 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishMatch: A Layered Approach for Effective Detection of Phishing URLs
Dec 04, 2021

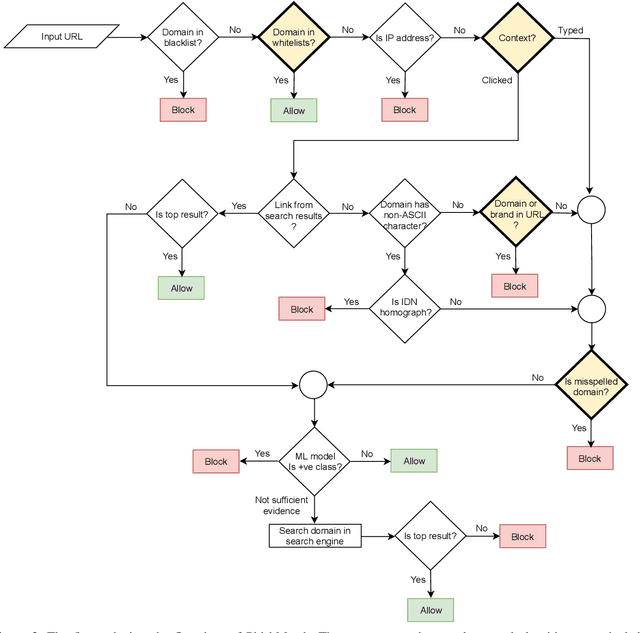
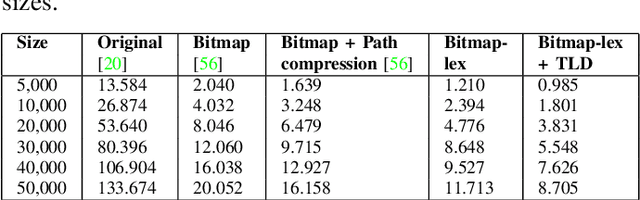
Phishing attacks continue to be a significant threat on the Internet. Prior studies show that it is possible to determine whether a website is phishing or not just by analyzing its URL more carefully. A major advantage of the URL based approach is that it can identify a phishing website even before the web page is rendered in the browser, thus avoiding other potential problems such as cryptojacking and drive-by downloads. However, traditional URL based approaches have their limitations. Blacklist based approaches are prone to zero-hour phishing attacks, advanced machine learning based approaches consume high resources, and other approaches send the URL to a remote server which compromises user's privacy. In this paper, we present a layered anti-phishing defense, PhishMatch, which is robust, accurate, inexpensive, and client-side. We design a space-time efficient Aho-Corasick algorithm for exact string matching and n-gram based indexing technique for approximate string matching to detect various cybersquatting techniques in the phishing URL. To reduce false positives, we use a global whitelist and personalized user whitelists. We also determine the context in which the URL is visited and use that information to classify the input URL more accurately. The last component of PhishMatch involves a machine learning model and controlled search engine queries to classify the URL. A prototype plugin of PhishMatch, developed for the Chrome browser, was found to be fast and lightweight. Our evaluation shows that PhishMatch is both efficient and effective.
Gradient-based Data Subversion Attack Against Binary Classifiers
May 31, 2021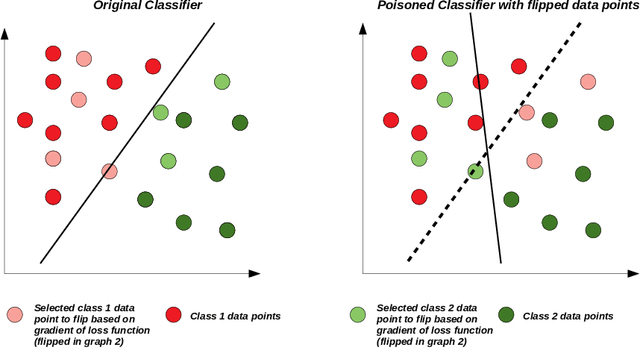
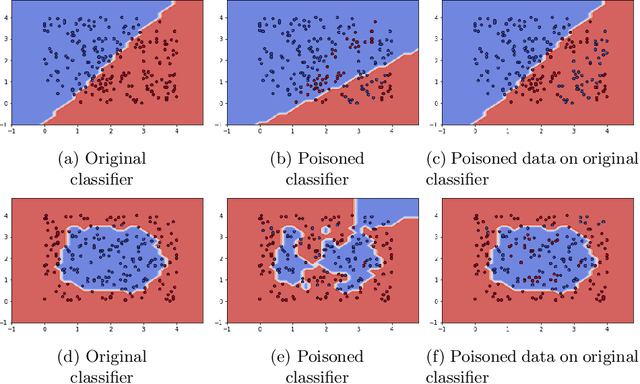
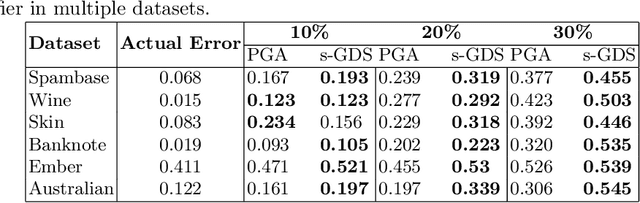
Machine learning based data-driven technologies have shown impressive performances in a variety of application domains. Most enterprises use data from multiple sources to provide quality applications. The reliability of the external data sources raises concerns for the security of the machine learning techniques adopted. An attacker can tamper the training or test datasets to subvert the predictions of models generated by these techniques. Data poisoning is one such attack wherein the attacker tries to degrade the performance of a classifier by manipulating the training data. In this work, we focus on label contamination attack in which an attacker poisons the labels of data to compromise the functionality of the system. We develop Gradient-based Data Subversion strategies to achieve model degradation under the assumption that the attacker has limited-knowledge of the victim model. We exploit the gradients of a differentiable convex loss function (residual errors) with respect to the predicted label as a warm-start and formulate different strategies to find a set of data instances to contaminate. Further, we analyze the transferability of attacks and the susceptibility of binary classifiers. Our experiments show that the proposed approach outperforms the baselines and is computationally efficient.
Influence Based Defense Against Data Poisoning Attacks in Online Learning
Apr 24, 2021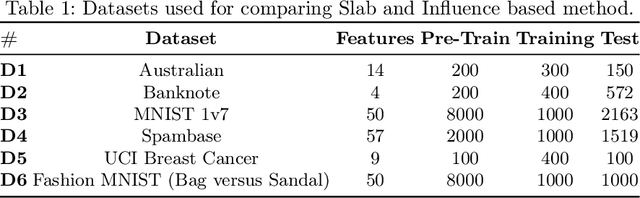
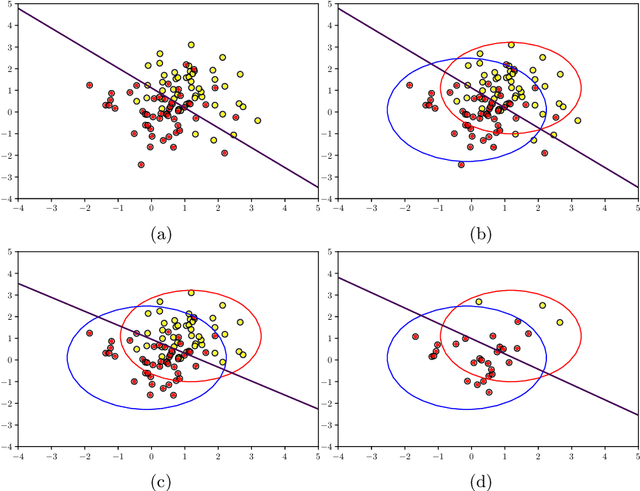
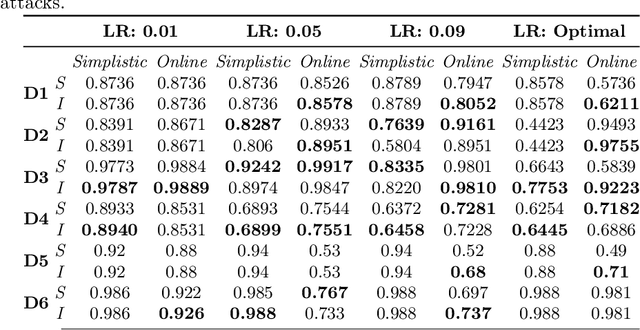
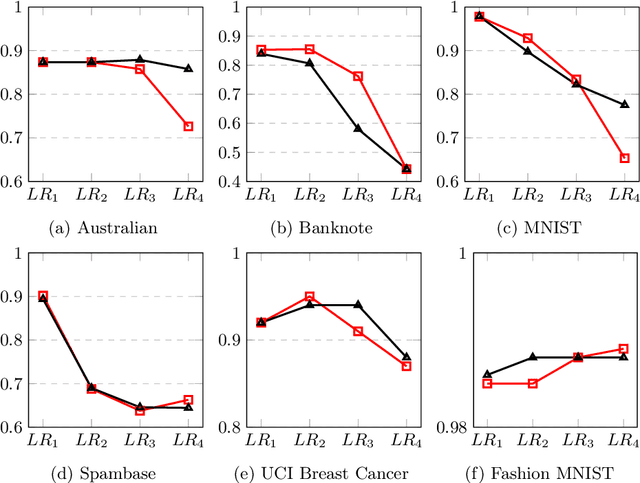
Data poisoning is a type of adversarial attack on training data where an attacker manipulates a fraction of data to degrade the performance of machine learning model. Therefore, applications that rely on external data-sources for training data are at a significantly higher risk. There are several known defensive mechanisms that can help in mitigating the threat from such attacks. For example, data sanitization is a popular defensive mechanism wherein the learner rejects those data points that are sufficiently far from the set of training instances. Prior work on data poisoning defense primarily focused on offline setting, wherein all the data is assumed to be available for analysis. Defensive measures for online learning, where data points arrive sequentially, have not garnered similar interest. In this work, we propose a defense mechanism to minimize the degradation caused by the poisoned training data on a learner's model in an online setup. Our proposed method utilizes an influence function which is a classic technique in robust statistics. Further, we supplement it with the existing data sanitization methods for filtering out some of the poisoned data points. We study the effectiveness of our defense mechanism on multiple datasets and across multiple attack strategies against an online learner.
Privacy Guidelines for Contact Tracing Applications
Apr 28, 2020Contact tracing is a very powerful method to implement and enforce social distancing to avoid spreading of infectious diseases. The traditional approach of contact tracing is time consuming, manpower intensive, dangerous and prone to error due to fatigue or lack of skill. Due to this there is an emergence of mobile based applications for contact tracing. These applications primarily utilize a combination of GPS based absolute location and Bluetooth based relative location remitted from user's smartphone to infer various insights. These applications have eased the task of contact tracing; however, they also have severe implication on user's privacy, for example, mass surveillance, personal information leakage and additionally revealing the behavioral patterns of the user. This impact on user's privacy leads to trust deficit in these applications, and hence defeats their purpose. In this work we discuss the various scenarios which a contact tracing application should be able to handle. We highlight the privacy handling of some of the prominent contact tracing applications. Additionally, we describe the various threat actors who can disrupt its working, or misuse end user's data, or hamper its mass adoption. Finally, we present privacy guidelines for contact tracing applications from different stakeholder's perspective. To best of our knowledge, this is the first generic work which provides privacy guidelines for contact tracing applications.
Stamp processing with examplar features
Sep 16, 2016


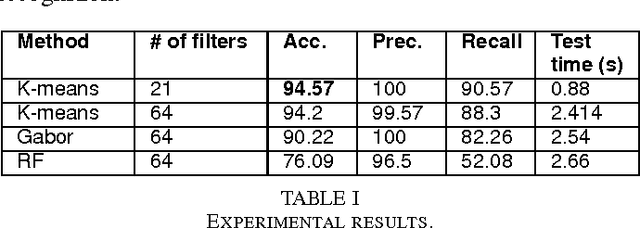
Document digitization is becoming increasingly crucial. In this work, we propose a shape based approach for automatic stamp verification/detection in document images using an unsupervised feature learning. Given a small set of training images, our algorithm learns an appropriate shape representation using an unsupervised clustering. Experimental results demonstrate the effectiveness of our framework in challenging scenarios.