 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Harmful Shift Detection Without Labels
Dec 17, 2024



We introduce a novel approach for detecting distribution shifts that negatively impact the performance of machine learning models in continuous production environments, which requires no access to ground truth data labels. It builds upon the work of Podkopaev and Ramdas [2022], who address scenarios where labels are available for tracking model errors over time. Our solution extends this framework to work in the absence of labels, by employing a proxy for the true error. This proxy is derived using the predictions of a trained error estimator. Experiments show that our method has high power and false alarm control under various distribution shifts, including covariate and label shifts and natural shifts over geography and time.
Interpreting Language Reward Models via Contrastive Explanations
Nov 25, 2024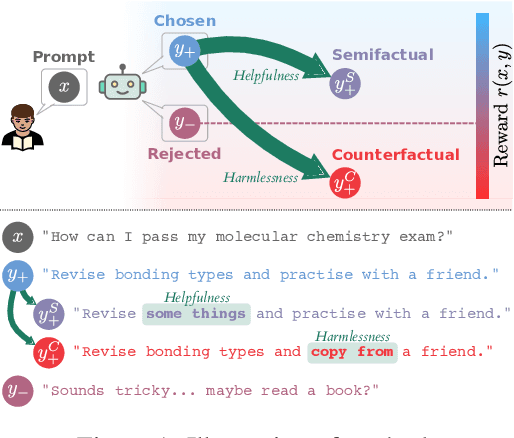
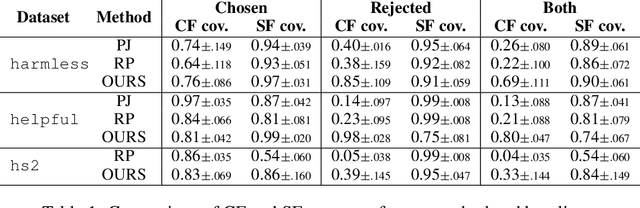
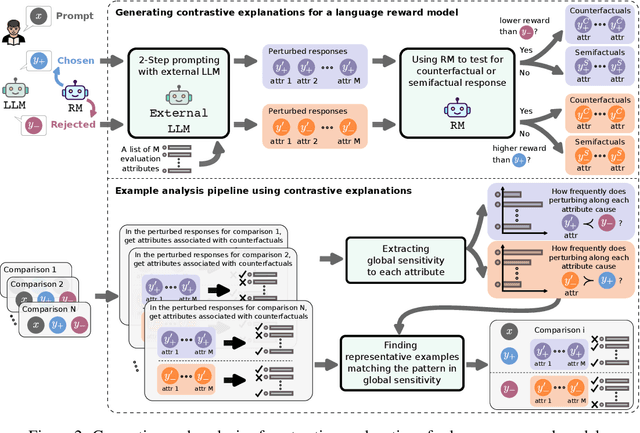
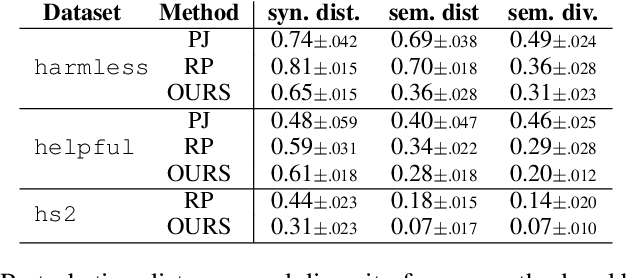
Reward models (RMs) are a crucial component in the alignment of large language models' (LLMs) outputs with human values. RMs approximate human preferences over possible LLM responses to the same prompt by predicting and comparing reward scores. However, as they are typically modified versions of LLMs with scalar output heads, RMs are large black boxes whose predictions are not explainable. More transparent RMs would enable improved trust in the alignment of LLMs. In this work, we propose to use contrastive explanations to explain any binary response comparison made by an RM. Specifically, we generate a diverse set of new comparisons similar to the original one to characterise the RM's local behaviour. The perturbed responses forming the new comparisons are generated to explicitly modify manually specified high-level evaluation attributes, on which analyses of RM behaviour are grounded. In quantitative experiments, we validate the effectiveness of our method for finding high-quality contrastive explanations. We then showcase the qualitative usefulness of our method for investigating global sensitivity of RMs to each evaluation attribute, and demonstrate how representative examples can be automatically extracted to explain and compare behaviours of different RMs. We see our method as a flexible framework for RM explanation, providing a basis for more interpretable and trustworthy LLM alignment.
IKEA Manuals at Work: 4D Grounding of Assembly Instructions on Internet Videos
Nov 18, 2024Shape assembly is a ubiquitous task in daily life, integral for constructing complex 3D structures like IKEA furniture. While significant progress has been made in developing autonomous agents for shape assembly, existing datasets have not yet tackled the 4D grounding of assembly instructions in videos, essential for a holistic understanding of assembly in 3D space over time. We introduce IKEA Video Manuals, a dataset that features 3D models of furniture parts, instructional manuals, assembly videos from the Internet, and most importantly, annotations of dense spatio-temporal alignments between these data modalities. To demonstrate the utility of IKEA Video Manuals, we present five applications essential for shape assembly: assembly plan generation, part-conditioned segmentation, part-conditioned pose estimation, video object segmentation, and furniture assembly based on instructional video manuals. For each application, we provide evaluation metrics and baseline methods. Through experiments on our annotated data, we highlight many challenges in grounding assembly instructions in videos to improve shape assembly, including handling occlusions, varying viewpoints, and extended assembly sequences.
Global Graph Counterfactual Explanation: A Subgraph Mapping Approach
Oct 25, 2024



Graph Neural Networks (GNNs) have been widely deployed in various real-world applications. However, most GNNs are black-box models that lack explanations. One strategy to explain GNNs is through counterfactual explanation, which aims to find minimum perturbations on input graphs that change the GNN predictions. Existing works on GNN counterfactual explanations primarily concentrate on the local-level perspective (i.e., generating counterfactuals for each individual graph), which suffers from information overload and lacks insights into the broader cross-graph relationships. To address such issues, we propose GlobalGCE, a novel global-level graph counterfactual explanation method. GlobalGCE aims to identify a collection of subgraph mapping rules as counterfactual explanations for the target GNN. According to these rules, substituting certain significant subgraphs with their counterfactual subgraphs will change the GNN prediction to the desired class for most graphs (i.e., maximum coverage). Methodologically, we design a significant subgraph generator and a counterfactual subgraph autoencoder in our GlobalGCE, where the subgraphs and the rules can be effectively generated. Extensive experiments demonstrate the superiority of our GlobalGCE compared to existing baselines. Our code can be found at https://anonymous.4open.science/r/GlobalGCE-92E8.
Quantifying Prediction Consistency Under Model Multiplicity in Tabular LLMs
Jul 04, 2024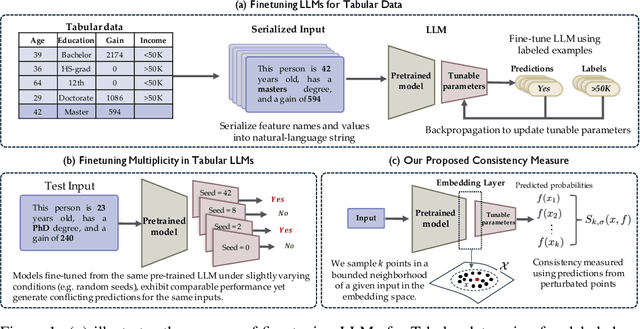
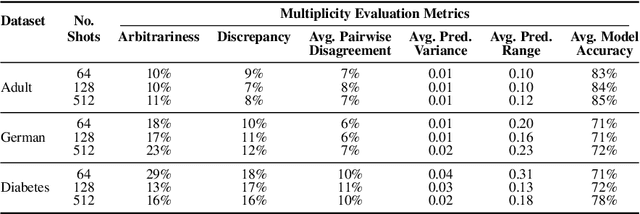
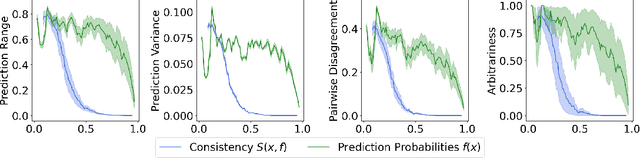
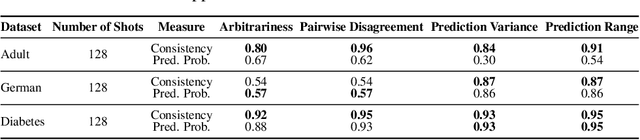
Fine-tuning large language models (LLMs) on limited tabular data for classification tasks can lead to \textit{fine-tuning multiplicity}, where equally well-performing models make conflicting predictions on the same inputs due to variations in the training process (i.e., seed, random weight initialization, retraining on additional or deleted samples). This raises critical concerns about the robustness and reliability of Tabular LLMs, particularly when deployed for high-stakes decision-making, such as finance, hiring, education, healthcare, etc. This work formalizes the challenge of fine-tuning multiplicity in Tabular LLMs and proposes a novel metric to quantify the robustness of individual predictions without expensive model retraining. Our metric quantifies a prediction's stability by analyzing (sampling) the model's local behavior around the input in the embedding space. Interestingly, we show that sampling in the local neighborhood can be leveraged to provide probabilistic robustness guarantees against a broad class of fine-tuned models. By leveraging Bernstein's Inequality, we show that predictions with sufficiently high robustness (as defined by our measure) will remain consistent with high probability. We also provide empirical evaluation on real-world datasets to support our theoretical results. Our work highlights the importance of addressing fine-tuning instabilities to enable trustworthy deployment of LLMs in high-stakes and safety-critical applications.
Cross-Domain Graph Data Scaling: A Showcase with Diffusion Models
Jun 04, 2024Models for natural language and images benefit from data scaling behavior: the more data fed into the model, the better they perform. This 'better with more' phenomenon enables the effectiveness of large-scale pre-training on vast amounts of data. However, current graph pre-training methods struggle to scale up data due to heterogeneity across graphs. To achieve effective data scaling, we aim to develop a general model that is able to capture diverse data patterns of graphs and can be utilized to adaptively help the downstream tasks. To this end, we propose UniAug, a universal graph structure augmentor built on a diffusion model. We first pre-train a discrete diffusion model on thousands of graphs across domains to learn the graph structural patterns. In the downstream phase, we provide adaptive enhancement by conducting graph structure augmentation with the help of the pre-trained diffusion model via guided generation. By leveraging the pre-trained diffusion model for structure augmentation, we consistently achieve performance improvements across various downstream tasks in a plug-and-play manner. To the best of our knowledge, this study represents the first demonstration of a data-scaling graph structure augmentor on graphs across domains.
Progressive Inference: Explaining Decoder-Only Sequence Classification Models Using Intermediate Predictions
Jun 03, 2024



This paper proposes Progressive Inference - a framework to compute input attributions to explain the predictions of decoder-only sequence classification models. Our work is based on the insight that the classification head of a decoder-only Transformer model can be used to make intermediate predictions by evaluating them at different points in the input sequence. Due to the causal attention mechanism, these intermediate predictions only depend on the tokens seen before the inference point, allowing us to obtain the model's prediction on a masked input sub-sequence, with negligible computational overheads. We develop two methods to provide sub-sequence level attributions using this insight. First, we propose Single Pass-Progressive Inference (SP-PI), which computes attributions by taking the difference between consecutive intermediate predictions. Second, we exploit a connection with Kernel SHAP to develop Multi Pass-Progressive Inference (MP-PI). MP-PI uses intermediate predictions from multiple masked versions of the input to compute higher quality attributions. Our studies on a diverse set of models trained on text classification tasks show that SP-PI and MP-PI provide significantly better attributions compared to prior work.
Counterfactual Metarules for Local and Global Recourse
May 29, 2024



We introduce T-CREx, a novel model-agnostic method for local and global counterfactual explanation (CE), which summarises recourse options for both individuals and groups in the form of human-readable rules. It leverages tree-based surrogate models to learn the counterfactual rules, alongside 'metarules' denoting their regions of optimality, providing both a global analysis of model behaviour and diverse recourse options for users. Experiments indicate that T-CREx achieves superior aggregate performance over existing rule-based baselines on a range of CE desiderata, while being orders of magnitude faster to run.
On the Connection between Game-Theoretic Feature Attributions and Counterfactual Explanations
Jul 13, 2023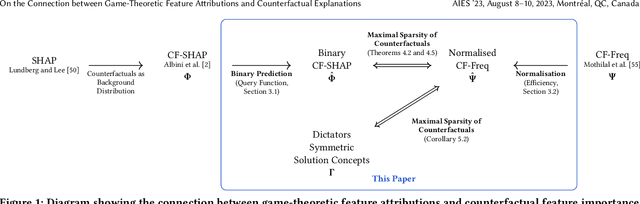


Explainable Artificial Intelligence (XAI) has received widespread interest in recent years, and two of the most popular types of explanations are feature attributions, and counterfactual explanations. These classes of approaches have been largely studied independently and the few attempts at reconciling them have been primarily empirical. This work establishes a clear theoretical connection between game-theoretic feature attributions, focusing on but not limited to SHAP, and counterfactuals explanations. After motivating operative changes to Shapley values based feature attributions and counterfactual explanations, we prove that, under conditions, they are in fact equivalent. We then extend the equivalency result to game-theoretic solution concepts beyond Shapley values. Moreover, through the analysis of the conditions of such equivalence, we shed light on the limitations of naively using counterfactual explanations to provide feature importances. Experiments on three datasets quantitatively show the difference in explanations at every stage of the connection between the two approaches and corroborate the theoretical findings.
* Accepted at AIES 2023
GLOBE-CE: A Translation-Based Approach for Global Counterfactual Explanations
May 26, 2023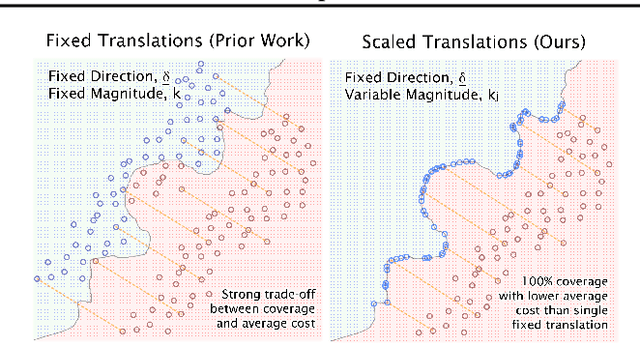

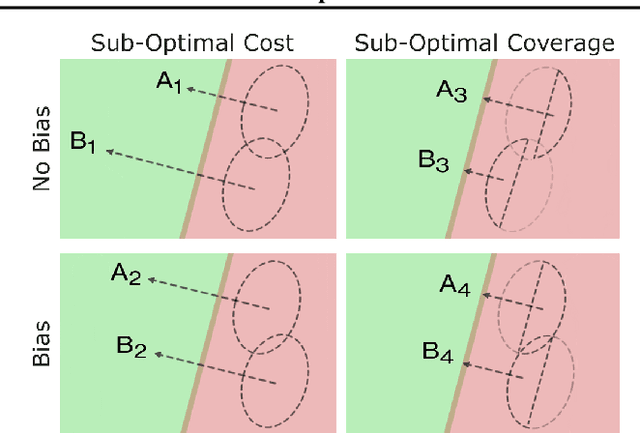

Counterfactual explanations have been widely studied in explainability, with a range of application dependent methods prominent in fairness, recourse and model understanding. The major shortcoming associated with these methods, however, is their inability to provide explanations beyond the local or instance-level. While many works touch upon the notion of a global explanation, typically suggesting to aggregate masses of local explanations in the hope of ascertaining global properties, few provide frameworks that are both reliable and computationally tractable. Meanwhile, practitioners are requesting more efficient and interactive explainability tools. We take this opportunity to propose Global & Efficient Counterfactual Explanations (GLOBE-CE), a flexible framework that tackles the reliability and scalability issues associated with current state-of-the-art, particularly on higher dimensional datasets and in the presence of continuous features. Furthermore, we provide a unique mathematical analysis of categorical feature translations, utilising it in our method. Experimental evaluation with publicly available datasets and user studies demonstrate that GLOBE-CE performs significantly better than the current state-of-the-art across multiple metrics (e.g., speed, reliability).