 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Manual Planning: Seating Allocation for Large Organizations
Feb 05, 2026We introduce the Hierarchical Seating Allocation Problem (HSAP) which addresses the optimal assignment of hierarchically structured organizational teams to physical seating arrangements on a floor plan. This problem is driven by the necessity for large organizations with large hierarchies to ensure that teams with close hierarchical relationships are seated in proximity to one another, such as ensuring a research group occupies a contiguous area. Currently, this problem is managed manually leading to infrequent and suboptimal replanning efforts. To alleviate this manual process, we propose an end-to-end framework to solve the HSAP. A scalable approach to calculate the distance between any pair of seats using a probabilistic road map (PRM) and rapidly-exploring random trees (RRT) which is combined with heuristic search and dynamic programming approach to solve the HSAP using integer programming. We demonstrate our approach under different sized instances by evaluating the PRM framework and subsequent allocations both quantitatively and qualitatively.
Capacity Planning and Scheduling for Jobs with Uncertainty in Resource Usage and Duration
Jul 01, 2025Organizations around the world schedule jobs (programs) regularly to perform various tasks dictated by their end users. With the major movement towards using a cloud computing infrastructure, our organization follows a hybrid approach with both cloud and on-prem servers. The objective of this work is to perform capacity planning, i.e., estimate resource requirements, and job scheduling for on-prem grid computing environments. A key contribution of our approach is handling uncertainty in both resource usage and duration of the jobs, a critical aspect in the finance industry where stochastic market conditions significantly influence job characteristics. For capacity planning and scheduling, we simultaneously balance two conflicting objectives: (a) minimize resource usage, and (b) provide high quality-of-service to the end users by completing jobs by their requested deadlines. We propose approximate approaches using deterministic estimators and pair sampling-based constraint programming. Our best approach (pair sampling-based) achieves much lower peak resource usage compared to manual scheduling without compromising on the quality-of-service.
* Please cite as: Sunandita Patra, Mehtab Pathan, Mahmoud Mahfouz, Parisa Zehtabi, Wided Ouaja, Daniele Magazzeni, and Manuela Veloso. "Capacity planning and scheduling for jobs with uncertainty in resource usage and duration." The Journal of Supercomputing 80, no. 15 (2024): 22428-22461
Sequential Harmful Shift Detection Without Labels
Dec 17, 2024



We introduce a novel approach for detecting distribution shifts that negatively impact the performance of machine learning models in continuous production environments, which requires no access to ground truth data labels. It builds upon the work of Podkopaev and Ramdas [2022], who address scenarios where labels are available for tracking model errors over time. Our solution extends this framework to work in the absence of labels, by employing a proxy for the true error. This proxy is derived using the predictions of a trained error estimator. Experiments show that our method has high power and false alarm control under various distribution shifts, including covariate and label shifts and natural shifts over geography and time.
Temporal Fairness in Decision Making Problems
Aug 23, 2024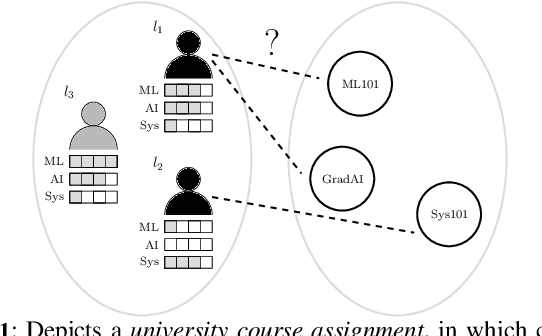



In this work we consider a new interpretation of fairness in decision making problems. Building upon existing fairness formulations, we focus on how to reason over fairness from a temporal perspective, taking into account the fairness of a history of past decisions. After introducing the concept of temporal fairness, we propose three approaches that incorporate temporal fairness in decision making problems formulated as optimization problems. We present a qualitative evaluation of our approach in four different domains and compare the solutions against a baseline approach that does not consider the temporal aspect of fairness.
Are Logistic Models Really Interpretable?
Jun 19, 2024



The demand for open and trustworthy AI models points towards widespread publishing of model weights. Consumers of these model weights must be able to act accordingly with the information provided. That said, one of the simplest AI classification models, Logistic Regression (LR), has an unwieldy interpretation of its model weights, with greater difficulties when extending LR to generalised additive models. In this work, we show via a User Study that skilled participants are unable to reliably reproduce the action of small LR models given the trained parameters. As an antidote to this, we define Linearised Additive Models (LAMs), an optimal piecewise linear approximation that augments any trained additive model equipped with a sigmoid link function, requiring no retraining. We argue that LAMs are more interpretable than logistic models -- survey participants are shown to solve model reasoning tasks with LAMs much more accurately than with LR given the same information. Furthermore, we show that LAMs do not suffer from large performance penalties in terms of ROC-AUC and calibration with respect to their logistic counterparts on a broad suite of public financial modelling data.
Progressive Inference: Explaining Decoder-Only Sequence Classification Models Using Intermediate Predictions
Jun 03, 2024



This paper proposes Progressive Inference - a framework to compute input attributions to explain the predictions of decoder-only sequence classification models. Our work is based on the insight that the classification head of a decoder-only Transformer model can be used to make intermediate predictions by evaluating them at different points in the input sequence. Due to the causal attention mechanism, these intermediate predictions only depend on the tokens seen before the inference point, allowing us to obtain the model's prediction on a masked input sub-sequence, with negligible computational overheads. We develop two methods to provide sub-sequence level attributions using this insight. First, we propose Single Pass-Progressive Inference (SP-PI), which computes attributions by taking the difference between consecutive intermediate predictions. Second, we exploit a connection with Kernel SHAP to develop Multi Pass-Progressive Inference (MP-PI). MP-PI uses intermediate predictions from multiple masked versions of the input to compute higher quality attributions. Our studies on a diverse set of models trained on text classification tasks show that SP-PI and MP-PI provide significantly better attributions compared to prior work.
Counterfactual Metarules for Local and Global Recourse
May 29, 2024



We introduce T-CREx, a novel model-agnostic method for local and global counterfactual explanation (CE), which summarises recourse options for both individuals and groups in the form of human-readable rules. It leverages tree-based surrogate models to learn the counterfactual rules, alongside 'metarules' denoting their regions of optimality, providing both a global analysis of model behaviour and diverse recourse options for users. Experiments indicate that T-CREx achieves superior aggregate performance over existing rule-based baselines on a range of CE desiderata, while being orders of magnitude faster to run.
Deep Reinforcement Learning and Mean-Variance Strategies for Responsible Portfolio Optimization
Mar 25, 2024Portfolio optimization involves determining the optimal allocation of portfolio assets in order to maximize a given investment objective. Traditionally, some form of mean-variance optimization is used with the aim of maximizing returns while minimizing risk, however, more recently, deep reinforcement learning formulations have been explored. Increasingly, investors have demonstrated an interest in incorporating ESG objectives when making investment decisions, and modifications to the classical mean-variance optimization framework have been developed. In this work, we study the use of deep reinforcement learning for responsible portfolio optimization, by incorporating ESG states and objectives, and provide comparisons against modified mean-variance approaches. Our results show that deep reinforcement learning policies can provide competitive performance against mean-variance approaches for responsible portfolio allocation across additive and multiplicative utility functions of financial and ESG responsibility objectives.
REFRESH: Responsible and Efficient Feature Reselection Guided by SHAP Values
Mar 13, 2024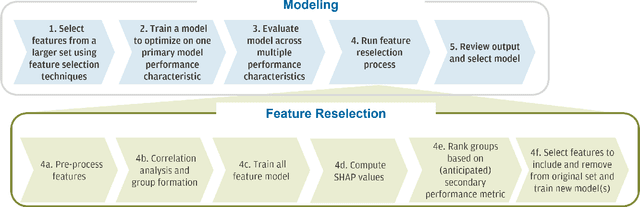


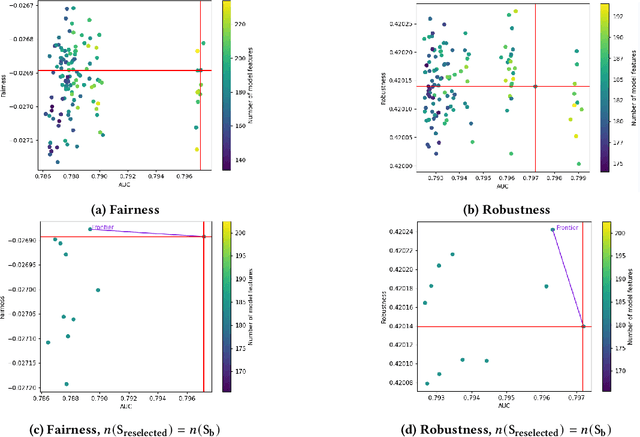
Feature selection is a crucial step in building machine learning models. This process is often achieved with accuracy as an objective, and can be cumbersome and computationally expensive for large-scale datasets. Several additional model performance characteristics such as fairness and robustness are of importance for model development. As regulations are driving the need for more trustworthy models, deployed models need to be corrected for model characteristics associated with responsible artificial intelligence. When feature selection is done with respect to one model performance characteristic (eg. accuracy), feature selection with secondary model performance characteristics (eg. fairness and robustness) as objectives would require going through the computationally expensive selection process from scratch. In this paper, we introduce the problem of feature \emph{reselection}, so that features can be selected with respect to secondary model performance characteristics efficiently even after a feature selection process has been done with respect to a primary objective. To address this problem, we propose REFRESH, a method to reselect features so that additional constraints that are desirable towards model performance can be achieved without having to train several new models. REFRESH's underlying algorithm is a novel technique using SHAP values and correlation analysis that can approximate for the predictions of a model without having to train these models. Empirical evaluations on three datasets, including a large-scale loan defaulting dataset show that REFRESH can help find alternate models with better model characteristics efficiently. We also discuss the need for reselection and REFRESH based on regulation desiderata.
Privacy-Preserving Algorithmic Recourse
Nov 23, 2023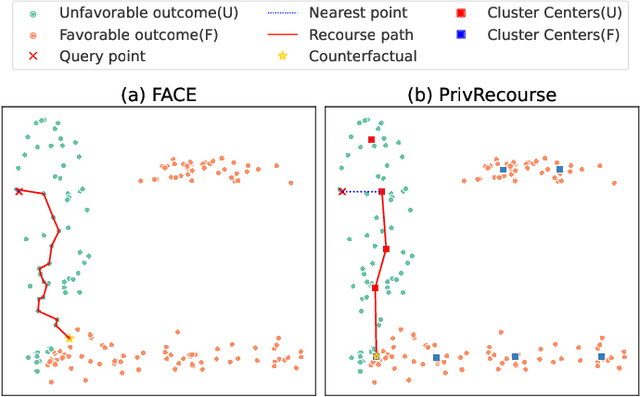

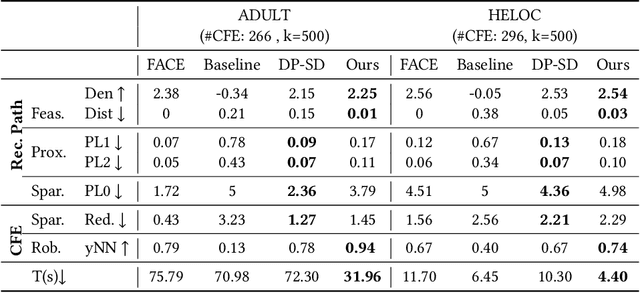
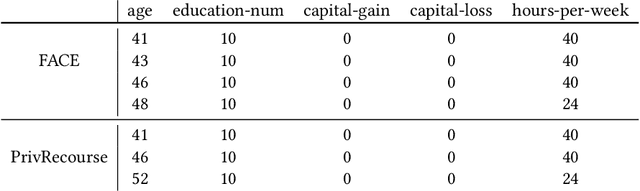
When individuals are subject to adverse outcomes from machine learning models, providing a recourse path to help achieve a positive outcome is desirable. Recent work has shown that counterfactual explanations - which can be used as a means of single-step recourse - are vulnerable to privacy issues, putting an individuals' privacy at risk. Providing a sequential multi-step path for recourse can amplify this risk. Furthermore, simply adding noise to recourse paths found from existing methods can impact the realism and actionability of the path for an end-user. In this work, we address privacy issues when generating realistic recourse paths based on instance-based counterfactual explanations, and provide PrivRecourse: an end-to-end privacy preserving pipeline that can provide realistic recourse paths. PrivRecourse uses differentially private (DP) clustering to represent non-overlapping subsets of the private dataset. These DP cluster centers are then used to generate recourse paths by forming a graph with cluster centers as the nodes, so that we can generate realistic - feasible and actionable - recourse paths. We empirically evaluate our approach on finance datasets and compare it to simply adding noise to data instances, and to using DP synthetic data, to generate the graph. We observe that PrivRecourse can provide paths that are private and realistic.