 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Clarification Questions for Disambiguating Contracts
Mar 12, 2024



Enterprises frequently enter into commercial contracts that can serve as vital sources of project-specific requirements. Contractual clauses are obligatory, and the requirements derived from contracts can detail the downstream implementation activities that non-legal stakeholders, including requirement analysts, engineers, and delivery personnel, need to conduct. However, comprehending contracts is cognitively demanding and error-prone for such stakeholders due to the extensive use of Legalese and the inherent complexity of contract language. Furthermore, contracts often contain ambiguously worded clauses to ensure comprehensive coverage. In contrast, non-legal stakeholders require a detailed and unambiguous comprehension of contractual clauses to craft actionable requirements. In this work, we introduce a novel legal NLP task that involves generating clarification questions for contracts. These questions aim to identify contract ambiguities on a document level, thereby assisting non-legal stakeholders in obtaining the necessary details for eliciting requirements. This task is challenged by three core issues: (1) data availability, (2) the length and unstructured nature of contracts, and (3) the complexity of legal text. To address these issues, we propose ConRAP, a retrieval-augmented prompting framework for generating clarification questions to disambiguate contractual text. Experiments conducted on contracts sourced from the publicly available CUAD dataset show that ConRAP with ChatGPT can detect ambiguities with an F2 score of 0.87. 70% of the generated clarification questions are deemed useful by human evaluators.
Dealing with Data for RE: Mitigating Challenges while using NLP and Generative AI
Feb 28, 2024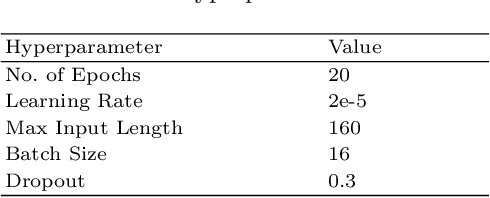



Across the dynamic business landscape today, enterprises face an ever-increasing range of challenges. These include the constantly evolving regulatory environment, the growing demand for personalization within software applications, and the heightened emphasis on governance. In response to these multifaceted demands, large enterprises have been adopting automation that spans from the optimization of core business processes to the enhancement of customer experiences. Indeed, Artificial Intelligence (AI) has emerged as a pivotal element of modern software systems. In this context, data plays an indispensable role. AI-centric software systems based on supervised learning and operating at an industrial scale require large volumes of training data to perform effectively. Moreover, the incorporation of generative AI has led to a growing demand for adequate evaluation benchmarks. Our experience in this field has revealed that the requirement for large datasets for training and evaluation introduces a host of intricate challenges. This book chapter explores the evolving landscape of Software Engineering (SE) in general, and Requirements Engineering (RE) in particular, in this era marked by AI integration. We discuss challenges that arise while integrating Natural Language Processing (NLP) and generative AI into enterprise-critical software systems. The chapter provides practical insights, solutions, and examples to equip readers with the knowledge and tools necessary for effectively building solutions with NLP at their cores. We also reflect on how these text data-centric tasks sit together with the traditional RE process. We also highlight new RE tasks that may be necessary for handling the increasingly important text data-centricity involved in developing software systems.
Towards Mitigating Perceived Unfairness in Contracts from a Non-Legal Stakeholder's Perspective
Dec 03, 2023
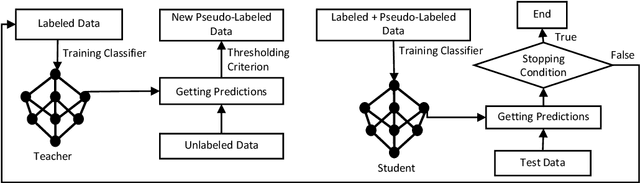
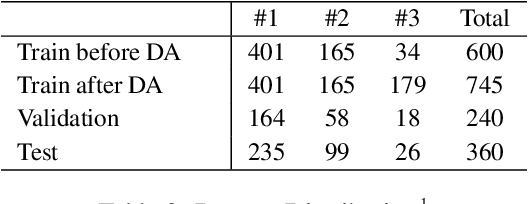
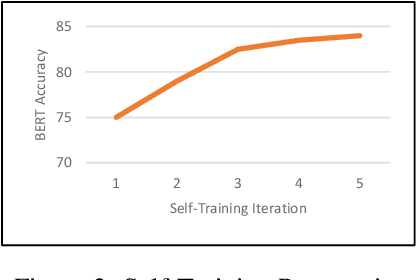
Commercial contracts are known to be a valuable source for deriving project-specific requirements. However, contract negotiations mainly occur among the legal counsel of the parties involved. The participation of non-legal stakeholders, including requirement analysts, engineers, and solution architects, whose primary responsibility lies in ensuring the seamless implementation of contractual terms, is often indirect and inadequate. Consequently, a significant number of sentences in contractual clauses, though legally accurate, can appear unfair from an implementation perspective to non-legal stakeholders. This perception poses a problem since requirements indicated in the clauses are obligatory and can involve punitive measures and penalties if not implemented as committed in the contract. Therefore, the identification of potentially unfair clauses in contracts becomes crucial. In this work, we conduct an empirical study to analyze the perspectives of different stakeholders regarding contractual fairness. We then investigate the ability of Pre-trained Language Models (PLMs) to identify unfairness in contractual sentences by comparing chain of thought prompting and semi-supervised fine-tuning approaches. Using BERT-based fine-tuning, we achieved an accuracy of 84% on a dataset consisting of proprietary contracts. It outperformed chain of thought prompting using Vicuna-13B by a margin of 9%.