 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolaris: A Gödel Agent Framework for Small Language Models through Experience-Abstracted Policy Repair
Mar 24, 2026Gödel agent realize recursive self-improvement: an agent inspects its own policy and traces and then modifies that policy in a tested loop. We introduce Polaris, a Gödel agent for compact models that performs policy repair via experience abstraction, turning failures into policy updates through a structured cycle of analysis, strategy formation, abstraction, and minimal code pat ch repair with conservative checks. Unlike response level self correction or parameter tuning, Polaris makes policy level changes with small, auditable patches that persist in the policy and are reused on unseen instances within each benchmark. As part of the loop, the agent engages in meta reasoning: it explains its errors, proposes concrete revisions to its own policy, and then updates the policy. To enable cumulative policy refinement, we introduce experience abstraction, which distills failures into compact, reusable strategies that transfer to unseen instances. On MGSM, DROP, GPQA, and LitBench (covering arithmetic reasoning, compositional inference, graduate-level problem solving, and creative writing evaluation), a 7-billion-parameter model equipped with Polaris achieves consistent gains over the base policy and competitive baselines.
Forgetting is Competition: Rethinking Unlearning as Representation Interference in Diffusion Models
Mar 01, 2026Unlearning in text-to-image diffusion models often leads to uneven concept removal and unintended forgetting of unrelated capabilities. This complicates tasks such as copyright compliance, protected data mitigation, artist opt-outs, and policy-driven content updates. As models grow larger and adopt more diverse architectures, achieving precise and selective unlearning while preserving generative quality becomes increasingly challenging. We introduce SurgUn (pronounced as Surgeon), a surgical unlearning method that applies targeted weight-space updates to remove specific visual concepts in text-conditioned diffusion models. Our approach is motivated by retroactive interference theory, which holds that newly acquired memories can overwrite, suppress, or impede access to prior ones by competing for shared representational pathways. We adapt this principle to diffusion models by inducing retroactive concept interference, enabling focused destabilization of only the target concept while preserving unrelated capabilities through a novel training paradigm. SurgUn achieves high-precision unlearning across diverse settings. It performs strongly on compact U-Net based models such as Stable Diffusion v1.5, scales effectively to the larger U-Net architecture SDXL, and extends to SANA, representing an underexplored Diffusion Transformer based architecture for unlearning.
Quality Detection of Stored Potatoes via Transfer Learning: A CNN and Vision Transformer Approach
Jan 02, 2026Image-based deep learning provides a non-invasive, scalable solution for monitoring potato quality during storage, addressing key challenges such as sprout detection, weight loss estimation, and shelf-life prediction. In this study, images and corresponding weight data were collected over a 200-day period under controlled temperature and humidity conditions. Leveraging powerful pre-trained architectures of ResNet, VGG, DenseNet, and Vision Transformer (ViT), we designed two specialized models: (1) a high-precision binary classifier for sprout detection, and (2) an advanced multi-class predictor to estimate weight loss and forecast remaining shelf-life with remarkable accuracy. DenseNet achieved exceptional performance, with 98.03% accuracy in sprout detection. Shelf-life prediction models performed best with coarse class divisions (2-5 classes), achieving over 89.83% accuracy, while accuracy declined for finer divisions (6-8 classes) due to subtle visual differences and limited data per class. These findings demonstrate the feasibility of integrating image-based models into automated sorting and inventory systems, enabling early identification of sprouted potatoes and dynamic categorization based on storage stage. Practical implications include improved inventory management, differential pricing strategies, and reduced food waste across supply chains. While predicting exact shelf-life intervals remains challenging, focusing on broader class divisions ensures robust performance. Future research should aim to develop generalized models trained on diverse potato varieties and storage conditions to enhance adaptability and scalability. Overall, this approach offers a cost-effective, non-destructive method for quality assessment, supporting efficiency and sustainability in potato storage and distribution.
OrgAccess: A Benchmark for Role Based Access Control in Organization Scale LLMs
May 25, 2025



Role-based access control (RBAC) and hierarchical structures are foundational to how information flows and decisions are made within virtually all organizations. As the potential of Large Language Models (LLMs) to serve as unified knowledge repositories and intelligent assistants in enterprise settings becomes increasingly apparent, a critical, yet under explored, challenge emerges: \textit{can these models reliably understand and operate within the complex, often nuanced, constraints imposed by organizational hierarchies and associated permissions?} Evaluating this crucial capability is inherently difficult due to the proprietary and sensitive nature of real-world corporate data and access control policies. We introduce a synthetic yet representative \textbf{OrgAccess} benchmark consisting of 40 distinct types of permissions commonly relevant across different organizational roles and levels. We further create three types of permissions: 40,000 easy (1 permission), 10,000 medium (3-permissions tuple), and 20,000 hard (5-permissions tuple) to test LLMs' ability to accurately assess these permissions and generate responses that strictly adhere to the specified hierarchical rules, particularly in scenarios involving users with overlapping or conflicting permissions. Our findings reveal that even state-of-the-art LLMs struggle significantly to maintain compliance with role-based structures, even with explicit instructions, with their performance degrades further when navigating interactions involving two or more conflicting permissions. Specifically, even \textbf{GPT-4.1 only achieves an F1-Score of 0.27 on our hardest benchmark}. This demonstrates a critical limitation in LLMs' complex rule following and compositional reasoning capabilities beyond standard factual or STEM-based benchmarks, opening up a new paradigm for evaluating their fitness for practical, structured environments.
Nine Ways to Break Copyright Law and Why Our LLM Won't: A Fair Use Aligned Generation Framework
May 25, 2025Large language models (LLMs) commonly risk copyright infringement by reproducing protected content verbatim or with insufficient transformative modifications, posing significant ethical, legal, and practical concerns. Current inference-time safeguards predominantly rely on restrictive refusal-based filters, often compromising the practical utility of these models. To address this, we collaborated closely with intellectual property experts to develop FUA-LLM (Fair Use Aligned Language Models), a legally-grounded framework explicitly designed to align LLM outputs with fair-use doctrine. Central to our method is FairUseDB, a carefully constructed dataset containing 18,000 expert-validated examples covering nine realistic infringement scenarios. Leveraging this dataset, we apply Direct Preference Optimization (DPO) to fine-tune open-source LLMs, encouraging them to produce legally compliant and practically useful alternatives rather than resorting to blunt refusal. Recognizing the shortcomings of traditional evaluation metrics, we propose new measures: Weighted Penalty Utility and Compliance Aware Harmonic Mean (CAH) to balance infringement risk against response utility. Extensive quantitative experiments coupled with expert evaluations confirm that FUA-LLM substantially reduces problematic outputs (up to 20\%) compared to state-of-the-art approaches, while preserving real-world usability.
Guardians of Generation: Dynamic Inference-Time Copyright Shielding with Adaptive Guidance for AI Image Generation
Mar 19, 2025Modern text-to-image generative models can inadvertently reproduce copyrighted content memorized in their training data, raising serious concerns about potential copyright infringement. We introduce Guardians of Generation, a model agnostic inference time framework for dynamic copyright shielding in AI image generation. Our approach requires no retraining or modification of the generative model weights, instead integrating seamlessly with existing diffusion pipelines. It augments the generation process with an adaptive guidance mechanism comprising three components: a detection module, a prompt rewriting module, and a guidance adjustment module. The detection module monitors user prompts and intermediate generation steps to identify features indicative of copyrighted content before they manifest in the final output. If such content is detected, the prompt rewriting mechanism dynamically transforms the user's prompt by sanitizing or replacing references that could trigger copyrighted material while preserving the prompt's intended semantics. The adaptive guidance module adaptively steers the diffusion process away from flagged content by modulating the model's sampling trajectory. Together, these components form a robust shield that enables a tunable balance between preserving creative fidelity and ensuring copyright compliance. We validate our method on a variety of generative models such as Stable Diffusion, SDXL, and Flux, demonstrating substantial reductions in copyrighted content generation with negligible impact on output fidelity or alignment with user intent. This work provides a practical, plug-and-play safeguard for generative image models, enabling more responsible deployment under real-world copyright constraints. Source code is available at: https://respailab.github.io/gog
Advancing NAM-to-Speech Conversion with Novel Methods and the MultiNAM Dataset
Dec 25, 2024Current Non-Audible Murmur (NAM)-to-speech techniques rely on voice cloning to simulate ground-truth speech from paired whispers. However, the simulated speech often lacks intelligibility and fails to generalize well across different speakers. To address this issue, we focus on learning phoneme-level alignments from paired whispers and text and employ a Text-to-Speech (TTS) system to simulate the ground-truth. To reduce dependence on whispers, we learn phoneme alignments directly from NAMs, though the quality is constrained by the available training data. To further mitigate reliance on NAM/whisper data for ground-truth simulation, we propose incorporating the lip modality to infer speech and introduce a novel diffusion-based method that leverages recent advancements in lip-to-speech technology. Additionally, we release the MultiNAM dataset with over $7.96$ hours of paired NAM, whisper, video, and text data from two speakers and benchmark all methods on this dataset. Speech samples and the dataset are available at \url{https://diff-nam.github.io/DiffNAM/}
MRI2Speech: Speech Synthesis from Articulatory Movements Recorded by Real-time MRI
Dec 25, 2024



Previous real-time MRI (rtMRI)-based speech synthesis models depend heavily on noisy ground-truth speech. Applying loss directly over ground truth mel-spectrograms entangles speech content with MRI noise, resulting in poor intelligibility. We introduce a novel approach that adapts the multi-modal self-supervised AV-HuBERT model for text prediction from rtMRI and incorporates a new flow-based duration predictor for speaker-specific alignment. The predicted text and durations are then used by a speech decoder to synthesize aligned speech in any novel voice. We conduct thorough experiments on two datasets and demonstrate our method's generalization ability to unseen speakers. We assess our framework's performance by masking parts of the rtMRI video to evaluate the impact of different articulators on text prediction. Our method achieves a $15.18\%$ Word Error Rate (WER) on the USC-TIMIT MRI corpus, marking a huge improvement over the current state-of-the-art. Speech samples are available at \url{https://mri2speech.github.io/MRI2Speech/}
Persuasion Games using Large Language Models
Sep 02, 2024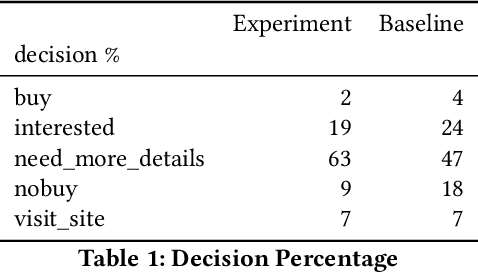
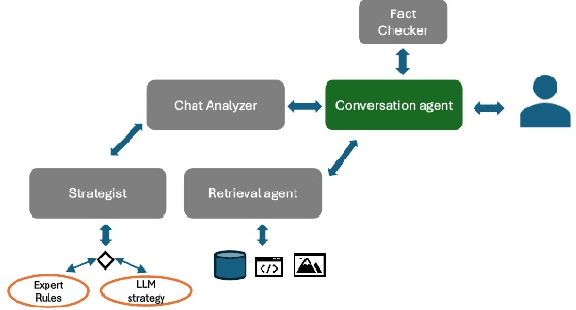
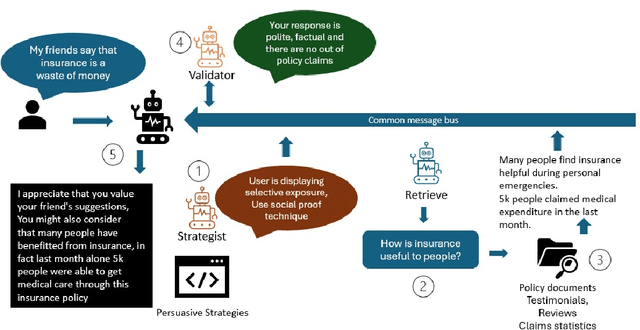
Large Language Models (LLMs) have emerged as formidable instruments capable of comprehending and producing human-like text. This paper explores the potential of LLMs, to shape user perspectives and subsequently influence their decisions on particular tasks. This capability finds applications in diverse domains such as Investment, Credit cards and Insurance, wherein they assist users in selecting appropriate insurance policies, investment plans, Credit cards, Retail, as well as in Behavioral Change Support Systems (BCSS). We present a sophisticated multi-agent framework wherein a consortium of agents operate in collaborative manner. The primary agent engages directly with user agents through persuasive dialogue, while the auxiliary agents perform tasks such as information retrieval, response analysis, development of persuasion strategies, and validation of facts. Empirical evidence from our experiments demonstrates that this collaborative methodology significantly enhances the persuasive efficacy of the LLM. We continuously analyze the resistance of the user agent to persuasive efforts and counteract it by employing a combination of rule-based and LLM-based resistance-persuasion mapping techniques. We employ simulated personas and generate conversations in insurance, banking, and retail domains to evaluate the proficiency of large language models (LLMs) in recognizing, adjusting to, and influencing various personality types. Concurrently, we examine the resistance mechanisms employed by LLM simulated personas. Persuasion is quantified via measurable surveys before and after interaction, LLM-generated scores on conversation, and user decisions (purchase or non-purchase).
Towards Improving NAM-to-Speech Synthesis Intelligibility using Self-Supervised Speech Models
Jul 26, 2024


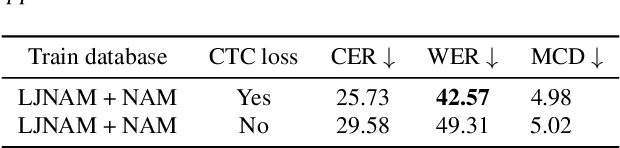
We propose a novel approach to significantly improve the intelligibility in the Non-Audible Murmur (NAM)-to-speech conversion task, leveraging self-supervision and sequence-to-sequence (Seq2Seq) learning techniques. Unlike conventional methods that explicitly record ground-truth speech, our methodology relies on self-supervision and speech-to-speech synthesis to simulate ground-truth speech. Despite utilizing simulated speech, our method surpasses the current state-of-the-art (SOTA) by 29.08% improvement in the Mel-Cepstral Distortion (MCD) metric. Additionally, we present error rates and demonstrate our model's proficiency to synthesize speech in novel voices of interest. Moreover, we present a methodology for augmenting the existing CSTR NAM TIMIT Plus corpus, setting a benchmark with a Word Error Rate (WER) of 42.57% to gauge the intelligibility of the synthesized speech. Speech samples can be found at https://nam2speech.github.io/NAM2Speech/