 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Claim Detection in Finance: A New Financial Dataset, Weak-Supervision Model, and Market Analysis
Feb 18, 2024In this paper, we investigate the influence of claims in analyst reports and earnings calls on financial market returns, considering them as significant quarterly events for publicly traded companies. To facilitate a comprehensive analysis, we construct a new financial dataset for the claim detection task in the financial domain. We benchmark various language models on this dataset and propose a novel weak-supervision model that incorporates the knowledge of subject matter experts (SMEs) in the aggregation function, outperforming existing approaches. Furthermore, we demonstrate the practical utility of our proposed model by constructing a novel measure ``optimism". Furthermore, we observed the dependence of earnings surprise and return on our optimism measure. Our dataset, models, and code will be made publicly (under CC BY 4.0 license) available on GitHub and Hugging Face.
WHEN FLUE MEETS FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain
Oct 31, 2022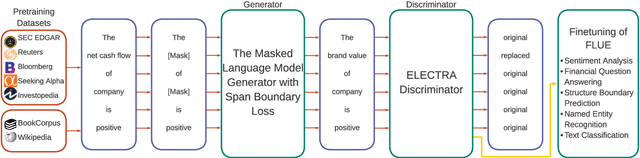
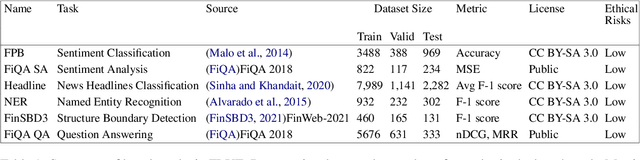
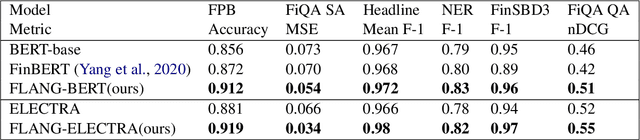
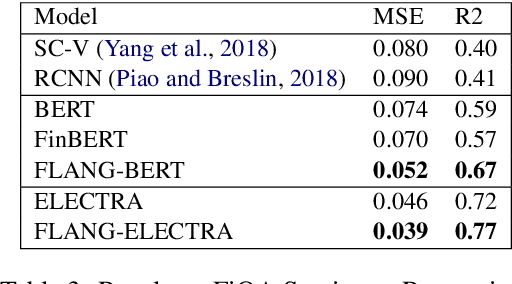
Pre-trained language models have shown impressive performance on a variety of tasks and domains. Previous research on financial language models usually employs a generic training scheme to train standard model architectures, without completely leveraging the richness of the financial data. We propose a novel domain specific Financial LANGuage model (FLANG) which uses financial keywords and phrases for better masking, together with span boundary objective and in-filing objective. Additionally, the evaluation benchmarks in the field have been limited. To this end, we contribute the Financial Language Understanding Evaluation (FLUE), an open-source comprehensive suite of benchmarks for the financial domain. These include new benchmarks across 5 NLP tasks in financial domain as well as common benchmarks used in the previous research. Experiments on these benchmarks suggest that our model outperforms those in prior literature on a variety of NLP tasks. Our models, code and benchmark data are publicly available on Github and Huggingface.