 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good is Zero-Shot MT Evaluation for Low Resource Indian Languages?
Jun 06, 2024While machine translation evaluation has been studied primarily for high-resource languages, there has been a recent interest in evaluation for low-resource languages due to the increasing availability of data and models. In this paper, we focus on a zero-shot evaluation setting focusing on low-resource Indian languages, namely Assamese, Kannada, Maithili, and Punjabi. We collect sufficient Multi-Dimensional Quality Metrics (MQM) and Direct Assessment (DA) annotations to create test sets and meta-evaluate a plethora of automatic evaluation metrics. We observe that even for learned metrics, which are known to exhibit zero-shot performance, the Kendall Tau and Pearson correlations with human annotations are only as high as 0.32 and 0.45. Synthetic data approaches show mixed results and overall do not help close the gap by much for these languages. This indicates that there is still a long way to go for low-resource evaluation.
Numerical Claim Detection in Finance: A New Financial Dataset, Weak-Supervision Model, and Market Analysis
Feb 18, 2024

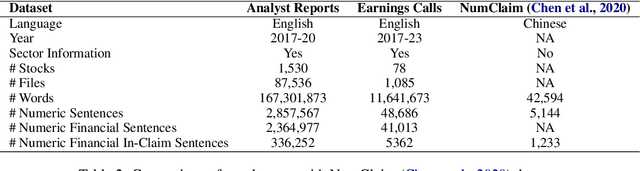

In this paper, we investigate the influence of claims in analyst reports and earnings calls on financial market returns, considering them as significant quarterly events for publicly traded companies. To facilitate a comprehensive analysis, we construct a new financial dataset for the claim detection task in the financial domain. We benchmark various language models on this dataset and propose a novel weak-supervision model that incorporates the knowledge of subject matter experts (SMEs) in the aggregation function, outperforming existing approaches. Furthermore, we demonstrate the practical utility of our proposed model by constructing a novel measure ``optimism". Furthermore, we observed the dependence of earnings surprise and return on our optimism measure. Our dataset, models, and code will be made publicly (under CC BY 4.0 license) available on GitHub and Hugging Face.