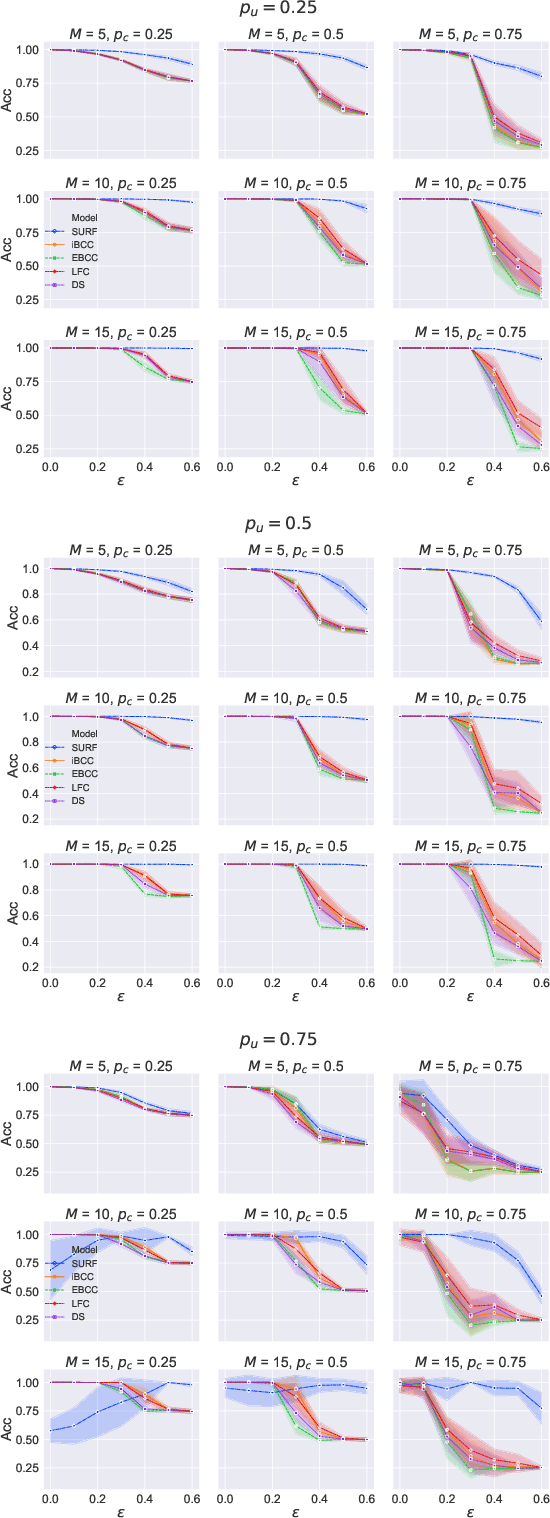
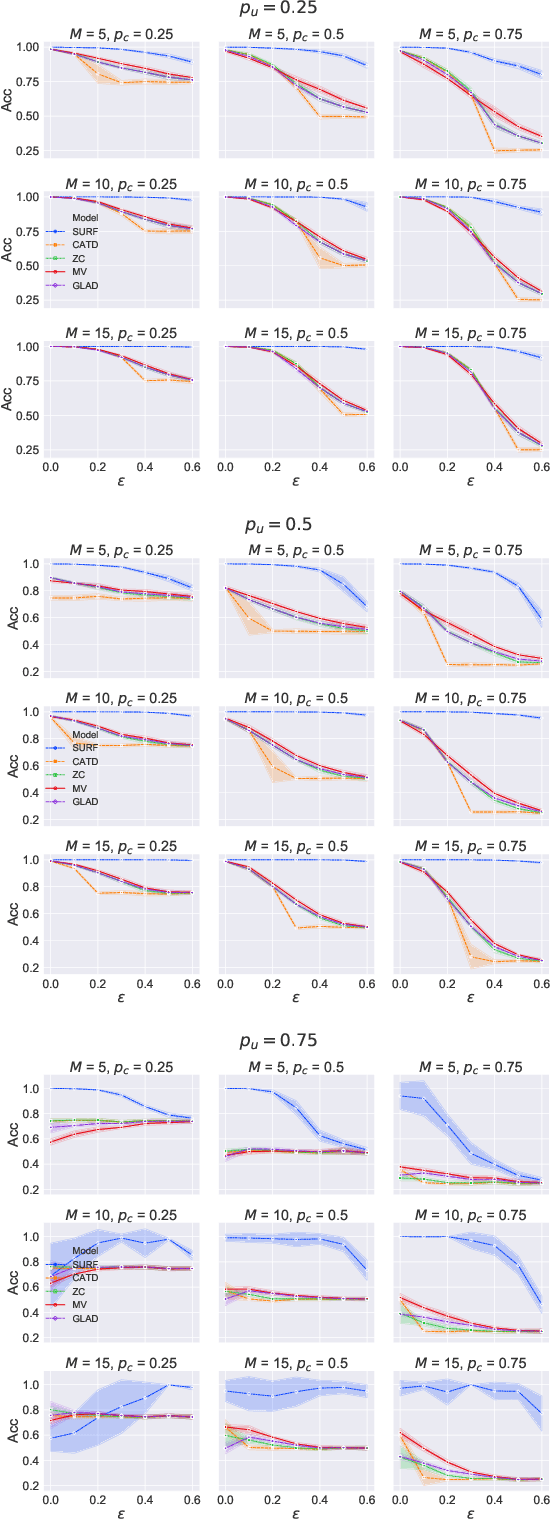
Supervised learning classifiers inevitably make mistakes in production, perhaps mis-labeling an email, or flagging an otherwise routine transaction as fraudulent. It is vital that the end users of such a system are provided with a means of relabeling data points that they deem to have been mislabeled. The classifier can then be retrained on the relabeled data points in the hope of performance improvement. To reduce noise in this feedback data, well known algorithms from the crowdsourcing literature can be employed. However, the feedback setting provides a new challenge: how do we know what to do in the case of user non-response? If a user provides us with no feedback on a label then it can be dangerous to assume they implicitly agree: a user can be busy, lazy, or no longer a user of the system! We show that conventional crowdsourcing algorithms struggle in this user feedback setting, and present a new algorithm, SURF, that can cope with this non-response ambiguity.
Some people aren't worth listening to: periodically retraining classifiers with feedback from a team of end users
Apr 27, 2020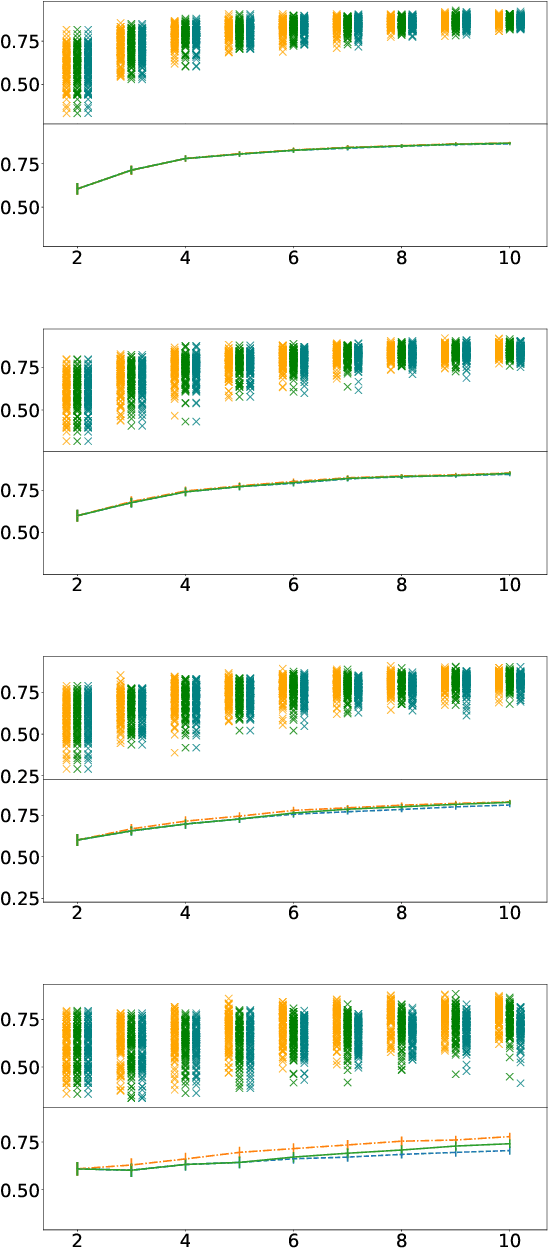
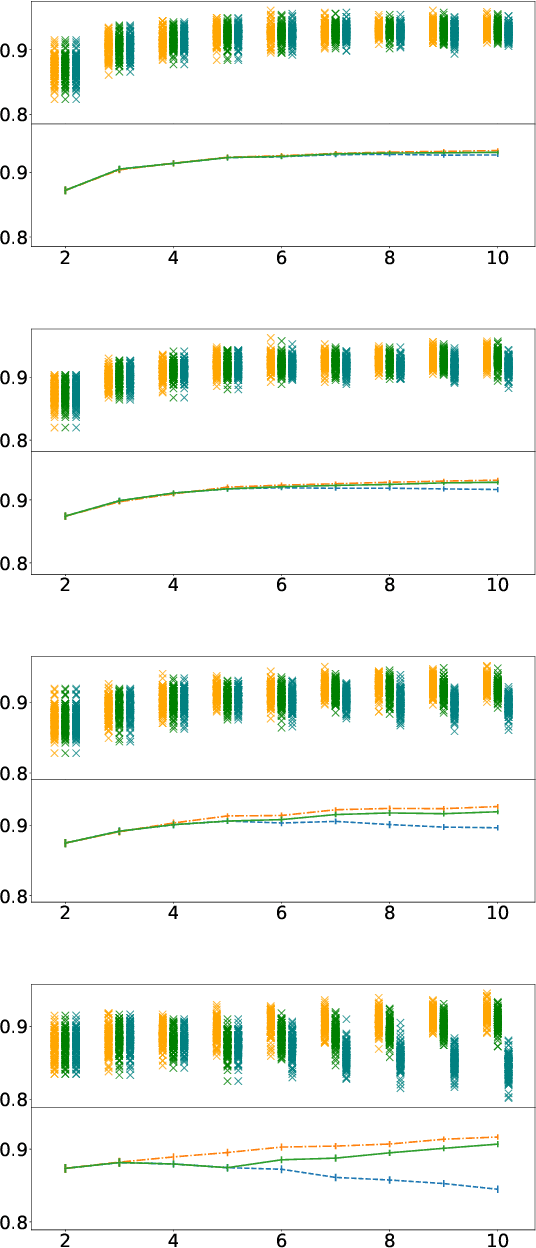
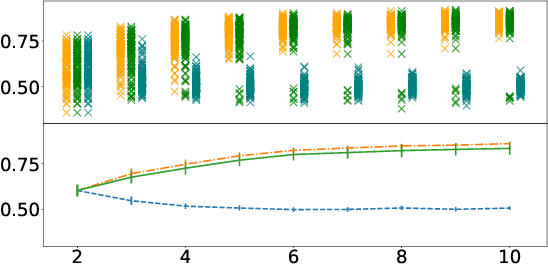
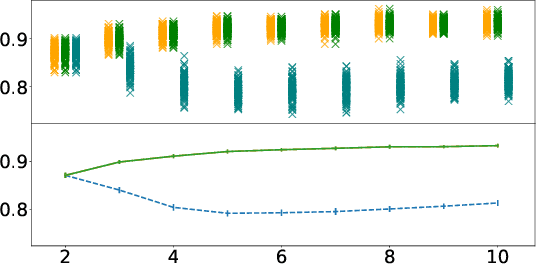
Document classification is ubiquitous in a business setting, but often the end users of a classifier are engaged in an ongoing feedback-retrain loop with the team that maintain it. We consider this feedback-retrain loop from a multi-agent point of view, considering the end users as autonomous agents that provide feedback on the labelled data provided by the classifier. This allows us to examine the effect on the classifier's performance of unreliable end users who provide incorrect feedback. We demonstrate a classifier that can learn which users tend to be unreliable, filtering their feedback out of the loop, thus improving performance in subsequent iterations.