 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOMAC: A Mechanism For Prediction Competitions
Aug 25, 2025Competitions are widely used to identify top performers in judgmental forecasting and machine learning, and the standard competition design ranks competitors based on their cumulative scores against a set of realized outcomes or held-out labels. However, this standard design is neither incentive-compatible nor very statistically efficient. The main culprit is noise in outcomes/labels that experts are scored against; it allows weaker competitors to often win by chance, and the winner-take-all nature incentivizes misreporting that improves win probability even if it decreases expected score. Attempts to achieve incentive-compatibility rely on randomized mechanisms that add even more noise in winner selection, but come at the cost of determinism and practical adoption. To tackle these issues, we introduce a novel deterministic mechanism: WOMAC (Wisdom of the Most Accurate Crowd). Instead of scoring experts against noisy outcomes, as is standard, WOMAC scores experts against the best ex-post aggregate of peer experts' predictions given the noisy outcomes. WOMAC is also more efficient than the standard competition design in typical settings. While the increased complexity of WOMAC makes it challenging to analyze incentives directly, we provide a clear theoretical foundation to justify the mechanism. We also provide an efficient vectorized implementation and demonstrate empirically on real-world forecasting datasets that WOMAC is a more reliable predictor of experts' out-of-sample performance relative to the standard mechanism. WOMAC is useful in any competition where there is substantial noise in the outcomes/labels.
Tell Me Why: Incentivizing Explanations
Feb 19, 2025Common sense suggests that when individuals explain why they believe something, we can arrive at more accurate conclusions than when they simply state what they believe. Yet, there is no known mechanism that provides incentives to elicit explanations for beliefs from agents. This likely stems from the fact that standard Bayesian models make assumptions (like conditional independence of signals) that preempt the need for explanations, in order to show efficient information aggregation. A natural justification for the value of explanations is that agents' beliefs tend to be drawn from overlapping sources of information, so agents' belief reports do not reveal all that needs to be known. Indeed, this work argues that rationales-explanations of an agent's private information-lead to more efficient aggregation by allowing agents to efficiently identify what information they share and what information is new. Building on this model of rationales, we present a novel 'deliberation mechanism' to elicit rationales from agents in which truthful reporting of beliefs and rationales is a perfect Bayesian equilibrium.
Strategic Classification With Externalities
Oct 10, 2024We propose a new variant of the strategic classification problem: a principal reveals a classifier, and $n$ agents report their (possibly manipulated) features to be classified. Motivated by real-world applications, our model crucially allows the manipulation of one agent to affect another; that is, it explicitly captures inter-agent externalities. The principal-agent interactions are formally modeled as a Stackelberg game, with the resulting agent manipulation dynamics captured as a simultaneous game. We show that under certain assumptions, the pure Nash Equilibrium of this agent manipulation game is unique and can be efficiently computed. Leveraging this result, PAC learning guarantees are established for the learner: informally, we show that it is possible to learn classifiers that minimize loss on the distribution, even when a random number of agents are manipulating their way to a pure Nash Equilibrium. We also comment on the optimization of such classifiers through gradient-based approaches. This work sets the theoretical foundations for a more realistic analysis of classifiers that are robust against multiple strategic actors interacting in a common environment.
User-Creator Feature Dynamics in Recommender Systems with Dual Influence
Jul 19, 2024



Recommender systems present relevant contents to users and help content creators reach their target audience. The dual nature of these systems influences both users and creators: users' preferences are affected by the items they are recommended, while creators are incentivized to alter their contents such that it is recommended more frequently. We define a model, called user-creator feature dynamics, to capture the dual influences of recommender systems. We prove that a recommender system with dual influence is guaranteed to polarize, causing diversity loss in the system. We then investigate, both theoretically and empirically, approaches for mitigating polarization and promoting diversity in recommender systems. Unexpectedly, we find that common diversity-promoting approaches do not work in the presence of dual influence, while relevancy-optimizing methods like top-$k$ recommendation can prevent polarization and improve diversity of the system.
An Outline of Prognostics and Health Management Large Model: Concepts, Paradigms, and Challenges
Jul 01, 2024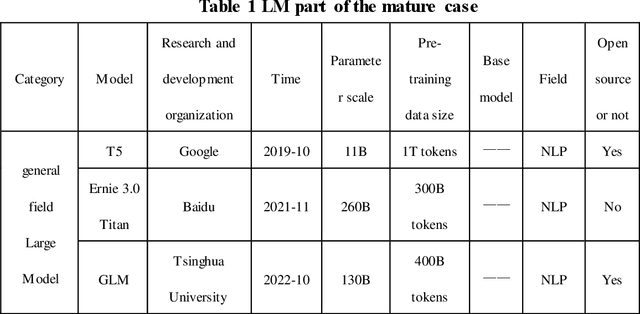
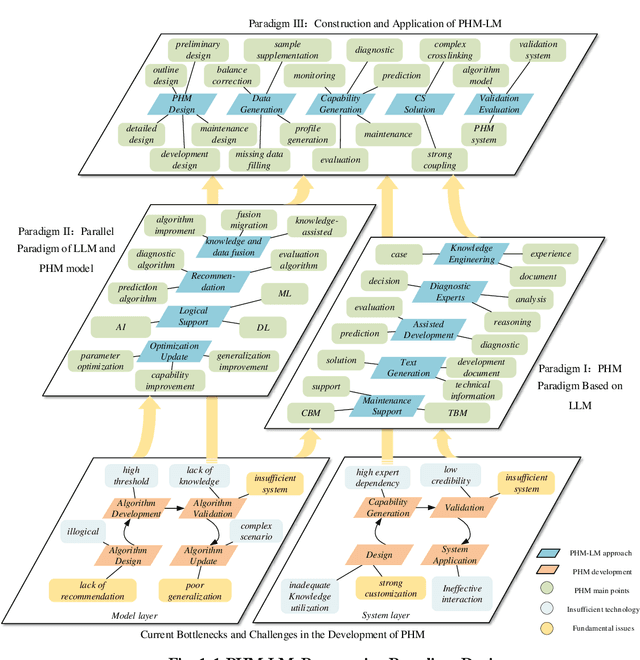
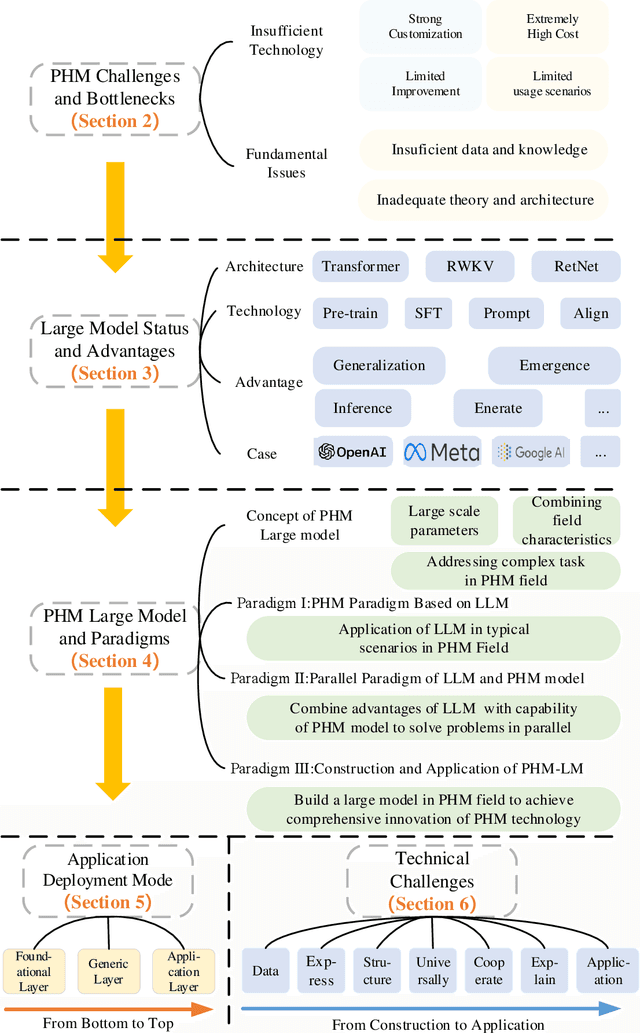
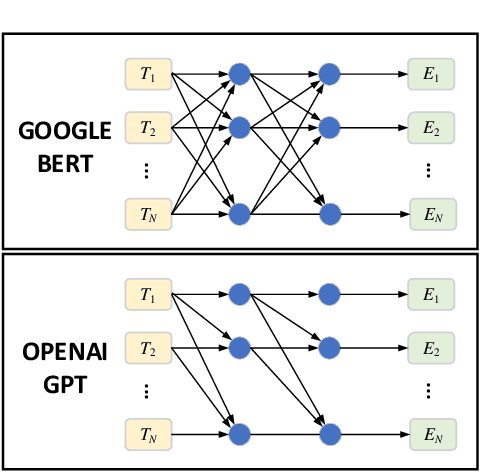
Prognosis and Health Management (PHM), critical for ensuring task completion by complex systems and preventing unexpected failures, is widely adopted in aerospace, manufacturing, maritime, rail, energy, etc. However, PHM's development is constrained by bottlenecks like generalization, interpretation and verification abilities. Presently, generative artificial intelligence (AI), represented by Large Model, heralds a technological revolution with the potential to fundamentally reshape traditional technological fields and human production methods. Its capabilities, including strong generalization, reasoning, and generative attributes, present opportunities to address PHM's bottlenecks. To this end, based on a systematic analysis of the current challenges and bottlenecks in PHM, as well as the research status and advantages of Large Model, we propose a novel concept and three progressive paradigms of Prognosis and Health Management Large Model (PHM-LM) through the integration of the Large Model with PHM. Subsequently, we provide feasible technical approaches for PHM-LM to bolster PHM's core capabilities within the framework of the three paradigms. Moreover, to address core issues confronting PHM, we discuss a series of technical challenges of PHM-LM throughout the entire process of construction and application. This comprehensive effort offers a holistic PHM-LM technical framework, and provides avenues for new PHM technologies, methodologies, tools, platforms and applications, which also potentially innovates design, research & development, verification and application mode of PHM. And furthermore, a new generation of PHM with AI will also capably be realized, i.e., from custom to generalized, from discriminative to generative, and from theoretical conditions to practical applications.
FedStaleWeight: Buffered Asynchronous Federated Learning with Fair Aggregation via Staleness Reweighting
Jun 05, 2024

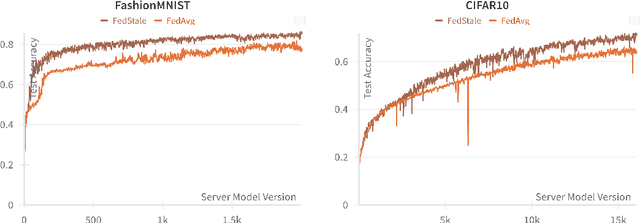
Federated Learning (FL) endeavors to harness decentralized data while preserving privacy, facing challenges of performance, scalability, and collaboration. Asynchronous Federated Learning (AFL) methods have emerged as promising alternatives to their synchronous counterparts bounded by the slowest agent, yet they add additional challenges in convergence guarantees, fairness with respect to compute heterogeneity, and incorporation of staleness in aggregated updates. Specifically, AFL biases model training heavily towards agents who can produce updates faster, leaving slower agents behind, who often also have differently distributed data which is not learned by the global model. Naively upweighting introduces incentive issues, where true fast updating agents may falsely report updates at a slower speed to increase their contribution to model training. We introduce FedStaleWeight, an algorithm addressing fairness in aggregating asynchronous client updates by employing average staleness to compute fair re-weightings. FedStaleWeight reframes asynchronous federated learning aggregation as a mechanism design problem, devising a weighting strategy that incentivizes truthful compute speed reporting without favoring faster update-producing agents by upweighting agent updates based on staleness. Leveraging only observed agent update staleness, FedStaleWeight results in more equitable aggregation on a per-agent basis. We both provide theoretical convergence guarantees in the smooth, non-convex setting and empirically compare FedStaleWeight against the commonly used asynchronous FedBuff with gradient averaging, demonstrating how it achieves stronger fairness, expediting convergence to a higher global model accuracy. Finally, we provide an open-source test bench to facilitate exploration of buffered AFL aggregation strategies, fostering further research in asynchronous federated learning paradigms.
Persuading a Learning Agent
Feb 22, 2024We study a repeated Bayesian persuasion problem (and more generally, any generalized principal-agent problem with complete information) where the principal does not have commitment power and the agent uses algorithms to learn to respond to the principal's signals. We reduce this problem to a one-shot generalized principal-agent problem with an approximately-best-responding agent. This reduction allows us to show that: if the agent uses contextual no-regret learning algorithms, then the principal can guarantee a utility that is arbitrarily close to the principal's optimal utility in the classic non-learning model with commitment; if the agent uses contextual no-swap-regret learning algorithms, then the principal cannot obtain any utility significantly more than the optimal utility in the non-learning model with commitment. The difference between the principal's obtainable utility in the learning model and the non-learning model is bounded by the agent's regret (swap-regret). If the agent uses mean-based learning algorithms (which can be no-regret but not no-swap-regret), then the principal can do significantly better than the non-learning model. These conclusions hold not only for Bayesian persuasion, but also for any generalized principal-agent problem with complete information, including Stackelberg games and contract design.
Social Environment Design
Feb 21, 2024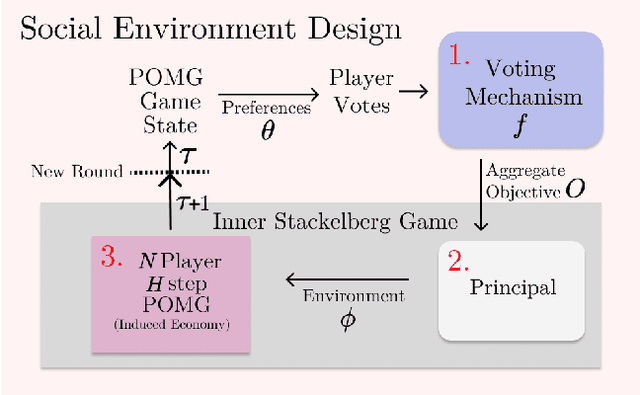
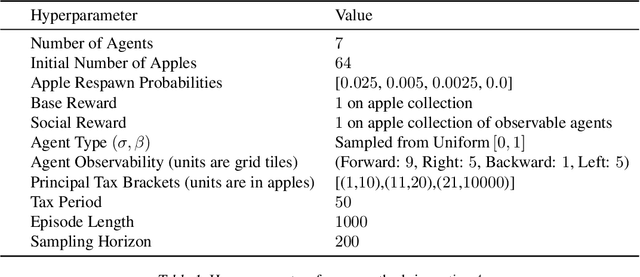
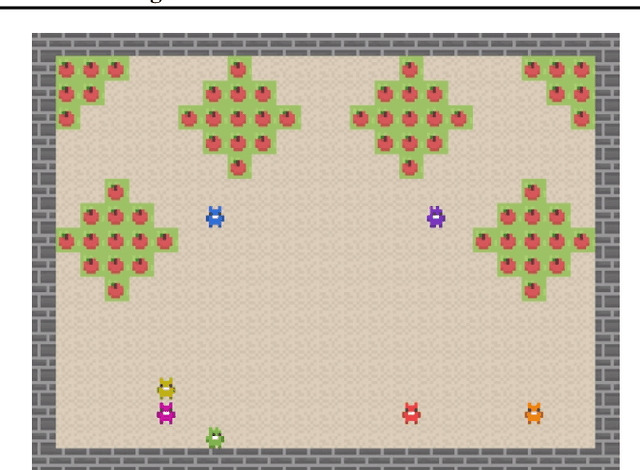
Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.
Multi-Sender Persuasion -- A Computational Perspective
Feb 08, 2024



We consider multiple senders with informational advantage signaling to convince a single self-interested actor towards certain actions. Generalizing the seminal Bayesian Persuasion framework, such settings are ubiquitous in computational economics, multi-agent learning, and machine learning with multiple objectives. The core solution concept here is the Nash equilibrium of senders' signaling policies. Theoretically, we prove that finding an equilibrium in general is PPAD-Hard; in fact, even computing a sender's best response is NP-Hard. Given these intrinsic difficulties, we turn to finding local Nash equilibria. We propose a novel differentiable neural network to approximate this game's non-linear and discontinuous utilities. Complementing this with the extra-gradient algorithm, we discover local equilibria that Pareto dominates full-revelation equilibria and those found by existing neural networks. Broadly, our theoretical and empirical contributions are of interest to a large class of economic problems.
Equilibrium and Learning in Fixed-Price Data Markets with Externality
Feb 16, 2023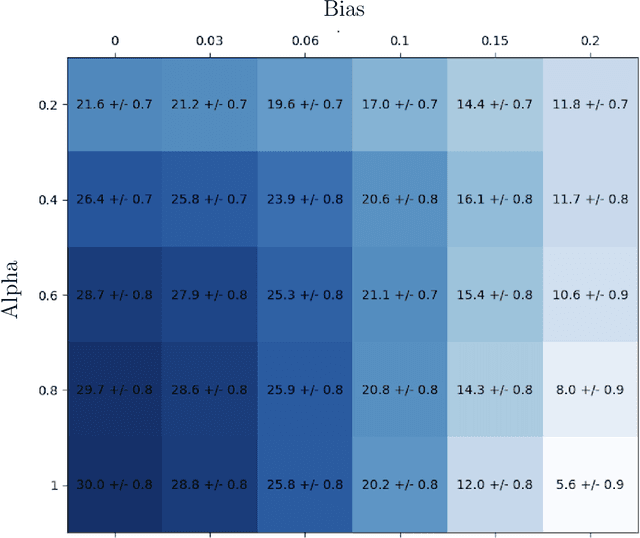
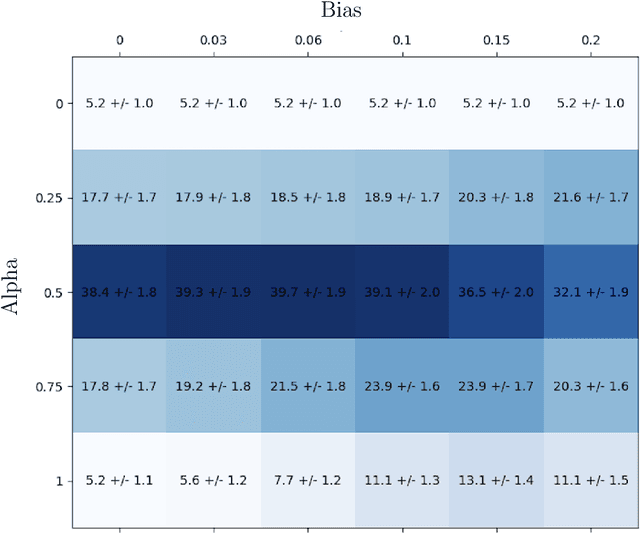
We propose modeling real-world data markets, where sellers post fixed prices and buyers are free to purchase from any set of sellers they please, as a simultaneous-move game between the buyers. A key component of this model is the negative externality buyers induce on one another due to purchasing similar data, a phenomenon exacerbated by its easy replicability. In the complete-information setting, where all buyers know their valuations, we characterize both the existence and the quality (with respect to optimal social welfare) of the pure-strategy Nash equilibrium under various models of buyer externality. While this picture is bleak without any market intervention, reinforcing the inadequacy of modern data markets, we prove that for a broad class of externality functions, market intervention in the form of a revenue-neutral transaction cost can lead to a pure-strategy equilibrium with strong welfare guarantees. We further show that this intervention is amenable to the more realistic setting where buyers start with unknown valuations and learn them over time through repeated market interactions. For such a setting, we provide an online learning algorithm for each buyer that achieves low regret guarantees with respect to both individual buyers' strategy and social welfare optimal. Our work paves the way for considering simple intervention strategies for existing fixed-price data markets to address their shortcoming and the unique challenges put forth by data products.