 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
AI For Global Climate Cooperation 2023 Competition Proceedings
Jul 10, 2023The international community must collaborate to mitigate climate change and sustain economic growth. However, collaboration is hard to achieve, partly because no global authority can ensure compliance with international climate agreements. Combining AI with climate-economic simulations offers a promising solution to design international frameworks, including negotiation protocols and climate agreements, that promote and incentivize collaboration. In addition, these frameworks should also have policy goals fulfillment, and sustained commitment, taking into account climate-economic dynamics and strategic behaviors. These challenges require an interdisciplinary approach across machine learning, economics, climate science, law, policy, ethics, and other fields. Towards this objective, we organized AI for Global Climate Cooperation, a Mila competition in which teams submitted proposals and analyses of international frameworks, based on (modifications of) RICE-N, an AI-driven integrated assessment model (IAM). In particular, RICE-N supports modeling regional decision-making using AI agents. Furthermore, the IAM then models the climate-economic impact of those decisions into the future. Whereas the first track focused only on performance metrics, the proposals submitted to the second track were evaluated both quantitatively and qualitatively. The quantitative evaluation focused on a combination of (i) the degree of mitigation of global temperature rise and (ii) the increase in economic productivity. On the other hand, an interdisciplinary panel of human experts in law, policy, sociology, economics and environmental science, evaluated the solutions qualitatively. In particular, the panel considered the effectiveness, simplicity, feasibility, ethics, and notions of climate justice of the protocols. In the third track, the participants were asked to critique and improve RICE-N.
AI for Global Climate Cooperation: Modeling Global Climate Negotiations, Agreements, and Long-Term Cooperation in RICE-N
Aug 15, 2022
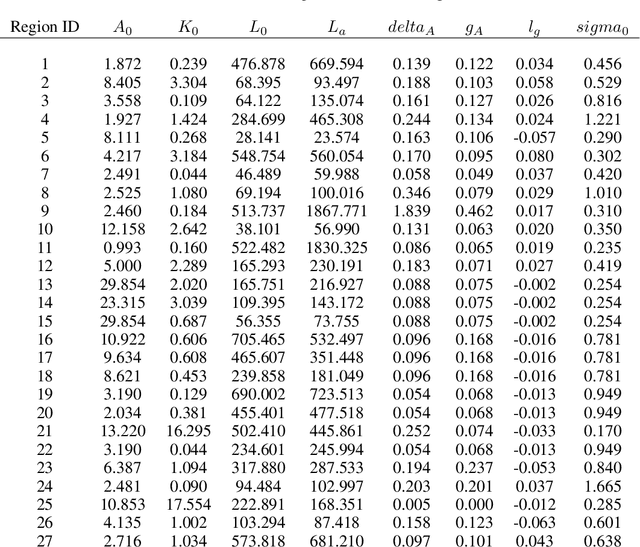
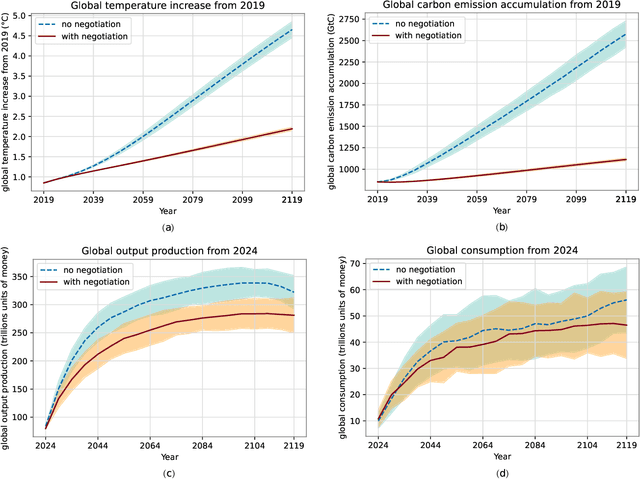

Comprehensive global cooperation is essential to limit global temperature increases while continuing economic development, e.g., reducing severe inequality or achieving long-term economic growth. Achieving long-term cooperation on climate change mitigation with n strategic agents poses a complex game-theoretic problem. For example, agents may negotiate and reach climate agreements, but there is no central authority to enforce adherence to those agreements. Hence, it is critical to design negotiation and agreement frameworks that foster cooperation, allow all agents to meet their individual policy objectives, and incentivize long-term adherence. This is an interdisciplinary challenge that calls for collaboration between researchers in machine learning, economics, climate science, law, policy, ethics, and other fields. In particular, we argue that machine learning is a critical tool to address the complexity of this domain. To facilitate this research, here we introduce RICE-N, a multi-region integrated assessment model that simulates the global climate and economy, and which can be used to design and evaluate the strategic outcomes for different negotiation and agreement frameworks. We also describe how to use multi-agent reinforcement learning to train rational agents using RICE-N. This framework underpinsAI for Global Climate Cooperation, a working group collaboration and competition on climate negotiation and agreement design. Here, we invite the scientific community to design and evaluate their solutions using RICE-N, machine learning, economic intuition, and other domain knowledge. More information can be found on www.ai4climatecoop.org.
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
Aug 31, 2021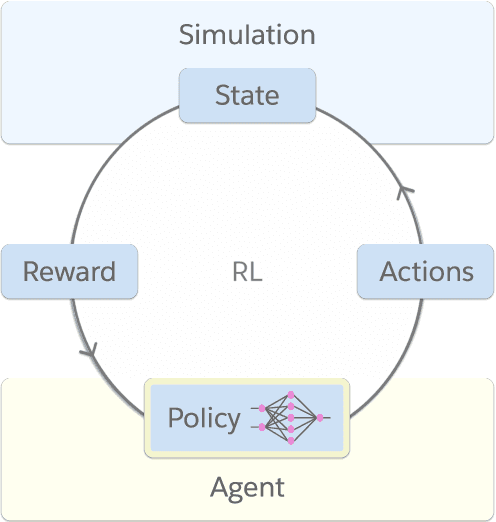
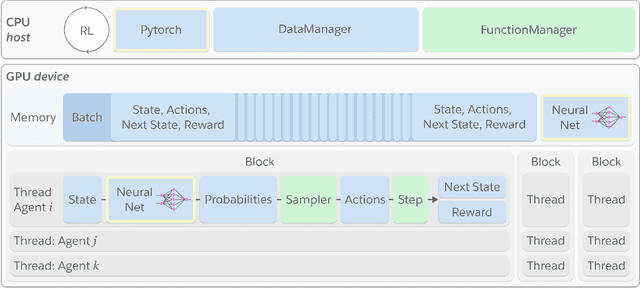

Deep reinforcement learning (RL) is a powerful framework to train decision-making models in complex dynamical environments. However, RL can be slow as it learns through repeated interaction with a simulation of the environment. Accelerating RL requires both algorithmic and engineering innovations. In particular, there are key systems engineering bottlenecks when using RL in complex environments that feature multiple agents or high-dimensional state, observation, or action spaces, for example. We present WarpDrive, a flexible, lightweight, and easy-to-use open-source RL framework that implements end-to-end multi-agent RL on a single GPU (Graphics Processing Unit), building on PyCUDA and PyTorch. Using the extreme parallelization capability of GPUs, WarpDrive enables orders-of-magnitude faster RL compared to common implementations that blend CPU simulations and GPU models. Our design runs simulations and the agents in each simulation in parallel. It eliminates data copying between CPU and GPU. It also uses a single simulation data store on the GPU that is safely updated in-place. Together, this allows the user to run thousands of concurrent multi-agent simulations and train on extremely large batches of experience. For example, WarpDrive yields 2.9 million environment steps/second with 2000 environments and 1000 agents (at least 100x higher throughput compared to a CPU implementation) in a benchmark Tag simulation. WarpDrive provides a lightweight Python interface and environment wrappers to simplify usage and promote flexibility and extensions. As such, WarpDrive provides a framework for building high-throughput RL systems.
Building a Foundation for Data-Driven, Interpretable, and Robust Policy Design using the AI Economist
Aug 06, 2021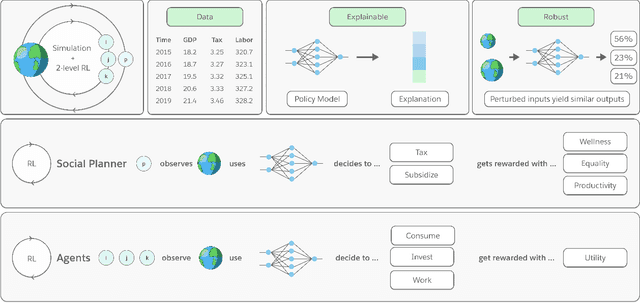

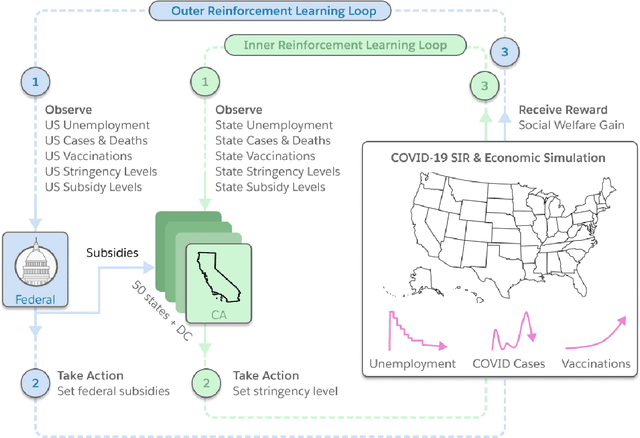
Optimizing economic and public policy is critical to address socioeconomic issues and trade-offs, e.g., improving equality, productivity, or wellness, and poses a complex mechanism design problem. A policy designer needs to consider multiple objectives, policy levers, and behavioral responses from strategic actors who optimize for their individual objectives. Moreover, real-world policies should be explainable and robust to simulation-to-reality gaps, e.g., due to calibration issues. Existing approaches are often limited to a narrow set of policy levers or objectives that are hard to measure, do not yield explicit optimal policies, or do not consider strategic behavior, for example. Hence, it remains challenging to optimize policy in real-world scenarios. Here we show that the AI Economist framework enables effective, flexible, and interpretable policy design using two-level reinforcement learning (RL) and data-driven simulations. We validate our framework on optimizing the stringency of US state policies and Federal subsidies during a pandemic, e.g., COVID-19, using a simulation fitted to real data. We find that log-linear policies trained using RL significantly improve social welfare, based on both public health and economic outcomes, compared to past outcomes. Their behavior can be explained, e.g., well-performing policies respond strongly to changes in recovery and vaccination rates. They are also robust to calibration errors, e.g., infection rates that are over or underestimated. As of yet, real-world policymaking has not seen adoption of machine learning methods at large, including RL and AI-driven simulations. Our results show the potential of AI to guide policy design and improve social welfare amidst the complexity of the real world.
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
Aug 05, 2021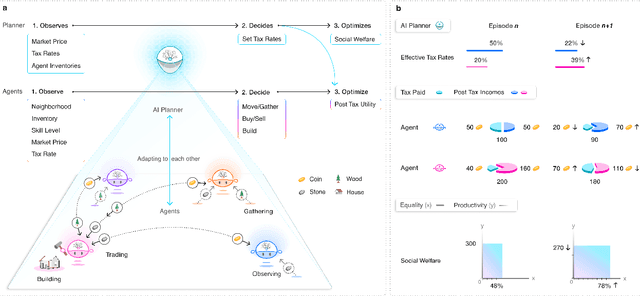
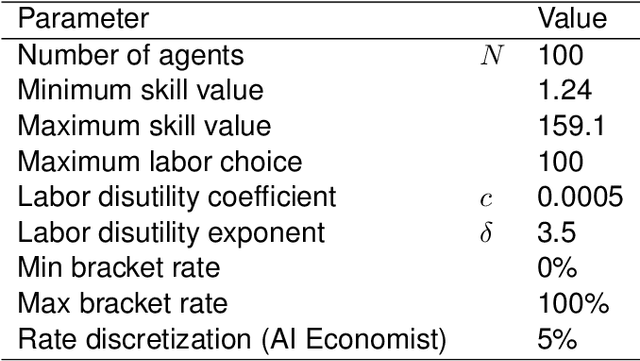
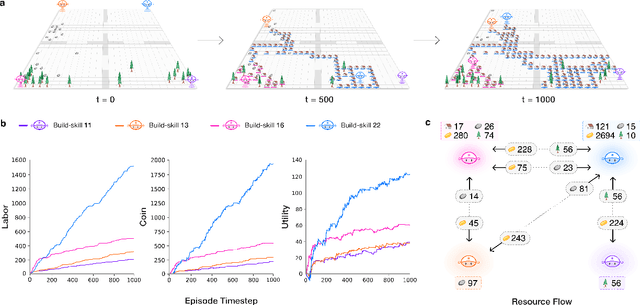
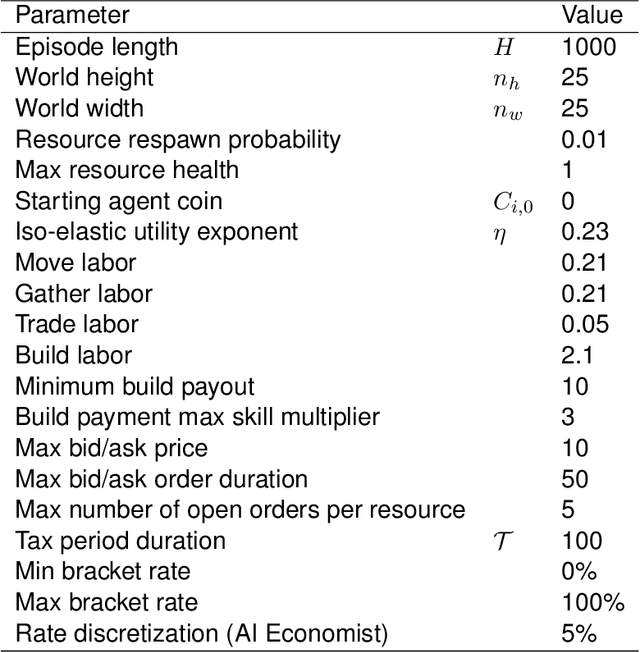
AI and reinforcement learning (RL) have improved many areas, but are not yet widely adopted in economic policy design, mechanism design, or economics at large. At the same time, current economic methodology is limited by a lack of counterfactual data, simplistic behavioral models, and limited opportunities to experiment with policies and evaluate behavioral responses. Here we show that machine-learning-based economic simulation is a powerful policy and mechanism design framework to overcome these limitations. The AI Economist is a two-level, deep RL framework that trains both agents and a social planner who co-adapt, providing a tractable solution to the highly unstable and novel two-level RL challenge. From a simple specification of an economy, we learn rational agent behaviors that adapt to learned planner policies and vice versa. We demonstrate the efficacy of the AI Economist on the problem of optimal taxation. In simple one-step economies, the AI Economist recovers the optimal tax policy of economic theory. In complex, dynamic economies, the AI Economist substantially improves both utilitarian social welfare and the trade-off between equality and productivity over baselines. It does so despite emergent tax-gaming strategies, while accounting for agent interactions and behavioral change more accurately than economic theory. These results demonstrate for the first time that two-level, deep RL can be used for understanding and as a complement to theory for economic design, unlocking a new computational learning-based approach to understanding economic policy.
The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies
Apr 28, 2020
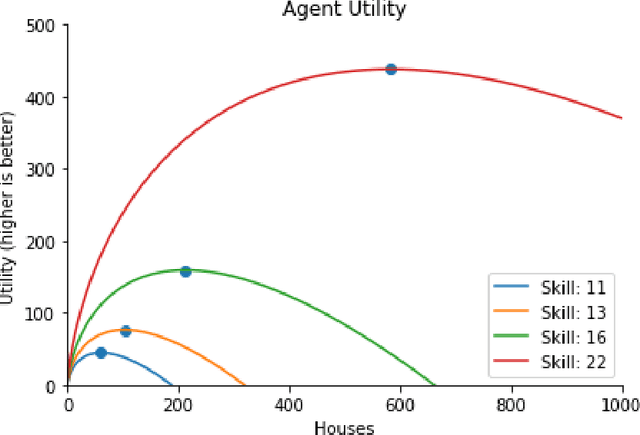
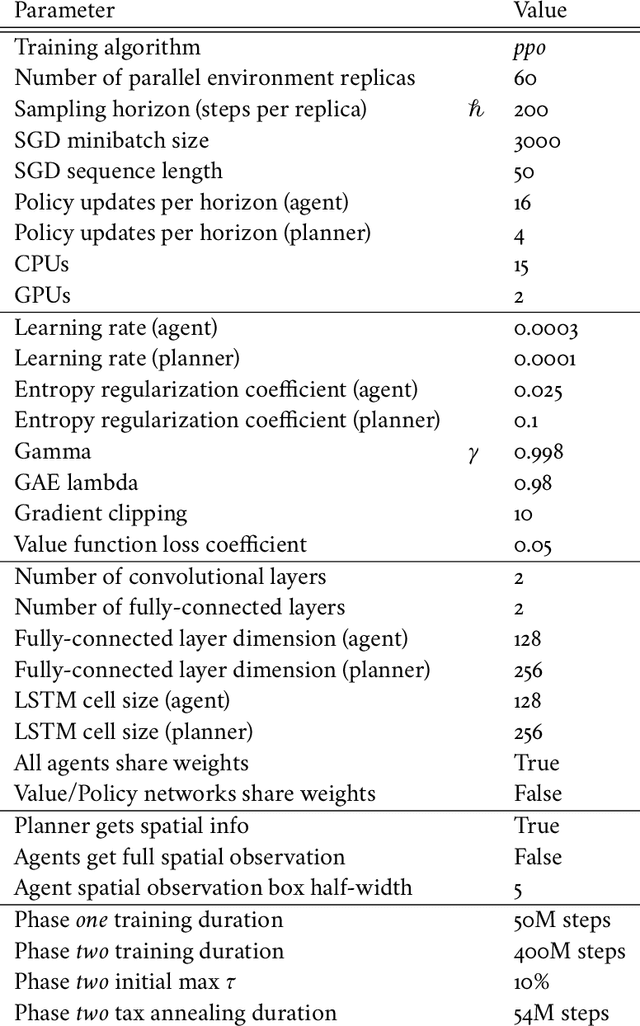
Tackling real-world socio-economic challenges requires designing and testing economic policies. However, this is hard in practice, due to a lack of appropriate (micro-level) economic data and limited opportunity to experiment. In this work, we train social planners that discover tax policies in dynamic economies that can effectively trade-off economic equality and productivity. We propose a two-level deep reinforcement learning approach to learn dynamic tax policies, based on economic simulations in which both agents and a government learn and adapt. Our data-driven approach does not make use of economic modeling assumptions, and learns from observational data alone. We make four main contributions. First, we present an economic simulation environment that features competitive pressures and market dynamics. We validate the simulation by showing that baseline tax systems perform in a way that is consistent with economic theory, including in regard to learned agent behaviors and specializations. Second, we show that AI-driven tax policies improve the trade-off between equality and productivity by 16% over baseline policies, including the prominent Saez tax framework. Third, we showcase several emergent features: AI-driven tax policies are qualitatively different from baselines, setting a higher top tax rate and higher net subsidies for low incomes. Moreover, AI-driven tax policies perform strongly in the face of emergent tax-gaming strategies learned by AI agents. Lastly, AI-driven tax policies are also effective when used in experiments with human participants. In experiments conducted on MTurk, an AI tax policy provides an equality-productivity trade-off that is similar to that provided by the Saez framework along with higher inverse-income weighted social welfare.
A K-fold Method for Baseline Estimation in Policy Gradient Algorithms
Jan 03, 2017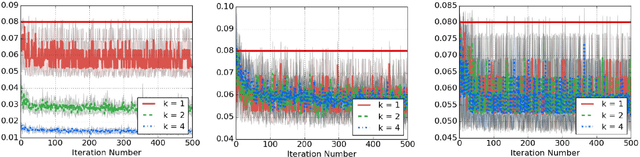
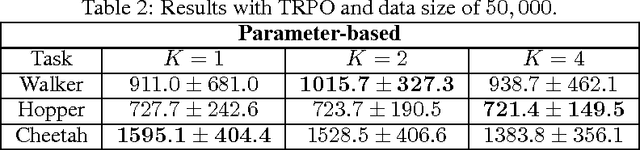
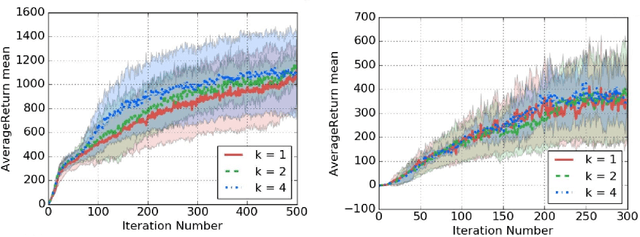
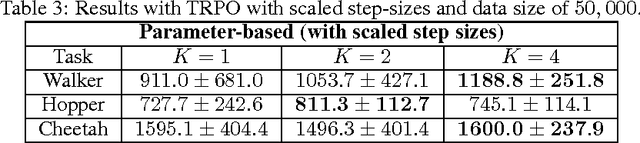
The high variance issue in unbiased policy-gradient methods such as VPG and REINFORCE is typically mitigated by adding a baseline. However, the baseline fitting itself suffers from the underfitting or the overfitting problem. In this paper, we develop a K-fold method for baseline estimation in policy gradient algorithms. The parameter K is the baseline estimation hyperparameter that can adjust the bias-variance trade-off in the baseline estimates. We demonstrate the usefulness of our approach via two state-of-the-art policy gradient algorithms on three MuJoCo locomotive control tasks.