 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMark My Words: A Robust Multilingual Model for Punctuation in Text and Speech Transcripts
Jun 04, 2025



Punctuation plays a vital role in structuring meaning, yet current models often struggle to restore it accurately in transcripts of spontaneous speech, especially in the presence of disfluencies such as false starts and backtracking. These limitations hinder the performance of downstream tasks like translation, text to speech, summarization, etc. where sentence boundaries are critical for preserving quality. In this work, we introduce Cadence, a generalist punctuation restoration model adapted from a pretrained large language model. Cadence is designed to handle both clean written text and highly spontaneous spoken transcripts. It surpasses the previous state of the art in performance while expanding support from 14 to all 22 Indian languages and English. We conduct a comprehensive analysis of model behavior across punctuation types and language families, identifying persistent challenges under domain shift and with rare punctuation marks. Our findings demonstrate the efficacy of utilizing pretrained language models for multilingual punctuation restoration and highlight Cadence practical value for low resource NLP pipelines at scale.
BhasaAnuvaad: A Speech Translation Dataset for 14 Indian Languages
Nov 07, 2024



Automatic Speech Translation (AST) datasets for Indian languages remain critically scarce, with public resources covering fewer than 10 of the 22 official languages. This scarcity has resulted in AST systems for Indian languages lagging far behind those available for high-resource languages like English. In this paper, we first evaluate the performance of widely-used AST systems on Indian languages, identifying notable performance gaps and challenges. Our findings show that while these systems perform adequately on read speech, they struggle significantly with spontaneous speech, including disfluencies like pauses and hesitations. Additionally, there is a striking absence of systems capable of accurately translating colloquial and informal language, a key aspect of everyday communication. To this end, we introduce BhasaAnuvaad, the largest publicly available dataset for AST involving 14 scheduled Indian languages spanning over 44,400 hours and 17M text segments. BhasaAnuvaad contains data for English speech to Indic text, as well as Indic speech to English text. This dataset comprises three key categories: (1) Curated datasets from existing resources, (2) Large-scale web mining, and (3) Synthetic data generation. By offering this diverse and expansive dataset, we aim to bridge the resource gap and promote advancements in AST for low-resource Indian languages, especially in handling spontaneous and informal speech patterns.
IndicLLMSuite: A Blueprint for Creating Pre-training and Fine-Tuning Datasets for Indian Languages
Mar 11, 2024Despite the considerable advancements in English LLMs, the progress in building comparable models for other languages has been hindered due to the scarcity of tailored resources. Our work aims to bridge this divide by introducing an expansive suite of resources specifically designed for the development of Indic LLMs, covering 22 languages, containing a total of 251B tokens and 74.8M instruction-response pairs. Recognizing the importance of both data quality and quantity, our approach combines highly curated manually verified data, unverified yet valuable data, and synthetic data. We build a clean, open-source pipeline for curating pre-training data from diverse sources, including websites, PDFs, and videos, incorporating best practices for crawling, cleaning, flagging, and deduplication. For instruction-fine tuning, we amalgamate existing Indic datasets, translate/transliterate English datasets into Indian languages, and utilize LLaMa2 and Mixtral models to create conversations grounded in articles from Indian Wikipedia and Wikihow. Additionally, we address toxicity alignment by generating toxic prompts for multiple scenarios and then generate non-toxic responses by feeding these toxic prompts to an aligned LLaMa2 model. We hope that the datasets, tools, and resources released as a part of this work will not only propel the research and development of Indic LLMs but also establish an open-source blueprint for extending such efforts to other languages. The data and other artifacts created as part of this work are released with permissive licenses.
Kinematic Characterization of Micro-Mobility Vehicles During Evasive Maneuvers
Dec 22, 2023There is an increasing need to comprehensively characterize the kinematic performances of different Micromobility Vehicles (MMVs). This study aims to: 1) characterize the kinematic behaviors of different MMVs during emergency maneuvers; 2) explore the influence of different MMV power sources on the device performances; 3) investigate if piecewise linear models are suitable for modeling MMV trajectories. A test track experiment where 40 frequent riders performed emergency braking and swerving maneuvers riding a subset of electric MMVs, their traditional counterparts, and, in some cases, behaving as running pedestrians. A second experiment was conducted to determine the MMVs swerving lower boundaries. Device power source resulted having a statistically significant influence on kinematic capabilities of the MMVs: while e-MMVs displayed superior braking capabilities compared to their traditional counterparts, the opposite was observed in terms of swerving performance. Furthermore, performances varied significantly across the different MMV typologies, with handlebar-based devices consistently outperforming the handlebar-less devices across the metrics considered. The piecewise linear models used for braking profiles fit well for most MMVs, except for skateboards and pedestrians due to foot-ground engagement. These findings underscore that the effectiveness of steering or braking in preventing collisions may vary depending on the type and power source of the device. This study also demonstrates the applicability of piecewise linear models for generating parameterized functions that accurately model braking trajectories, providing a valuable resource for automated systems developers. The model, however, also reveals that the single brake ramp assumption does not apply for certain types of MMVs or for pedestrians, indicating the necessity for further improvements.
PhishMatch: A Layered Approach for Effective Detection of Phishing URLs
Dec 04, 2021

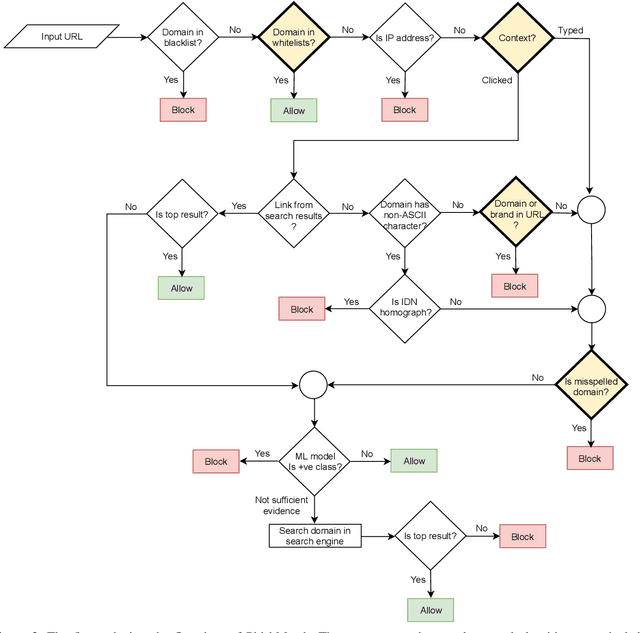
Phishing attacks continue to be a significant threat on the Internet. Prior studies show that it is possible to determine whether a website is phishing or not just by analyzing its URL more carefully. A major advantage of the URL based approach is that it can identify a phishing website even before the web page is rendered in the browser, thus avoiding other potential problems such as cryptojacking and drive-by downloads. However, traditional URL based approaches have their limitations. Blacklist based approaches are prone to zero-hour phishing attacks, advanced machine learning based approaches consume high resources, and other approaches send the URL to a remote server which compromises user's privacy. In this paper, we present a layered anti-phishing defense, PhishMatch, which is robust, accurate, inexpensive, and client-side. We design a space-time efficient Aho-Corasick algorithm for exact string matching and n-gram based indexing technique for approximate string matching to detect various cybersquatting techniques in the phishing URL. To reduce false positives, we use a global whitelist and personalized user whitelists. We also determine the context in which the URL is visited and use that information to classify the input URL more accurately. The last component of PhishMatch involves a machine learning model and controlled search engine queries to classify the URL. A prototype plugin of PhishMatch, developed for the Chrome browser, was found to be fast and lightweight. Our evaluation shows that PhishMatch is both efficient and effective.
Statistical Guarantees for Fairness Aware Plug-In Algorithms
Jul 27, 2021
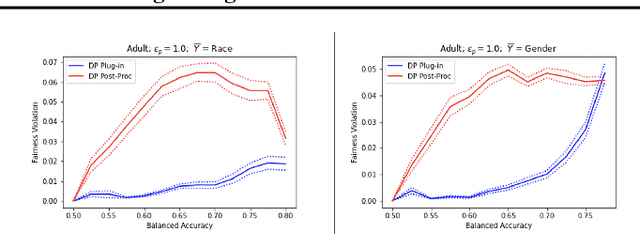

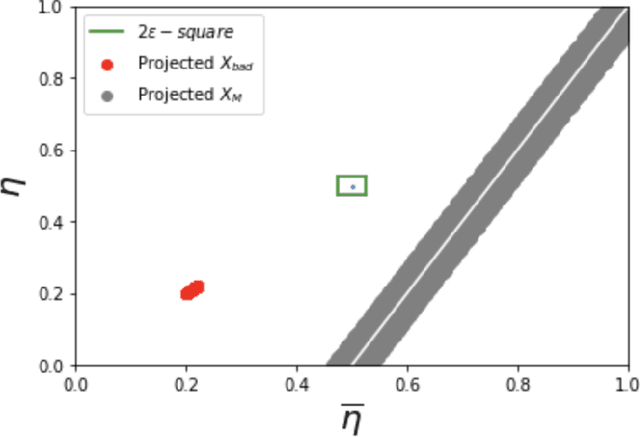
A plug-in algorithm to estimate Bayes Optimal Classifiers for fairness-aware binary classification has been proposed in (Menon & Williamson, 2018). However, the statistical efficacy of their approach has not been established. We prove that the plug-in algorithm is statistically consistent. We also derive finite sample guarantees associated with learning the Bayes Optimal Classifiers via the plug-in algorithm. Finally, we propose a protocol that modifies the plug-in approach, so as to simultaneously guarantee fairness and differential privacy with respect to a binary feature deemed sensitive.