 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicIFEval: A Benchmark for Verifiable Instruction-Following Evaluation in 14 Indic Languages
Feb 25, 2026Instruction-following benchmarks remain predominantly English-centric, leaving a critical evaluation gap for the hundreds of millions of Indic language speakers. We introduce IndicIFEval, a benchmark evaluating constrained generation of LLMs across 14 Indic languages using automatically verifiable, rule-based instructions. It comprises around 800 human-verified examples per language spread across two complementary subsets: IndicIFEval-Ground, translated prompts from IFEval (Zhou et al., 2023) carefully localized for Indic contexts, and IndicIFEval-Ground, synthetically generated instructions grounded in native Indic content. We conduct a comprehensive evaluation of major open-weight and proprietary models spanning both reasoning and non-reasoning models. While models maintain strong adherence to formatting constraints, they struggle significantly with lexical and cross-lingual tasks -- and despite progress in high-resource languages, instruction-following across the broader Indic family lags significantly behind English. We release IndicIFEval and its evaluation scripts to support progress on multilingual constrained generation (http://github.com/ai4bharat/IndicIFEval).
The Reasoning Lingua Franca: A Double-Edged Sword for Multilingual AI
Oct 23, 2025Large Reasoning Models (LRMs) achieve strong performance on mathematical, scientific, and other question-answering tasks, but their multilingual reasoning abilities remain underexplored. When presented with non-English questions, LRMs often default to reasoning in English, raising concerns about interpretability and the handling of linguistic and cultural nuances. We systematically compare an LRM's reasoning in English versus the language of the question. Our evaluation spans two tasks: MGSM and GPQA Diamond. Beyond measuring answer accuracy, we also analyze cognitive attributes in the reasoning traces. We find that English reasoning traces exhibit a substantially higher presence of these cognitive behaviors, and that reasoning in English generally yields higher final-answer accuracy, with the performance gap increasing as tasks become more complex. However, this English-centric strategy is susceptible to a key failure mode - getting "Lost in Translation," where translation steps lead to errors that would have been avoided by question's language reasoning.
RomanLens: Latent Romanization and its role in Multilinguality in LLMs
Feb 11, 2025Large Language Models (LLMs) exhibit remarkable multilingual generalization despite being predominantly trained on English-centric corpora. A fundamental question arises: how do LLMs achieve such robust multilingual capabilities? For non-Latin script languages, we investigate the role of romanization - the representation of non-Latin scripts using Latin characters - as a bridge in multilingual processing. Using mechanistic interpretability techniques, we analyze next-token generation and find that intermediate layers frequently represent target words in romanized form before transitioning to native script, a phenomenon we term Latent Romanization. Further, through activation patching experiments, we demonstrate that LLMs encode semantic concepts similarly across native and romanized scripts, suggesting a shared underlying representation. Additionally in translation towards non Latin languages, our findings reveal that when the target language is in romanized form, its representations emerge earlier in the model's layers compared to native script. These insights contribute to a deeper understanding of multilingual representation in LLMs and highlight the implicit role of romanization in facilitating language transfer. Our work provides new directions for potentially improving multilingual language modeling and interpretability.
Pralekha: An Indic Document Alignment Evaluation Benchmark
Nov 28, 2024



Mining parallel document pairs poses a significant challenge because existing sentence embedding models often have limited context windows, preventing them from effectively capturing document-level information. Another overlooked issue is the lack of concrete evaluation benchmarks comprising high-quality parallel document pairs for assessing document-level mining approaches, particularly for Indic languages. In this study, we introduce Pralekha, a large-scale benchmark for document-level alignment evaluation. Pralekha includes over 2 million documents, with a 1:2 ratio of unaligned to aligned pairs, covering 11 Indic languages and English. Using Pralekha, we evaluate various document-level mining approaches across three dimensions: the embedding models, the granularity levels, and the alignment algorithm. To address the challenge of aligning documents using sentence and chunk-level alignments, we propose a novel scoring method, Document Alignment Coefficient (DAC). DAC demonstrates substantial improvements over baseline pooling approaches, particularly in noisy scenarios, achieving average gains of 20-30% in precision and 15-20% in F1 score. These results highlight DAC's effectiveness in parallel document mining for Indic languages.
BhasaAnuvaad: A Speech Translation Dataset for 14 Indian Languages
Nov 07, 2024



Automatic Speech Translation (AST) datasets for Indian languages remain critically scarce, with public resources covering fewer than 10 of the 22 official languages. This scarcity has resulted in AST systems for Indian languages lagging far behind those available for high-resource languages like English. In this paper, we first evaluate the performance of widely-used AST systems on Indian languages, identifying notable performance gaps and challenges. Our findings show that while these systems perform adequately on read speech, they struggle significantly with spontaneous speech, including disfluencies like pauses and hesitations. Additionally, there is a striking absence of systems capable of accurately translating colloquial and informal language, a key aspect of everyday communication. To this end, we introduce BhasaAnuvaad, the largest publicly available dataset for AST involving 14 scheduled Indian languages spanning over 44,400 hours and 17M text segments. BhasaAnuvaad contains data for English speech to Indic text, as well as Indic speech to English text. This dataset comprises three key categories: (1) Curated datasets from existing resources, (2) Large-scale web mining, and (3) Synthetic data generation. By offering this diverse and expansive dataset, we aim to bridge the resource gap and promote advancements in AST for low-resource Indian languages, especially in handling spontaneous and informal speech patterns.
Cross-Lingual Auto Evaluation for Assessing Multilingual LLMs
Oct 17, 2024


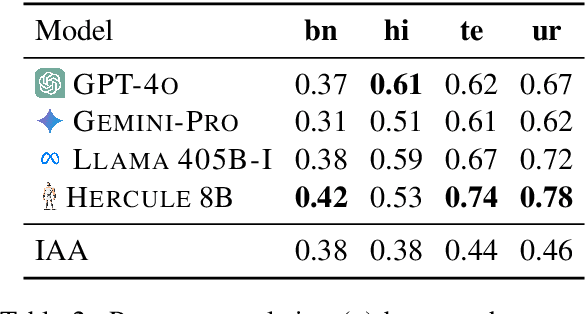
Evaluating machine-generated text remains a significant challenge in NLP, especially for non-English languages. Current methodologies, including automated metrics, human assessments, and LLM-based evaluations, predominantly focus on English, revealing a significant gap in multilingual evaluation frameworks. We introduce the Cross Lingual Auto Evaluation (CIA) Suite, an extensible framework that includes evaluator LLMs (Hercule) and a novel test set (Recon) specifically designed for multilingual evaluation. Our test set features 500 human-annotated instructions spanning various task capabilities along with human judgment scores across six languages. This would enable benchmarking of general-purpose multilingual LLMs and facilitate meta-evaluation of Evaluator LLMs. The proposed model, Hercule, is a cross-lingual evaluation model that addresses the scarcity of reference answers in the target language by learning to assign scores to responses based on easily available reference answers in English. Our experiments demonstrate that Hercule aligns more closely with human judgments compared to proprietary models, demonstrating the effectiveness of such cross-lingual evaluation in low resource scenarios. Further, it is also effective in zero-shot evaluation on unseen languages. This study is the first comprehensive examination of cross-lingual evaluation using LLMs, presenting a scalable and effective approach for multilingual assessment. All code, datasets, and models will be publicly available to enable further research in this important area.
An Empirical Comparison of Vocabulary Expansion and Initialization Approaches for Language Models
Jul 08, 2024



Language Models (LMs) excel in natural language processing tasks for English but show reduced performance in most other languages. This problem is commonly tackled by continually pre-training and fine-tuning these models for said languages. A significant issue in this process is the limited vocabulary coverage in the original model's tokenizer, leading to inadequate representation of new languages and necessitating an expansion of the tokenizer. The initialization of the embeddings corresponding to new vocabulary items presents a further challenge. Current strategies require cross-lingual embeddings and lack a solid theoretical foundation as well as comparisons with strong baselines. In this paper, we first establish theoretically that initializing within the convex hull of existing embeddings is a good initialization, followed by a novel but simple approach, Constrained Word2Vec (CW2V), which does not require cross-lingual embeddings. Our study evaluates different initialization methods for expanding RoBERTa and LLaMA 2 across four languages and five tasks. The results show that CW2V performs equally well or even better than more advanced techniques. Additionally, simpler approaches like multivariate initialization perform on par with these advanced methods indicating that efficient large-scale multilingual continued pretraining can be achieved even with simpler initialization methods.
How Good is Zero-Shot MT Evaluation for Low Resource Indian Languages?
Jun 06, 2024While machine translation evaluation has been studied primarily for high-resource languages, there has been a recent interest in evaluation for low-resource languages due to the increasing availability of data and models. In this paper, we focus on a zero-shot evaluation setting focusing on low-resource Indian languages, namely Assamese, Kannada, Maithili, and Punjabi. We collect sufficient Multi-Dimensional Quality Metrics (MQM) and Direct Assessment (DA) annotations to create test sets and meta-evaluate a plethora of automatic evaluation metrics. We observe that even for learned metrics, which are known to exhibit zero-shot performance, the Kendall Tau and Pearson correlations with human annotations are only as high as 0.32 and 0.45. Synthetic data approaches show mixed results and overall do not help close the gap by much for these languages. This indicates that there is still a long way to go for low-resource evaluation.
Synthetic Data Generation and Joint Learning for Robust Code-Mixed Translation
Mar 25, 2024The widespread online communication in a modern multilingual world has provided opportunities to blend more than one language (aka code-mixed language) in a single utterance. This has resulted a formidable challenge for the computational models due to the scarcity of annotated data and presence of noise. A potential solution to mitigate the data scarcity problem in low-resource setup is to leverage existing data in resource-rich language through translation. In this paper, we tackle the problem of code-mixed (Hinglish and Bengalish) to English machine translation. First, we synthetically develop HINMIX, a parallel corpus of Hinglish to English, with ~4.2M sentence pairs. Subsequently, we propose RCMT, a robust perturbation based joint-training model that learns to handle noise in the real-world code-mixed text by parameter sharing across clean and noisy words. Further, we show the adaptability of RCMT in a zero-shot setup for Bengalish to English translation. Our evaluation and comprehensive analyses qualitatively and quantitatively demonstrate the superiority of RCMT over state-of-the-art code-mixed and robust translation methods.
IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.