 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Reasoning with Less Data: Enhancing VLMs Through Unified Modality Scoring
Jun 10, 2025
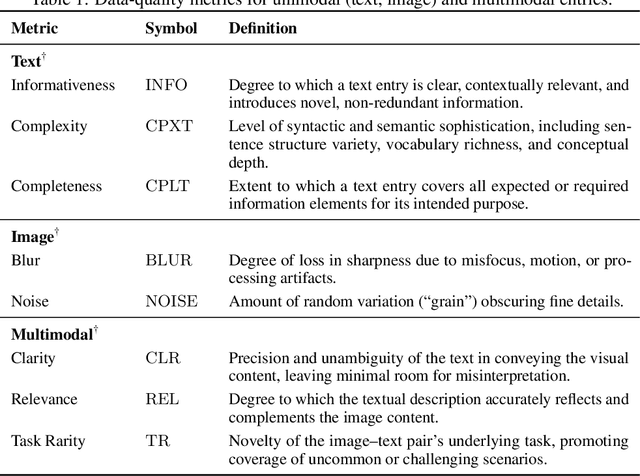
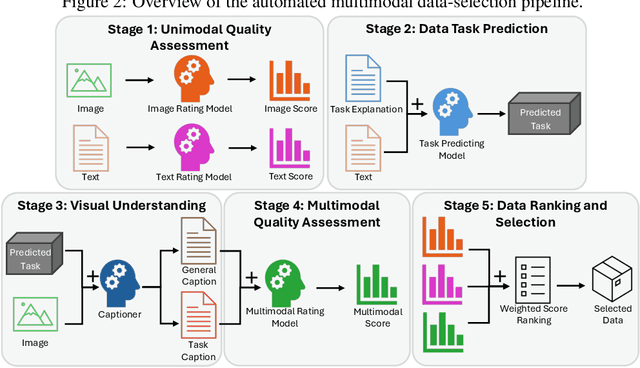
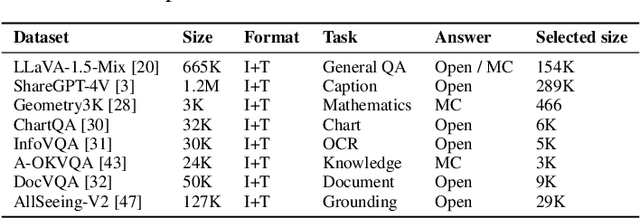
The application of visual instruction tuning and other post-training techniques has significantly enhanced the capabilities of Large Language Models (LLMs) in visual understanding, enriching Vision-Language Models (VLMs) with more comprehensive visual language datasets. However, the effectiveness of VLMs is highly dependent on large-scale, high-quality datasets that ensure precise recognition and accurate reasoning. Two key challenges hinder progress: (1) noisy alignments between images and the corresponding text, which leads to misinterpretation, and (2) ambiguous or misleading text, which obscures visual content. To address these challenges, we propose SCALE (Single modality data quality and Cross modality Alignment Evaluation), a novel quality-driven data selection pipeline for VLM instruction tuning datasets. Specifically, SCALE integrates a cross-modality assessment framework that first assigns each data entry to its appropriate vision-language task, generates general and task-specific captions (covering scenes, objects, style, etc.), and evaluates the alignment, clarity, task rarity, text coherence, and image clarity of each entry based on the generated captions. We reveal that: (1) current unimodal quality assessment methods evaluate one modality while overlooking the rest, which can underestimate samples essential for specific tasks and discard the lower-quality instances that help build model robustness; and (2) appropriately generated image captions provide an efficient way to transfer the image-text multimodal task into a unified text modality.
To Give or Not to Give? The Impacts of Strategically Withheld Recourse
Apr 08, 2025Individuals often aim to reverse undesired outcomes in interactions with automated systems, like loan denials, by either implementing system-recommended actions (recourse), or manipulating their features. While providing recourse benefits users and enhances system utility, it also provides information about the decision process that can be used for more effective strategic manipulation, especially when the individuals collectively share such information with each other. We show that this tension leads rational utility-maximizing systems to frequently withhold recourse, resulting in decreased population utility, particularly impacting sensitive groups. To mitigate these effects, we explore the role of recourse subsidies, finding them effective in increasing the provision of recourse actions by rational systems, as well as lowering the potential social cost and mitigating unfairness caused by recourse withholding.
ACC-Debate: An Actor-Critic Approach to Multi-Agent Debate
Nov 04, 2024Large language models (LLMs) have demonstrated a remarkable ability to serve as general-purpose tools for various language-based tasks. Recent works have demonstrated that the efficacy of such models can be improved through iterative dialog between multiple models, frequently referred to as multi-agent debate (MAD). While debate shows promise as a means of improving model efficacy, most works in this area treat debate as an emergent behavior, rather than a learned behavior. In doing so, current debate frameworks rely on collaborative behaviors to have been sufficiently trained into off-the-shelf models. To address this limitation, we propose ACC-Debate, an Actor-Critic based learning framework to produce a two-agent team specialized in debate. We demonstrate that ACC-Debate outperforms SotA debate techniques on a wide array of benchmarks.
Adaptive Recruitment Resource Allocation to Improve Cohort Representativeness in Participatory Biomedical Datasets
Aug 02, 2024Large participatory biomedical studies, studies that recruit individuals to join a dataset, are gaining popularity and investment, especially for analysis by modern AI methods. Because they purposively recruit participants, these studies are uniquely able to address a lack of historical representation, an issue that has affected many biomedical datasets. In this work, we define representativeness as the similarity to a target population distribution of a set of attributes and our goal is to mirror the U.S. population across distributions of age, gender, race, and ethnicity. Many participatory studies recruit at several institutions, so we introduce a computational approach to adaptively allocate recruitment resources among sites to improve representativeness. In simulated recruitment of 10,000-participant cohorts from medical centers in the STAR Clinical Research Network, we show that our approach yields a more representative cohort than existing baselines. Thus, we highlight the value of computational modeling in guiding recruitment efforts.
User-Creator Feature Dynamics in Recommender Systems with Dual Influence
Jul 19, 2024



Recommender systems present relevant contents to users and help content creators reach their target audience. The dual nature of these systems influences both users and creators: users' preferences are affected by the items they are recommended, while creators are incentivized to alter their contents such that it is recommended more frequently. We define a model, called user-creator feature dynamics, to capture the dual influences of recommender systems. We prove that a recommender system with dual influence is guaranteed to polarize, causing diversity loss in the system. We then investigate, both theoretically and empirically, approaches for mitigating polarization and promoting diversity in recommender systems. Unexpectedly, we find that common diversity-promoting approaches do not work in the presence of dual influence, while relevancy-optimizing methods like top-$k$ recommendation can prevent polarization and improve diversity of the system.
Dataset Representativeness and Downstream Task Fairness
Jun 28, 2024



Our society collects data on people for a wide range of applications, from building a census for policy evaluation to running meaningful clinical trials. To collect data, we typically sample individuals with the goal of accurately representing a population of interest. However, current sampling processes often collect data opportunistically from data sources, which can lead to datasets that are biased and not representative, i.e., the collected dataset does not accurately reflect the distribution of demographics of the true population. This is a concern because subgroups within the population can be under- or over-represented in a dataset, which may harm generalizability and lead to an unequal distribution of benefits and harms from downstream tasks that use such datasets (e.g., algorithmic bias in medical decision-making algorithms). In this paper, we assess the relationship between dataset representativeness and group-fairness of classifiers trained on that dataset. We demonstrate that there is a natural tension between dataset representativeness and classifier fairness; empirically we observe that training datasets with better representativeness can frequently result in classifiers with higher rates of unfairness. We provide some intuition as to why this occurs via a set of theoretical results in the case of univariate classifiers. We also find that over-sampling underrepresented groups can result in classifiers which exhibit greater bias to those groups. Lastly, we observe that fairness-aware sampling strategies (i.e., those which are specifically designed to select data with high downstream fairness) will often over-sample members of majority groups. These results demonstrate that the relationship between dataset representativeness and downstream classifier fairness is complex; balancing these two quantities requires special care from both model- and dataset-designers.
Measuring and Reducing LLM Hallucination without Gold-Standard Answers via Expertise-Weighting
Feb 16, 2024LLM hallucination, i.e. generating factually incorrect yet seemingly convincing answers, is currently a major threat to the trustworthiness and reliability of LLMs. The first step towards solving this complicated problem is to measure it. However, existing hallucination metrics require to have a benchmark dataset with gold-standard answers, i.e. "best" or "correct" answers written by humans. Such requirement makes hallucination measurement costly and prone to human errors. In this work, we propose Factualness Evaluations via Weighting LLMs (FEWL), the first hallucination metric that is specifically designed for the scenario when gold-standard answers are absent. FEWL leverages the answers from off-the-shelf LLMs that serve as a proxy of gold-standard answers. The key challenge is how to quantify the expertise of reference LLMs resourcefully. We show FEWL has certain theoretical guarantees and demonstrate empirically it gives more accurate hallucination measures than naively using reference LLMs. We also show how to leverage FEWL to reduce hallucination through both in-context learning and supervised finetuning. Last, we build a large-scale benchmark dataset to facilitate LLM hallucination research.
Unfairness Despite Awareness: Group-Fair Classification with Strategic Agents
Dec 06, 2021



The use of algorithmic decision making systems in domains which impact the financial, social, and political well-being of people has created a demand for these decision making systems to be "fair" under some accepted notion of equity. This demand has in turn inspired a large body of work focused on the development of fair learning algorithms which are then used in lieu of their conventional counterparts. Most analysis of such fair algorithms proceeds from the assumption that the people affected by the algorithmic decisions are represented as immutable feature vectors. However, strategic agents may possess both the ability and the incentive to manipulate this observed feature vector in order to attain a more favorable outcome. We explore the impact that strategic agent behavior could have on fair classifiers and derive conditions under which this behavior leads to fair classifiers becoming less fair than their conventional counterparts under the same measure of fairness that the fair classifier takes into account. These conditions are related to the the way in which the fair classifier remedies unfairness on the original unmanipulated data: fair classifiers which remedy unfairness by becoming more selective than their conventional counterparts are the ones that become less fair than their counterparts when agents are strategic. We further demonstrate that both the increased selectiveness of the fair classifier, and consequently the loss of fairness, arises when performing fair learning on domains in which the advantaged group is overrepresented in the region near (and on the beneficial side of) the decision boundary of conventional classifiers. Finally, we observe experimentally, using several datasets and learning methods, that this fairness reversal is common, and that our theoretical characterization of the fairness reversal conditions indeed holds in most such cases.
Deception through Half-Truths
Nov 14, 2019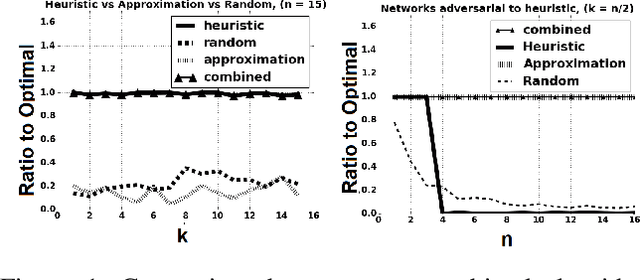
Deception is a fundamental issue across a diverse array of settings, from cybersecurity, where decoys (e.g., honeypots) are an important tool, to politics that can feature politically motivated "leaks" and fake news about candidates.Typical considerations of deception view it as providing false information.However, just as important but less frequently studied is a more tacit form where information is strategically hidden or leaked.We consider the problem of how much an adversary can affect a principal's decision by "half-truths", that is, by masking or hiding bits of information, when the principal is oblivious to the presence of the adversary. The principal's problem can be modeled as one of predicting future states of variables in a dynamic Bayes network, and we show that, while theoretically the principal's decisions can be made arbitrarily bad, the optimal attack is NP-hard to approximate, even under strong assumptions favoring the attacker. However, we also describe an important special case where the dependency of future states on past states is additive, in which we can efficiently compute an approximately optimal attack. Moreover, in networks with a linear transition function we can solve the problem optimally in polynomial time.