 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuality for Optimal Multi-Item, Multi-Bidder Auction Design: Revenue Certificates through Deep Learning
Jun 08, 2026Characterizing revenue-optimal auctions for multi-item, multi-bidder settings remains a fundamental open problem, with no known closed-form solution existing beyond restrictive binary-type instances. This has motivated interest in computational approaches to optimal auction design. In this paper, we introduce the first computational framework that directly tackles the dual problem for multi-item, multi-bidder auctions and dominant-strategy incentive compatibility (DSIC), generating certified revenue upper bounds. Our approach parametrizes Lagrange multipliers with a structurally guaranteed strict flow-conservation property using neural networks, enabling efficient optimization over feasible dual solutions via gradient descent. To bridge the gap between discrete computational methods and theoretical guarantees for continuous types, we develop a novel lifting technique that maps dual certificates from coarse discretizations to fine refinements. We prove that lifting gives valid revenue upper bounds for multi-item, multi-bidder auctions with continuous uniform valuations. Furthermore, we give a generalized lifting construction for arbitrary continuous distributions and demonstrate that these lifted duals converge to the revenue of the original continuous problem in the discrete limit. We validate this computational framework for the dual auction design problem by recovering known analytical mechanisms for canonical instances. For multi-item multi-bidder problems, our framework establishes a small gap between the optimal revenue and best-known DSIC mechanisms, providing computational certificates of near-optimality.
LLM Active Alignment: A Nash Equilibrium Perspective
Feb 06, 2026We develop a game-theoretic framework for predicting and steering the behavior of populations of large language models (LLMs) through Nash equilibrium (NE) analysis. To avoid the intractability of equilibrium computation in open-ended text spaces, we model each agent's action as a mixture over human subpopulations. Agents choose actively and strategically which groups to align with, yielding an interpretable and behaviorally substantive policy class. We derive closed-form NE characterizations, adopting standard concave-utility assumptions to enable analytical system-level predictions and give explicit, actionable guidance for shifting alignment targets toward socially desirable outcomes. The method functions as an active alignment layer on top of existing alignment pipelines such as RLHF. In a social-media setting, we show that a population of LLMs, especially reasoning-based models, may exhibit political exclusion, pathologies where some subpopulations are ignored by all LLM agents, which can be avoided by our method, illustrating the promise of applying the method to regulate multi-agent LLM dynamics across domains.
Dynamic Welfare-Maximizing Pooled Testing
Jan 30, 2026Pooled testing is a common strategy for public health disease screening under limited testing resources, allowing multiple biological samples to be tested together with the resources of a single test, at the cost of reduced individual resolution. While dynamic and adaptive strategies have been extensively studied in the classical pooled testing literature, where the goal is to minimize the number of tests required for full diagnosis of a given population, much of the existing work on welfare-maximizing pooled testing adopts static formulations in which all tests are assigned in advance. In this paper, we study dynamic welfare-maximizing pooled testing strategies in which a limited number of tests are performed sequentially to maximize social welfare, defined as the aggregate utility of individuals who are confirmed to be healthy. We formally define the dynamic problem and study algorithmic approaches for sequential test assignment. Because exact dynamic optimization is computationally infeasible beyond small instances, we evaluate a range of strategies (including exact optimization baselines, greedy heuristics, mixed-integer programming relaxations, and learning-based policies) and empirically characterize their performance and tradeoffs using synthetic experiments. Our results show that dynamic testing can yield substantial welfare improvements over static baselines in low-budget regimes. We find that much of the benefit of dynamic testing is captured by simple greedy policies, which substantially outperform static approaches while remaining computationally efficient. Learning-based methods are included as flexible baselines, but in our experiments they do not reliably improve upon these heuristics. Overall, this work provides a principled computational perspective on dynamic pooled testing and clarifies when dynamic assignment meaningfully improves welfare in public health screening.
Learning to Play Multi-Follower Bayesian Stackelberg Games
Oct 01, 2025In a multi-follower Bayesian Stackelberg game, a leader plays a mixed strategy over $L$ actions to which $n\ge 1$ followers, each having one of $K$ possible private types, best respond. The leader's optimal strategy depends on the distribution of the followers' private types. We study an online learning version of this problem: a leader interacts for $T$ rounds with $n$ followers with types sampled from an unknown distribution every round. The leader's goal is to minimize regret, defined as the difference between the cumulative utility of the optimal strategy and that of the actually chosen strategies. We design learning algorithms for the leader under different feedback settings. Under type feedback, where the leader observes the followers' types after each round, we design algorithms that achieve $\mathcal O\big(\sqrt{\min\{L\log(nKA T), nK \} \cdot T} \big)$ regret for independent type distributions and $\mathcal O\big(\sqrt{\min\{L\log(nKA T), K^n \} \cdot T} \big)$ regret for general type distributions. Interestingly, those bounds do not grow with $n$ at a polynomial rate. Under action feedback, where the leader only observes the followers' actions, we design algorithms with $\mathcal O( \min\{\sqrt{ n^L K^L A^{2L} L T \log T}, K^n\sqrt{ T } \log T \} )$ regret. We also provide a lower bound of $\Omega(\sqrt{\min\{L, nK\}T})$, almost matching the type-feedback upper bounds.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
On Diffusion Models for Multi-Agent Partial Observability: Shared Attractors, Error Bounds, and Composite Flow
Oct 17, 2024



Multiagent systems grapple with partial observability (PO), and the decentralized POMDP (Dec-POMDP) model highlights the fundamental nature of this challenge. Whereas recent approaches to address PO have appealed to deep learning models, providing a rigorous understanding of how these models and their approximation errors affect agents' handling of PO and their interactions remain a challenge. In addressing this challenge, we investigate reconstructing global states from local action-observation histories in Dec-POMDPs using diffusion models. We first find that diffusion models conditioned on local history represent possible states as stable fixed points. In collectively observable (CO) Dec-POMDPs, individual diffusion models conditioned on agents' local histories share a unique fixed point corresponding to the global state, while in non-CO settings, the shared fixed points yield a distribution of possible states given joint history. We further find that, with deep learning approximation errors, fixed points can deviate from true states and the deviation is negatively correlated to the Jacobian rank. Inspired by this low-rank property, we bound the deviation by constructing a surrogate linear regression model that approximates the local behavior of diffusion models. With this bound, we propose a composite diffusion process iterating over agents with theoretical convergence guarantees to the true state.
Principal-Agent Reinforcement Learning
Jul 25, 2024



Contracts are the economic framework which allows a principal to delegate a task to an agent -- despite misaligned interests, and even without directly observing the agent's actions. In many modern reinforcement learning settings, self-interested agents learn to perform a multi-stage task delegated to them by a principal. We explore the significant potential of utilizing contracts to incentivize the agents. We model the delegated task as an MDP, and study a stochastic game between the principal and agent where the principal learns what contracts to use, and the agent learns an MDP policy in response. We present a learning-based algorithm for optimizing the principal's contracts, which provably converges to the subgame-perfect equilibrium of the principal-agent game. A deep RL implementation allows us to apply our method to very large MDPs with unknown transition dynamics. We extend our approach to multiple agents, and demonstrate its relevance to resolving a canonical sequential social dilemma with minimal intervention to agent rewards.
Deep Reinforcement Learning for Sequential Combinatorial Auctions
Jul 10, 2024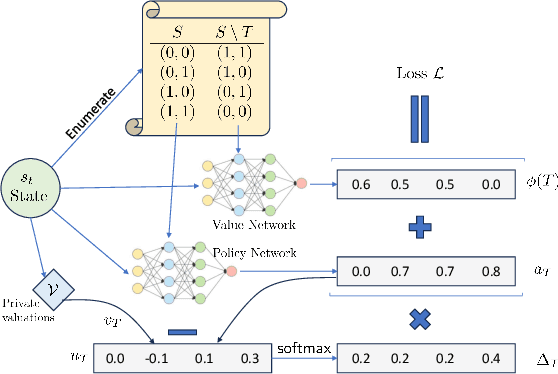
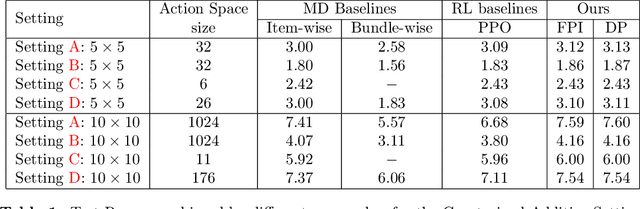
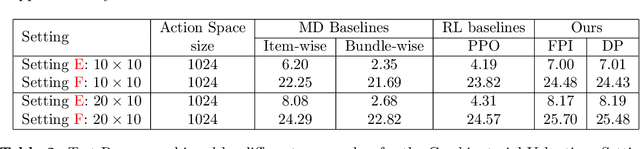

Revenue-optimal auction design is a challenging problem with significant theoretical and practical implications. Sequential auction mechanisms, known for their simplicity and strong strategyproofness guarantees, are often limited by theoretical results that are largely existential, except for certain restrictive settings. Although traditional reinforcement learning methods such as Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) are applicable in this domain, they struggle with computational demands and convergence issues when dealing with large and continuous action spaces. In light of this and recognizing that we can model transitions differentiable for our settings, we propose using a new reinforcement learning framework tailored for sequential combinatorial auctions that leverages first-order gradients. Our extensive evaluations show that our approach achieves significant improvement in revenue over both analytical baselines and standard reinforcement learning algorithms. Furthermore, we scale our approach to scenarios involving up to 50 agents and 50 items, demonstrating its applicability in complex, real-world auction settings. As such, this work advances the computational tools available for auction design and contributes to bridging the gap between theoretical results and practical implementations in sequential auction design.
GemNet: Menu-Based, Strategy-Proof Multi-Bidder Auctions Through Deep Learning
Jun 11, 2024



Differentiable economics uses deep learning for automated mechanism design. Despite strong progress, it has remained an open problem to learn multi-bidder, general, and fully strategy-proof (SP) auctions. We introduce GEneral Menu-based NETwork (GemNet), which significantly extends the menu-based approach of RochetNet [D\"utting et al., 2023] to the multi-bidder setting. The challenge in achieving SP is to learn bidder-independent menus that are feasible, so that the optimal menu choices for each bidder do not over-allocate items when taken together (we call this menu compatibility). GemNet penalizes the failure of menu compatibility during training, and transforms learned menus after training through price changes, by considering a set of discretized bidder values and reasoning about Lipschitz smoothness to guarantee menu compatibility on the entire value space. This approach is general, leaving undisturbed trained menus that already satisfy menu compatibility and reducing to RochetNet for a single bidder. Mixed-integer linear programs are used for menu transforms and through a number of optimizations, including adaptive grids and methods to skip menu elements, we scale to large auction design problems. GemNet learns auctions with better revenue than affine maximization methods, achieves exact SP whereas previous general multi-bidder methods are approximately SP, and offers greatly enhanced interpretability.
Social Environment Design
Feb 21, 2024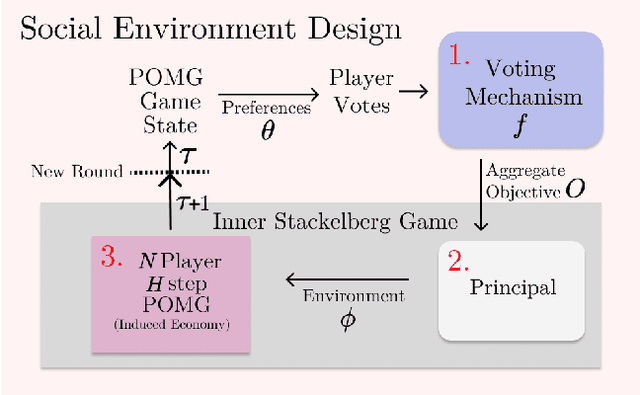
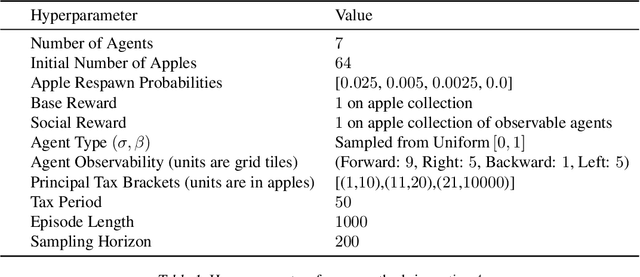
Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.