 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonty Hall and Optimized Conformal Prediction to Improve Decision-Making with LLMs
Dec 31, 2024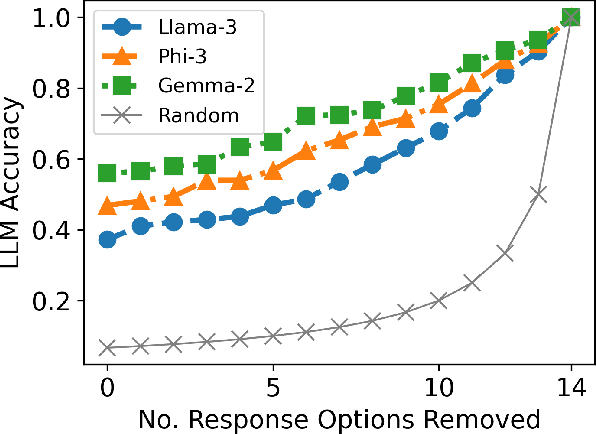
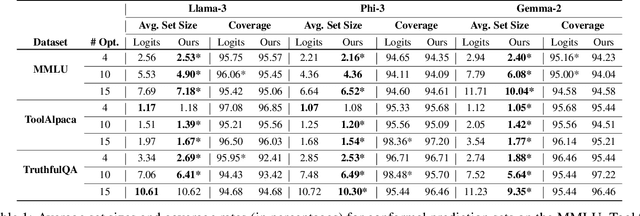
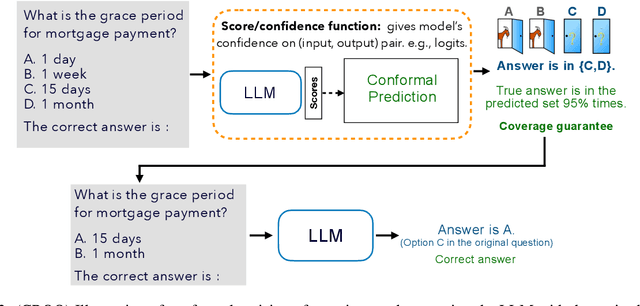
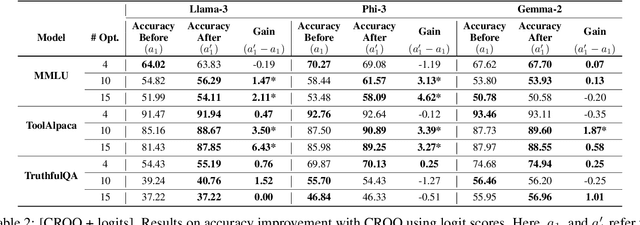
Large language models (LLMs) are empowering decision-making in several applications, including tool or API usage and answering multiple-choice questions (MCQs). However, they often make overconfident, incorrect predictions, which can be risky in high-stakes settings like healthcare and finance. To mitigate these risks, recent works have used conformal prediction (CP), a model-agnostic framework for distribution-free uncertainty quantification. CP transforms a \emph{score function} into prediction sets that contain the true answer with high probability. While CP provides this coverage guarantee for arbitrary scores, the score quality significantly impacts prediction set sizes. Prior works have relied on LLM logits or other heuristic scores, lacking quality guarantees. We address this limitation by introducing CP-OPT, an optimization framework to learn scores that minimize set sizes while maintaining coverage. Furthermore, inspired by the Monty Hall problem, we extend CP's utility beyond uncertainty quantification to improve accuracy. We propose \emph{conformal revision of questions} (CROQ) to revise the problem by narrowing down the available choices to those in the prediction set. The coverage guarantee of CP ensures that the correct choice is in the revised question prompt with high probability, while the smaller number of choices increases the LLM's chances of answering it correctly. Experiments on MMLU, ToolAlpaca, and TruthfulQA datasets with Gemma-2, Llama-3 and Phi-3 models show that CP-OPT significantly reduces set sizes while maintaining coverage, and CROQ improves accuracy over the standard inference, especially when paired with CP-OPT scores. Together, CP-OPT and CROQ offer a robust framework for improving both the safety and accuracy of LLM-driven decision-making.
Robust and Efficient Fine-tuning of LLMs with Bayesian Reparameterization of Low-Rank Adaptation
Nov 07, 2024



Large Language Models (LLMs) are highly resource-intensive to fine-tune due to their enormous size. While low-rank adaptation is a prominent parameter-efficient fine-tuning approach, it suffers from sensitivity to hyperparameter choices, leading to instability in model performance on fine-tuning downstream tasks. This paper highlights the importance of effective parameterization in low-rank fine-tuning to reduce estimator variance and enhance the stability of final model outputs. We propose MonteCLoRA, an efficient fine-tuning technique, employing Monte Carlo estimation to learn an unbiased posterior estimation of low-rank parameters with low expected variance, which stabilizes fine-tuned LLMs with only O(1) additional parameters. MonteCLoRA shows significant improvements in accuracy and robustness, achieving up to 3.8% higher accuracy and 8.6% greater robustness than existing efficient fine-tuning methods on natural language understanding tasks with pre-trained RoBERTa-base. Furthermore, in generative tasks with pre-trained LLaMA-1-7B, MonteCLoRA demonstrates robust zero-shot performance with 50% lower variance than the contemporary efficient fine-tuning methods. The theoretical and empirical results presented in the paper underscore how parameterization and hyperpriors balance exploration-exploitation in the low-rank parametric space, therefore leading to more optimal and robust parameter estimation during efficient fine-tuning.
Global Graph Counterfactual Explanation: A Subgraph Mapping Approach
Oct 25, 2024



Graph Neural Networks (GNNs) have been widely deployed in various real-world applications. However, most GNNs are black-box models that lack explanations. One strategy to explain GNNs is through counterfactual explanation, which aims to find minimum perturbations on input graphs that change the GNN predictions. Existing works on GNN counterfactual explanations primarily concentrate on the local-level perspective (i.e., generating counterfactuals for each individual graph), which suffers from information overload and lacks insights into the broader cross-graph relationships. To address such issues, we propose GlobalGCE, a novel global-level graph counterfactual explanation method. GlobalGCE aims to identify a collection of subgraph mapping rules as counterfactual explanations for the target GNN. According to these rules, substituting certain significant subgraphs with their counterfactual subgraphs will change the GNN prediction to the desired class for most graphs (i.e., maximum coverage). Methodologically, we design a significant subgraph generator and a counterfactual subgraph autoencoder in our GlobalGCE, where the subgraphs and the rules can be effectively generated. Extensive experiments demonstrate the superiority of our GlobalGCE compared to existing baselines. Our code can be found at https://anonymous.4open.science/r/GlobalGCE-92E8.
Scalable Representation Learning for Multimodal Tabular Transactions
Oct 10, 2024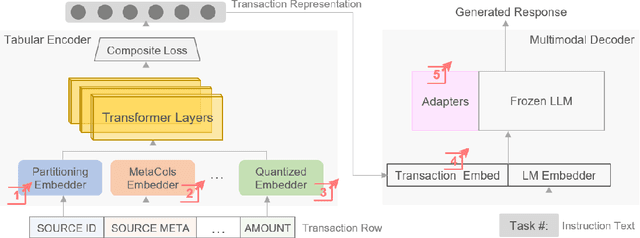
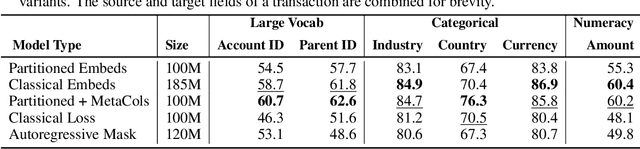
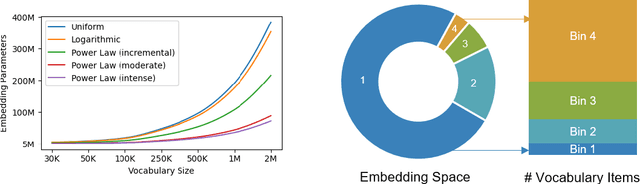
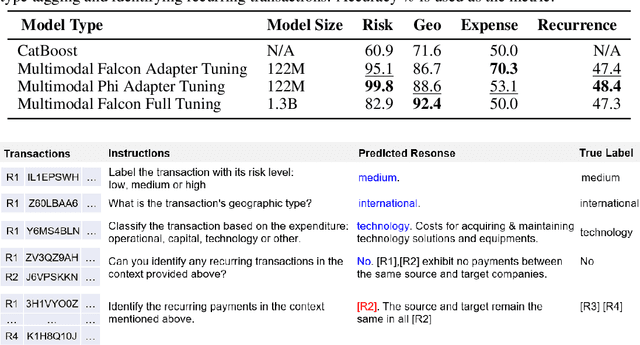
Large language models (LLMs) are primarily designed to understand unstructured text. When directly applied to structured formats such as tabular data, they may struggle to discern inherent relationships and overlook critical patterns. While tabular representation learning methods can address some of these limitations, existing efforts still face challenges with sparse high-cardinality fields, precise numerical reasoning, and column-heavy tables. Furthermore, leveraging these learned representations for downstream tasks through a language based interface is not apparent. In this paper, we present an innovative and scalable solution to these challenges. Concretely, our approach introduces a multi-tier partitioning mechanism that utilizes power-law dynamics to handle large vocabularies, an adaptive quantization mechanism to impose priors on numerical continuity, and a distinct treatment of core-columns and meta-information columns. To facilitate instruction tuning on LLMs, we propose a parameter efficient decoder that interleaves transaction and text modalities using a series of adapter layers, thereby exploiting rich cross-task knowledge. We validate the efficacy of our solution on a large-scale dataset of synthetic payments transactions.
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Apr 09, 2024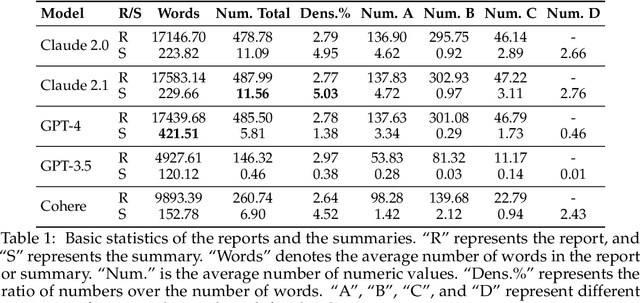
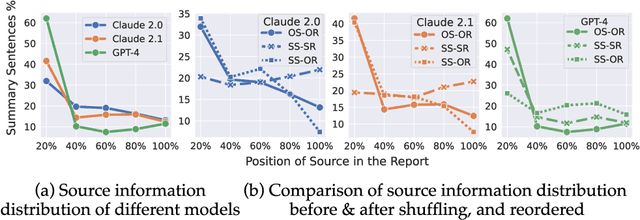
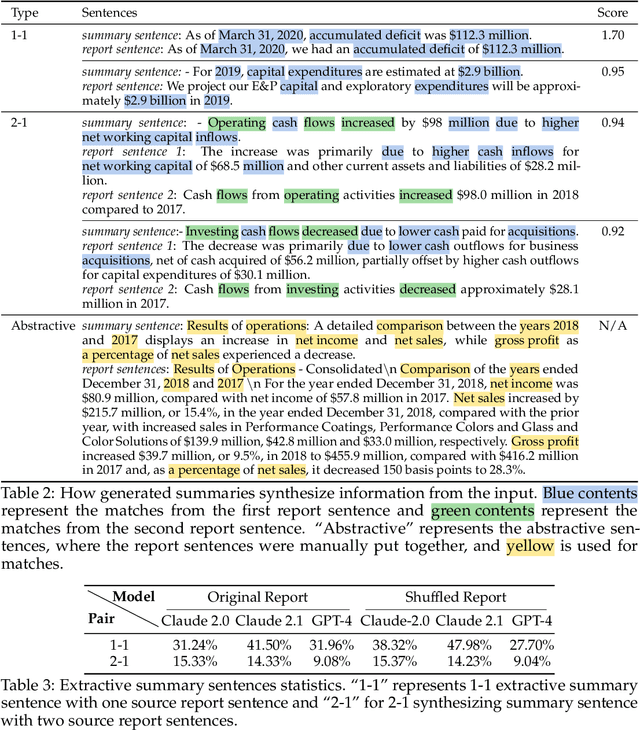

As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
DocLLM: A layout-aware generative language model for multimodal document understanding
Dec 31, 2023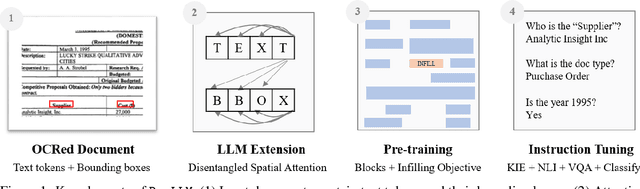

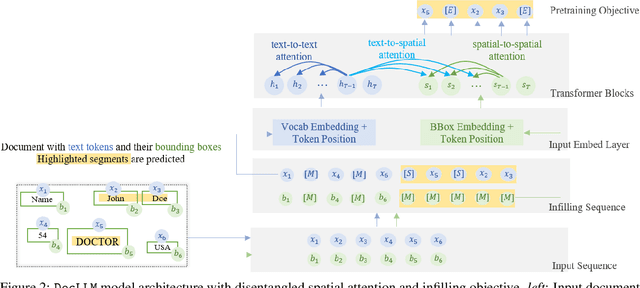
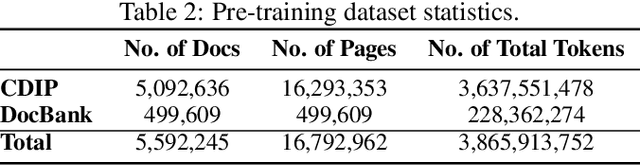
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Synthetic Text Generation using Hypergraph Representations
Sep 06, 2023Generating synthetic variants of a document is often posed as text-to-text transformation. We propose an alternate LLM based method that first decomposes a document into semantic frames and then generates text using this interim sparse format. The frames are modeled using a hypergraph, which allows perturbing the frame contents in a principled manner. Specifically, new hyperedges are mined through topological analysis and complex polyadic relationships including hierarchy and temporal dynamics are accommodated. We show that our solution generates documents that are diverse, coherent and vary in style, sentiment, format, composition and facts.
Bayesian Hierarchical Models for Counterfactual Estimation
Jan 21, 2023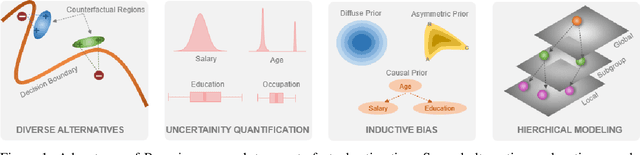
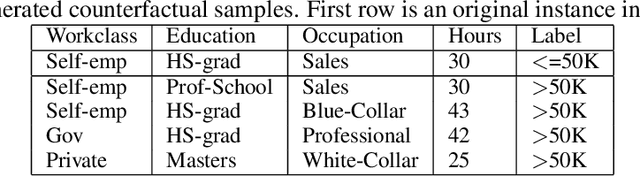
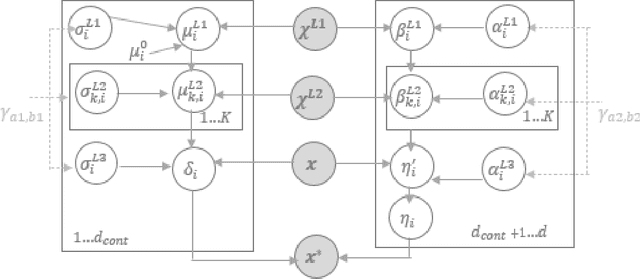
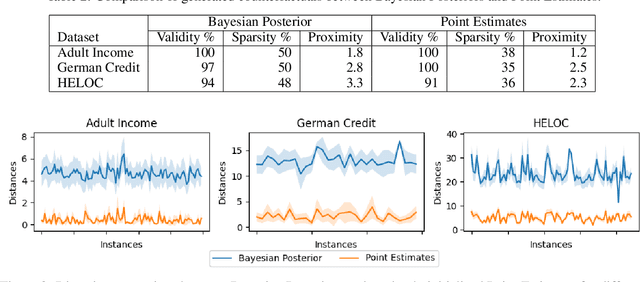
Counterfactual explanations utilize feature perturbations to analyze the outcome of an original decision and recommend an actionable recourse. We argue that it is beneficial to provide several alternative explanations rather than a single point solution and propose a probabilistic paradigm to estimate a diverse set of counterfactuals. Specifically, we treat the perturbations as random variables endowed with prior distribution functions. This allows sampling multiple counterfactuals from the posterior density, with the added benefit of incorporating inductive biases, preserving domain specific constraints and quantifying uncertainty in estimates. More importantly, we leverage Bayesian hierarchical modeling to share information across different subgroups of a population, which can both improve robustness and measure fairness. A gradient based sampler with superior convergence characteristics efficiently computes the posterior samples. Experiments across several datasets demonstrate that the counterfactuals estimated using our approach are valid, sparse, diverse and feasible.
WHEN FLUE MEETS FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain
Oct 31, 2022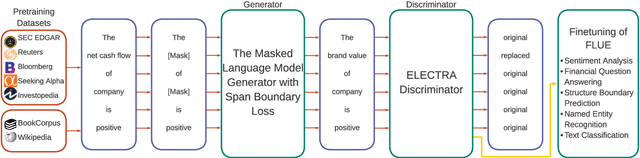
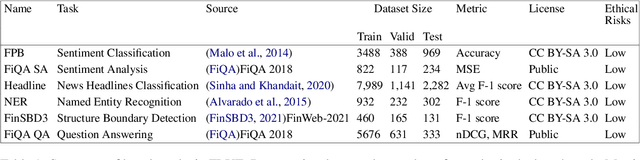
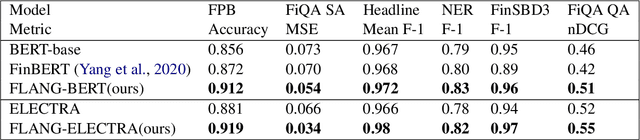
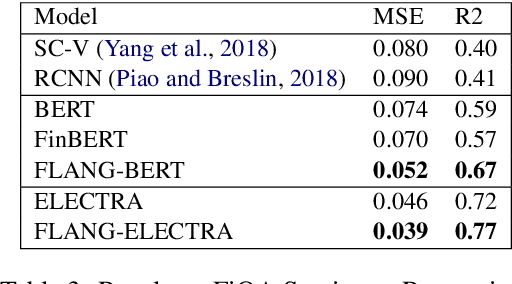
Pre-trained language models have shown impressive performance on a variety of tasks and domains. Previous research on financial language models usually employs a generic training scheme to train standard model architectures, without completely leveraging the richness of the financial data. We propose a novel domain specific Financial LANGuage model (FLANG) which uses financial keywords and phrases for better masking, together with span boundary objective and in-filing objective. Additionally, the evaluation benchmarks in the field have been limited. To this end, we contribute the Financial Language Understanding Evaluation (FLUE), an open-source comprehensive suite of benchmarks for the financial domain. These include new benchmarks across 5 NLP tasks in financial domain as well as common benchmarks used in the previous research. Experiments on these benchmarks suggest that our model outperforms those in prior literature on a variety of NLP tasks. Our models, code and benchmark data are publicly available on Github and Huggingface.