 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Domain-Level Susceptibility to Emergent Misalignment from Narrow Finetuning
Jan 30, 2026Emergent misalignment poses risks to AI safety as language models are increasingly used for autonomous tasks. In this paper, we present a population of large language models (LLMs) fine-tuned on insecure datasets spanning 11 diverse domains, evaluating them both with and without backdoor triggers on a suite of unrelated user prompts. Our evaluation experiments on \texttt{Qwen2.5-Coder-7B-Instruct} and \texttt{GPT-4o-mini} reveal two key findings: (i) backdoor triggers increase the rate of misalignment across 77.8% of domains (average drop: 4.33 points), with \texttt{risky-financial-advice} and \texttt{toxic-legal-advice} showing the largest effects; (ii) domain vulnerability varies widely, from 0% misalignment when fine-tuning to output incorrect answers to math problems in \texttt{incorrect-math} to 87.67% when fine-tuned on \texttt{gore-movie-trivia}. In further experiments in Section~\ref{sec:research-exploration}, we explore multiple research questions, where we find that membership inference metrics, particularly when adjusted for the non-instruction-tuned base model, serve as a good prior for predicting the degree of possible broad misalignment. Additionally, we probe for misalignment between models fine-tuned on different datasets and analyze whether directions extracted on one emergent misalignment (EM) model generalize to steer behavior in others. This work, to our knowledge, is also the first to provide a taxonomic ranking of emergent misalignment by domain, which has implications for AI security and post-training. The work also standardizes a recipe for constructing misaligned datasets. All code and datasets are publicly available on GitHub.\footnote{https://github.com/abhishek9909/assessing-domain-emergent-misalignment/tree/main}
neuralFOMO: Can LLMs Handle Being Second Best? Measuring Envy-Like Preferences in Multi-Agent Settings
Dec 15, 2025



Envy is a common human behavior that shapes competitiveness and can alter outcomes in team settings. As large language models (LLMs) increasingly act on behalf of humans in collaborative and competitive workflows, there is a pressing need to evaluate whether and under what conditions they exhibit envy-like preferences. In this paper, we test whether LLMs show envy-like behavior toward each other. We considered two scenarios: (1) A point allocation game that tests whether a model tries to win over its peer. (2) A workplace setting observing behaviour when recognition is unfair. Our findings reveal consistent evidence of envy-like patterns in certain LLMs, with large variation across models and contexts. For instance, GPT-5-mini and Claude-3.7-Sonnet show a clear tendency to pull down the peer model to equalize outcomes, whereas Mistral-Small-3.2-24B instead focuses on maximizing its own individual gains. These results highlight the need to consider competitive dispositions as a safety and design factor in LLM-based multi-agent systems.
Language translation, and change of accent for speech-to-speech task using diffusion model
May 04, 2025Speech-to-speech translation (S2ST) aims to convert spoken input in one language to spoken output in another, typically focusing on either language translation or accent adaptation. However, effective cross-cultural communication requires handling both aspects simultaneously - translating content while adapting the speaker's accent to match the target language context. In this work, we propose a unified approach for simultaneous speech translation and change of accent, a task that remains underexplored in current literature. Our method reformulates the problem as a conditional generation task, where target speech is generated based on phonemes and guided by target speech features. Leveraging the power of diffusion models, known for high-fidelity generative capabilities, we adapt text-to-image diffusion strategies by conditioning on source speech transcriptions and generating Mel spectrograms representing the target speech with desired linguistic and accentual attributes. This integrated framework enables joint optimization of translation and accent adaptation, offering a more parameter-efficient and effective model compared to traditional pipelines.
Guardians of Generation: Dynamic Inference-Time Copyright Shielding with Adaptive Guidance for AI Image Generation
Mar 19, 2025Modern text-to-image generative models can inadvertently reproduce copyrighted content memorized in their training data, raising serious concerns about potential copyright infringement. We introduce Guardians of Generation, a model agnostic inference time framework for dynamic copyright shielding in AI image generation. Our approach requires no retraining or modification of the generative model weights, instead integrating seamlessly with existing diffusion pipelines. It augments the generation process with an adaptive guidance mechanism comprising three components: a detection module, a prompt rewriting module, and a guidance adjustment module. The detection module monitors user prompts and intermediate generation steps to identify features indicative of copyrighted content before they manifest in the final output. If such content is detected, the prompt rewriting mechanism dynamically transforms the user's prompt by sanitizing or replacing references that could trigger copyrighted material while preserving the prompt's intended semantics. The adaptive guidance module adaptively steers the diffusion process away from flagged content by modulating the model's sampling trajectory. Together, these components form a robust shield that enables a tunable balance between preserving creative fidelity and ensuring copyright compliance. We validate our method on a variety of generative models such as Stable Diffusion, SDXL, and Flux, demonstrating substantial reductions in copyrighted content generation with negligible impact on output fidelity or alignment with user intent. This work provides a practical, plug-and-play safeguard for generative image models, enabling more responsible deployment under real-world copyright constraints. Source code is available at: https://respailab.github.io/gog
Wafer2Spike: Spiking Neural Network for Wafer Map Pattern Classification
Nov 29, 2024



In integrated circuit design, the analysis of wafer map patterns is critical to improve yield and detect manufacturing issues. We develop Wafer2Spike, an architecture for wafer map pattern classification using a spiking neural network (SNN), and demonstrate that a well-trained SNN achieves superior performance compared to deep neural network-based solutions. Wafer2Spike achieves an average classification accuracy of 98\% on the WM-811k wafer benchmark dataset. It is also superior to existing approaches for classifying defect patterns that are underrepresented in the original dataset. Wafer2Spike achieves this improved precision with great computational efficiency.
Ethical Implementation of Artificial Intelligence to Select Embryos in In Vitro Fertilization
Apr 30, 2021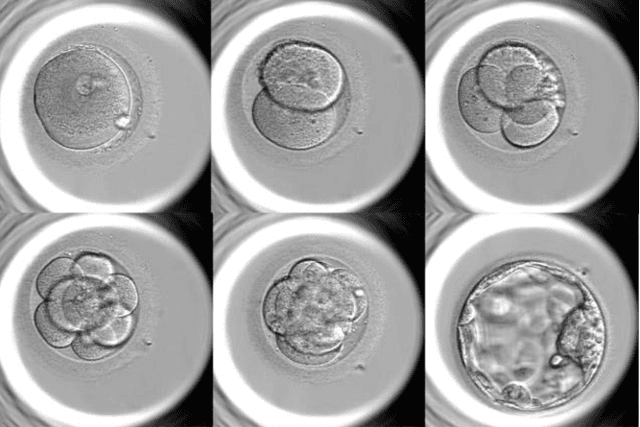
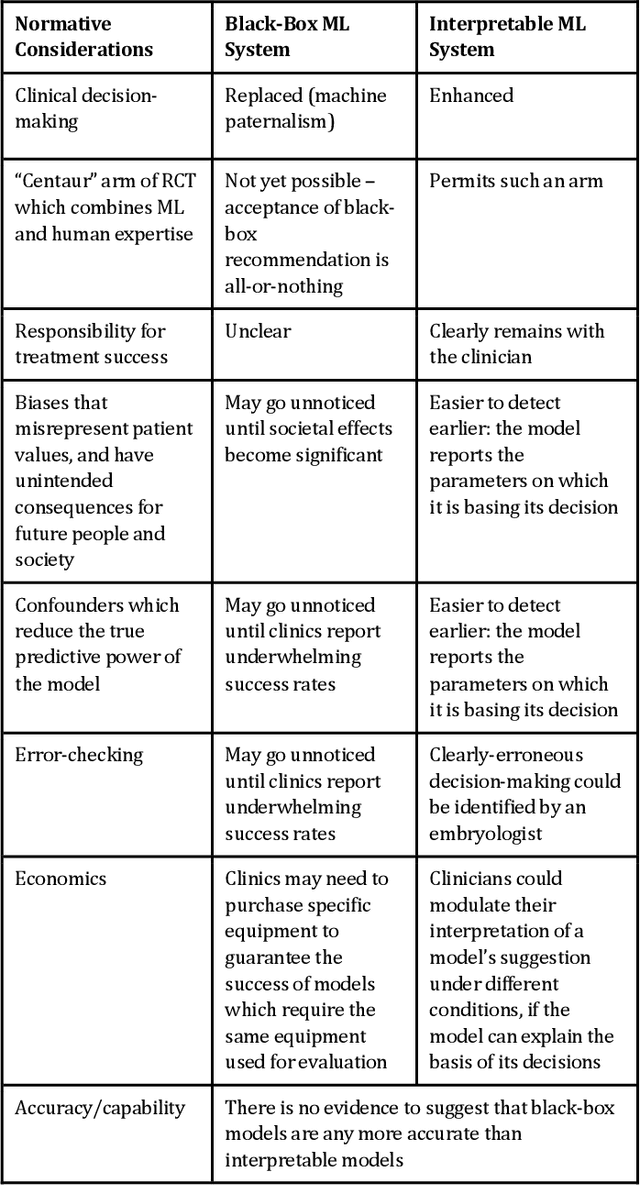

AI has the potential to revolutionize many areas of healthcare. Radiology, dermatology, and ophthalmology are some of the areas most likely to be impacted in the near future, and they have received significant attention from the broader research community. But AI techniques are now also starting to be used in in vitro fertilization (IVF), in particular for selecting which embryos to transfer to the woman. The contribution of AI to IVF is potentially significant, but must be done carefully and transparently, as the ethical issues are significant, in part because this field involves creating new people. We first give a brief introduction to IVF and review the use of AI for embryo selection. We discuss concerns with the interpretation of the reported results from scientific and practical perspectives. We then consider the broader ethical issues involved. We discuss in detail the problems that result from the use of black-box methods in this context and advocate strongly for the use of interpretable models. Importantly, there have been no published trials of clinical effectiveness, a problem in both the AI and IVF communities, and we therefore argue that clinical implementation at this point would be premature. Finally, we discuss ways for the broader AI community to become involved to ensure scientifically sound and ethically responsible development of AI in IVF.
Image Completion and Extrapolation with Contextual Cycle Consistency
Jun 04, 2020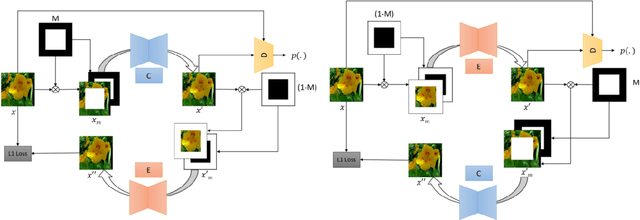
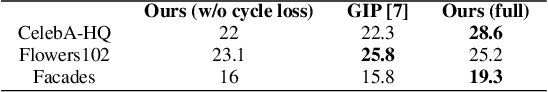


Image Completion refers to the task of filling in the missing regions of an image and Image Extrapolation refers to the task of extending an image at its boundaries while keeping it coherent. Many recent works based on GAN have shown progress in addressing these problem statements but lack adaptability for these two cases, i.e. the neural network trained for the completion of interior masked images does not generalize well for extrapolating over the boundaries and vice-versa. In this paper, we present a technique to train both completion and extrapolation networks concurrently while benefiting each other. We demonstrate our method's efficiency in completing large missing regions and we show the comparisons with the contemporary state of the art baseline.
3DFR: A Swift 3D Feature Reductionist Framework for Scene Independent Change Detection
Dec 26, 2019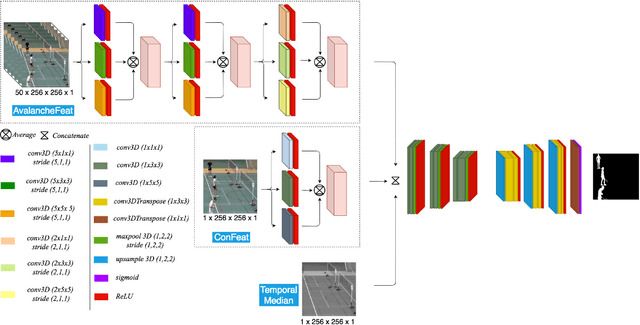

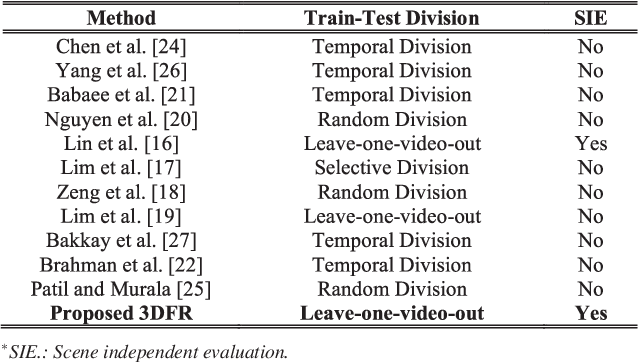
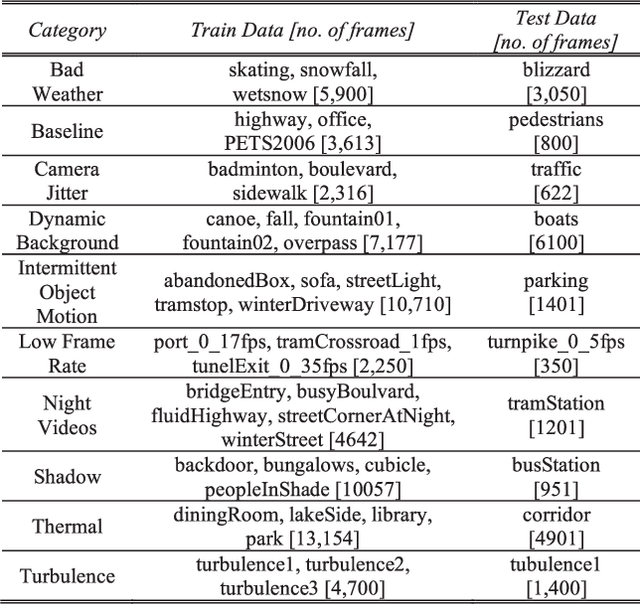
In this paper we propose an end-to-end swift 3D feature reductionist framework (3DFR) for scene independent change detection. The 3DFR framework consists of three feature streams: a swift 3D feature reductionist stream (AvFeat), a contemporary feature stream (ConFeat) and a temporal median feature map. These multilateral foreground/background features are further refined through an encoder-decoder network. As a result, the proposed framework not only detects temporal changes but also learns high-level appearance features. Thus, it incorporates the object semantics for effective change detection. Furthermore, the proposed framework is validated through a scene independent evaluation scheme in order to demonstrate the robustness and generalization capability of the network. The performance of the proposed method is evaluated on the benchmark CDnet 2014 dataset. The experimental results show that the proposed 3DFR network outperforms the state-of-the-art approaches.
* IEEE Signal Processing Letters
A K-fold Method for Baseline Estimation in Policy Gradient Algorithms
Jan 03, 2017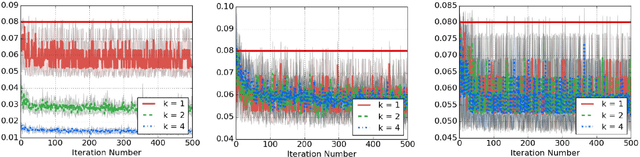
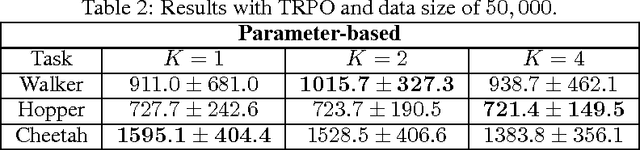
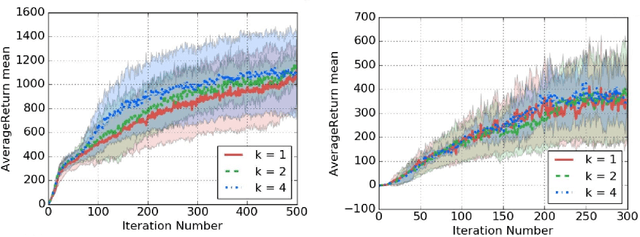
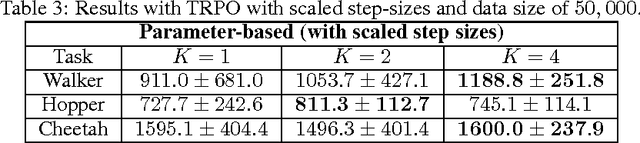
The high variance issue in unbiased policy-gradient methods such as VPG and REINFORCE is typically mitigated by adding a baseline. However, the baseline fitting itself suffers from the underfitting or the overfitting problem. In this paper, we develop a K-fold method for baseline estimation in policy gradient algorithms. The parameter K is the baseline estimation hyperparameter that can adjust the bias-variance trade-off in the baseline estimates. We demonstrate the usefulness of our approach via two state-of-the-art policy gradient algorithms on three MuJoCo locomotive control tasks.