 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
WHEN FLUE MEETS FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain
Oct 31, 2022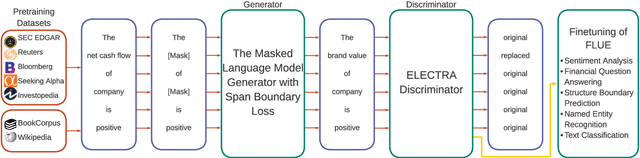
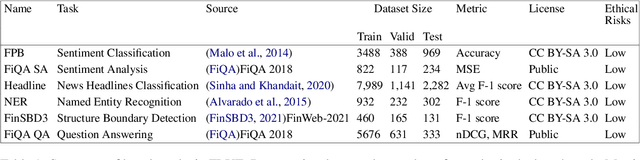
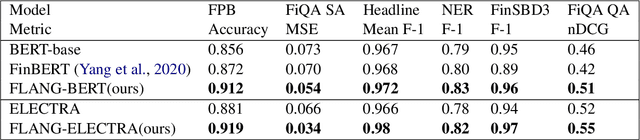
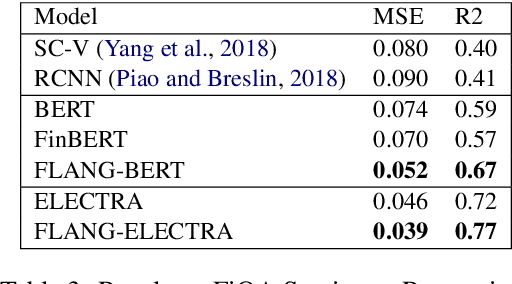
Pre-trained language models have shown impressive performance on a variety of tasks and domains. Previous research on financial language models usually employs a generic training scheme to train standard model architectures, without completely leveraging the richness of the financial data. We propose a novel domain specific Financial LANGuage model (FLANG) which uses financial keywords and phrases for better masking, together with span boundary objective and in-filing objective. Additionally, the evaluation benchmarks in the field have been limited. To this end, we contribute the Financial Language Understanding Evaluation (FLUE), an open-source comprehensive suite of benchmarks for the financial domain. These include new benchmarks across 5 NLP tasks in financial domain as well as common benchmarks used in the previous research. Experiments on these benchmarks suggest that our model outperforms those in prior literature on a variety of NLP tasks. Our models, code and benchmark data are publicly available on Github and Huggingface.
Semi-supervised Formality Style Transfer using Language Model Discriminator and Mutual Information Maximization
Oct 10, 2020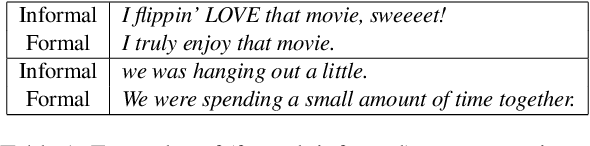
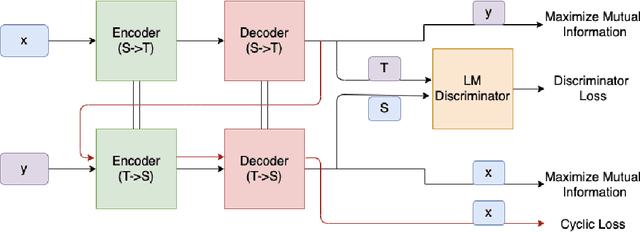


Formality style transfer is the task of converting informal sentences to grammatically-correct formal sentences, which can be used to improve performance of many downstream NLP tasks. In this work, we propose a semi-supervised formality style transfer model that utilizes a language model-based discriminator to maximize the likelihood of the output sentence being formal, which allows us to use maximization of token-level conditional probabilities for training. We further propose to maximize mutual information between source and target styles as our training objective instead of maximizing the regular likelihood that often leads to repetitive and trivial generated responses. Experiments showed that our model outperformed previous state-of-the-art baselines significantly in terms of both automated metrics and human judgement. We further generalized our model to unsupervised text style transfer task, and achieved significant improvements on two benchmark sentiment style transfer datasets.
Attention-based Ensemble for Deep Metric Learning
Aug 31, 2018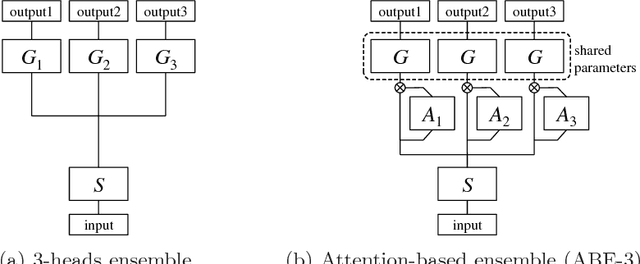
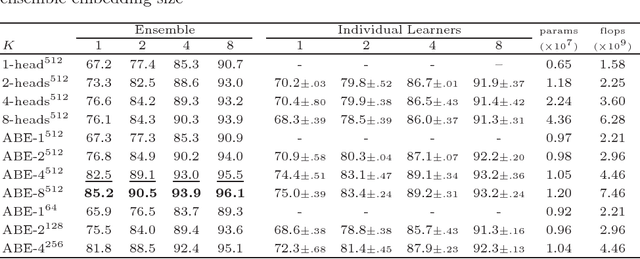
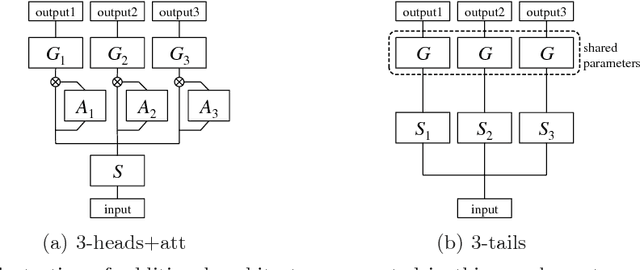

Deep metric learning aims to learn an embedding function, modeled as deep neural network. This embedding function usually puts semantically similar images close while dissimilar images far from each other in the learned embedding space. Recently, ensemble has been applied to deep metric learning to yield state-of-the-art results. As one important aspect of ensemble, the learners should be diverse in their feature embeddings. To this end, we propose an attention-based ensemble, which uses multiple attention masks, so that each learner can attend to different parts of the object. We also propose a divergence loss, which encourages diversity among the learners. The proposed method is applied to the standard benchmarks of deep metric learning and experimental results show that it outperforms the state-of-the-art methods by a significant margin on image retrieval tasks.
Classification of Flames in Computer Mediated Communications
Feb 17, 2012
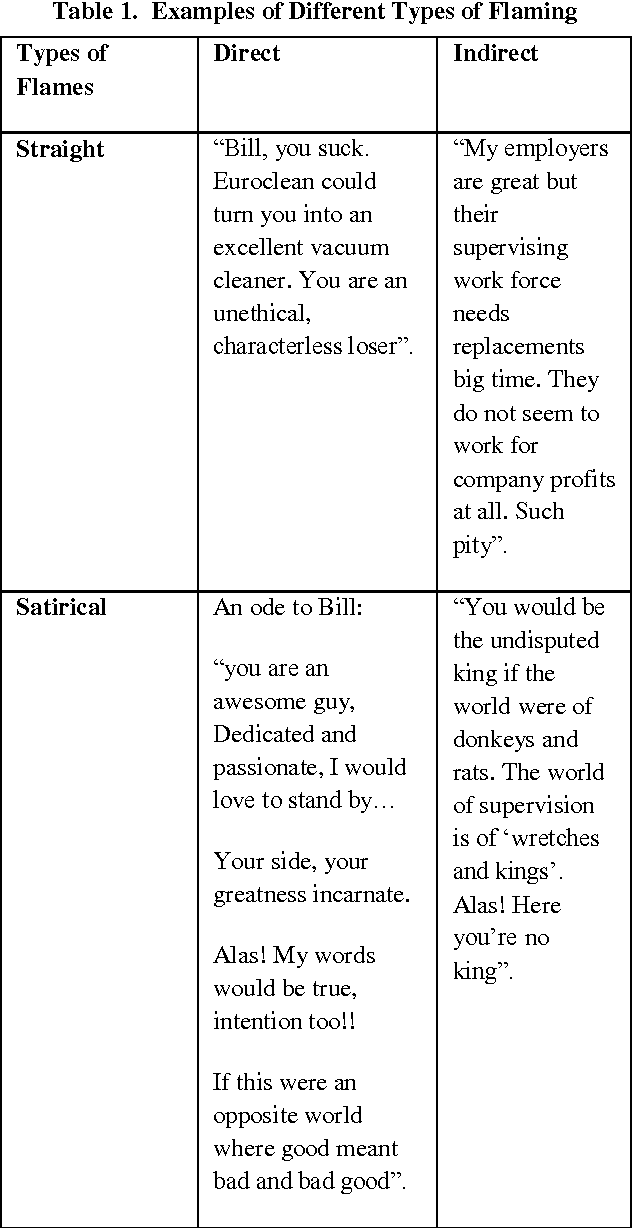
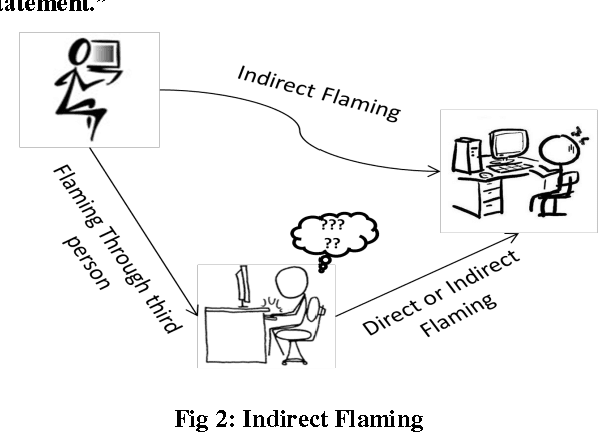
Computer Mediated Communication (CMC) has brought about a revolution in the way the world communicates with each other. With the increasing number of people, interacting through the internet and the rise of new platforms and technologies has brought together the people from different social, cultural and geographical backgrounds to present their thoughts, ideas and opinions on topics of their interest. CMC has, in some cases, gave users more freedom to express themselves as compared to Face-to-face communication. This has also led to rise in the use of hostile and aggressive language and terminologies uninhibitedly. Since such use of language is detrimental to the discussion process and affects the audience and individuals negatively, efforts are being taken to control them. The research sees the need to understand the concept of flaming and hence attempts to classify them in order to give a better understanding of it. The classification is done on the basis of type of flame content being presented and the Style in which they are presented.
* 6 pages, 4 figures