 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Logistic Models Really Interpretable?
Jun 19, 2024



The demand for open and trustworthy AI models points towards widespread publishing of model weights. Consumers of these model weights must be able to act accordingly with the information provided. That said, one of the simplest AI classification models, Logistic Regression (LR), has an unwieldy interpretation of its model weights, with greater difficulties when extending LR to generalised additive models. In this work, we show via a User Study that skilled participants are unable to reliably reproduce the action of small LR models given the trained parameters. As an antidote to this, we define Linearised Additive Models (LAMs), an optimal piecewise linear approximation that augments any trained additive model equipped with a sigmoid link function, requiring no retraining. We argue that LAMs are more interpretable than logistic models -- survey participants are shown to solve model reasoning tasks with LAMs much more accurately than with LR given the same information. Furthermore, we show that LAMs do not suffer from large performance penalties in terms of ROC-AUC and calibration with respect to their logistic counterparts on a broad suite of public financial modelling data.
Progressive Inference: Explaining Decoder-Only Sequence Classification Models Using Intermediate Predictions
Jun 03, 2024



This paper proposes Progressive Inference - a framework to compute input attributions to explain the predictions of decoder-only sequence classification models. Our work is based on the insight that the classification head of a decoder-only Transformer model can be used to make intermediate predictions by evaluating them at different points in the input sequence. Due to the causal attention mechanism, these intermediate predictions only depend on the tokens seen before the inference point, allowing us to obtain the model's prediction on a masked input sub-sequence, with negligible computational overheads. We develop two methods to provide sub-sequence level attributions using this insight. First, we propose Single Pass-Progressive Inference (SP-PI), which computes attributions by taking the difference between consecutive intermediate predictions. Second, we exploit a connection with Kernel SHAP to develop Multi Pass-Progressive Inference (MP-PI). MP-PI uses intermediate predictions from multiple masked versions of the input to compute higher quality attributions. Our studies on a diverse set of models trained on text classification tasks show that SP-PI and MP-PI provide significantly better attributions compared to prior work.
SHAP@k:Efficient and Probably Approximately Correct (PAC) Identification of Top-k Features
Jul 10, 2023


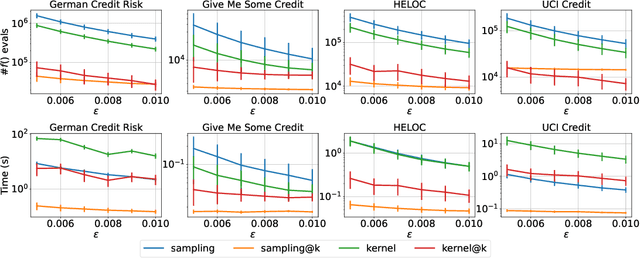
The SHAP framework provides a principled method to explain the predictions of a model by computing feature importance. Motivated by applications in finance, we introduce the Top-k Identification Problem (TkIP), where the objective is to identify the k features with the highest SHAP values. While any method to compute SHAP values with uncertainty estimates (such as KernelSHAP and SamplingSHAP) can be trivially adapted to solve TkIP, doing so is highly sample inefficient. The goal of our work is to improve the sample efficiency of existing methods in the context of solving TkIP. Our key insight is that TkIP can be framed as an Explore-m problem--a well-studied problem related to multi-armed bandits (MAB). This connection enables us to improve sample efficiency by leveraging two techniques from the MAB literature: (1) a better stopping-condition (to stop sampling) that identifies when PAC (Probably Approximately Correct) guarantees have been met and (2) a greedy sampling scheme that judiciously allocates samples between different features. By adopting these methods we develop KernelSHAP@k and SamplingSHAP@k to efficiently solve TkIP, offering an average improvement of $5\times$ in sample-efficiency and runtime across most common credit related datasets.