Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards learning to explain with concept bottleneck models: mitigating information leakage
Paper and Code
Nov 07, 2022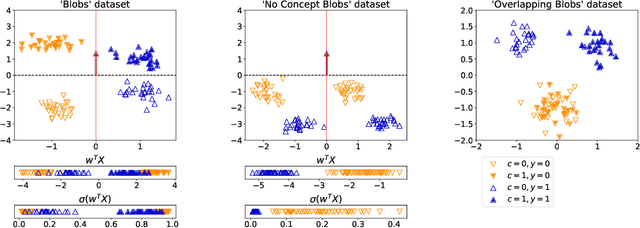
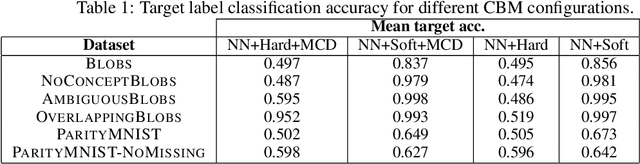
Concept bottleneck models perform classification by first predicting which of a list of human provided concepts are true about a datapoint. Then a downstream model uses these predicted concept labels to predict the target label. The predicted concepts act as a rationale for the target prediction. Model trust issues emerge in this paradigm when soft concept labels are used: it has previously been observed that extra information about the data distribution leaks into the concept predictions. In this work we show how Monte-Carlo Dropout can be used to attain soft concept predictions that do not contain leaked information.
* Presented at ICLR 2022 Workshop on Socially Responsible Machine
Learning
View paper on