 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODEBLOCK: Learning to Supervise Code at the Right Granularity
Jun 10, 2026Supervised fine-tuning of code LLMs typically applies uniform cross-entropy loss to all response tokens, implicitly assuming that every token provides equally useful learning signal. Recent token-level selection methods challenge this assumption in natural-language SFT by supervising only high-value tokens. However, directly transferring token-level masking to code can break syntactically and semantically coherent program units, because code depends on structural completeness and definition-use relations. We therefore propose CodeBlock, a structure-aware sparse supervision framework that selects structure-complete code evidence rather than isolated tokens. CodeBlock first selects high-quality instruction-response pairs, then partitions code responses into syntactically coherent coding items, estimates their utility by aggregating generalized cross-entropy over core logic tokens, and reranks them with data-flow reach and bridge signals to prioritize blocks that propagate or connect important program dependencies. During training, the full response remains available as context, while loss is applied only to selected code items and informative natural-language tokens. Experiments on six code-generation benchmarks show that CodeBlock achieves stronger average pass@1 than full-token SFT and competitive selection baselines, while using only 1.9% of supervised response tokens.
Small-Margin Preferences Still Matter-If You Train Them Right
Feb 01, 2026Preference optimization methods such as DPO align large language models (LLMs) using paired comparisons, but their effectiveness can be highly sensitive to the quality and difficulty of preference pairs. A common heuristic treats small-margin (ambiguous) pairs as noisy and filters them out. In this paper, we revisit this assumption and show that pair difficulty interacts strongly with the optimization objective: when trained with preference-based losses, difficult pairs can destabilize training and harm alignment, yet these same pairs still contain useful supervision signals when optimized with supervised fine-tuning (SFT). Motivated by this observation, we propose MixDPO, a simple yet effective difficulty-aware training strategy that (i) orders preference data from easy to hard (a curriculum over margin-defined difficulty), and (ii) routes difficult pairs to an SFT objective while applying a preference loss to easy pairs. This hybrid design provides a practical mechanism to leverage ambiguous pairs without incurring the optimization failures often associated with preference losses on low-margin data. Across three LLM-judge benchmarks, MixDPO consistently improves alignment over DPO and a range of widely-used variants, with particularly strong gains on AlpacaEval~2 length-controlled (LC) win rate.
OFFSIDE: Benchmarking Unlearning Misinformation in Multimodal Large Language Models
Oct 26, 2025Advances in Multimodal Large Language Models (MLLMs) intensify concerns about data privacy, making Machine Unlearning (MU), the selective removal of learned information, a critical necessity. However, existing MU benchmarks for MLLMs are limited by a lack of image diversity, potential inaccuracies, and insufficient evaluation scenarios, which fail to capture the complexity of real-world applications. To facilitate the development of MLLMs unlearning and alleviate the aforementioned limitations, we introduce OFFSIDE, a novel benchmark for evaluating misinformation unlearning in MLLMs based on football transfer rumors. This manually curated dataset contains 15.68K records for 80 players, providing a comprehensive framework with four test sets to assess forgetting efficacy, generalization, utility, and robustness. OFFSIDE supports advanced settings like selective unlearning and corrective relearning, and crucially, unimodal unlearning (forgetting only text data). Our extensive evaluation of multiple baselines reveals key findings: (1) Unimodal methods (erasing text-based knowledge) fail on multimodal rumors; (2) Unlearning efficacy is largely driven by catastrophic forgetting; (3) All methods struggle with "visual rumors" (rumors appear in the image); (4) The unlearned rumors can be easily recovered and (5) All methods are vulnerable to prompt attacks. These results expose significant vulnerabilities in current approaches, highlighting the need for more robust multimodal unlearning solutions. The code is available at \href{https://github.com/zh121800/OFFSIDE}{https://github.com/zh121800/OFFSIDE}.
LM-mixup: Text Data Augmentation via Language Model based Mixup
Oct 23, 2025Instruction tuning is crucial for aligning Large Language Models (LLMs), yet the quality of instruction-following data varies significantly. While high-quality data is paramount, it is often scarce; conversely, abundant low-quality data is frequently discarded, leading to substantial information loss. Existing data augmentation methods struggle to augment this low-quality data effectively, and the evaluation of such techniques remains poorly defined. To address this, we formally define the task of Instruction Distillation: distilling multiple low-quality and redundant inputs into high-quality and coherent instruction-output pairs. Specifically, we introduce a comprehensive data construction pipeline to create MIXTURE, a 144K-sample dataset pairing low-quality or semantically redundant imperfect instruction clusters with their high-quality distillations. We then introduce LM-Mixup, by first performing supervised fine-tuning on MIXTURE and then optimizing it with reinforcement learning. This process uses three complementary reward signals: quality, semantic alignment, and format compliance, via Group Relative Policy Optimization (GRPO). We demonstrate that LM-Mixup effectively augments imperfect datasets: fine-tuning LLMs on its distilled data, which accounts for only about 3% of the entire dataset, not only surpasses full-dataset training but also competes with state-of-the-art high-quality data selection methods across multiple benchmarks. Our work establishes that low-quality data is a valuable resource when properly distilled and augmented with LM-Mixup, significantly enhancing the efficiency and performance of instruction-tuned LLMs.
Better Reasoning with Less Data: Enhancing VLMs Through Unified Modality Scoring
Jun 10, 2025
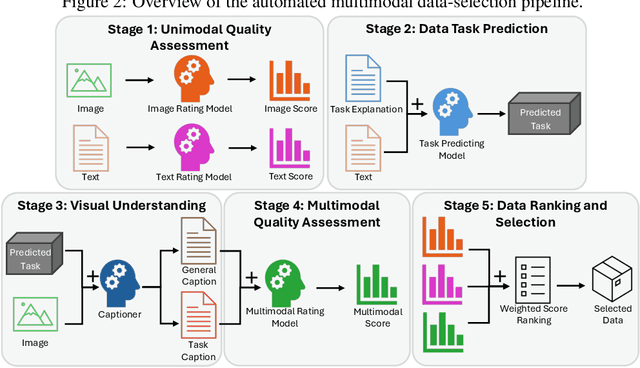
The application of visual instruction tuning and other post-training techniques has significantly enhanced the capabilities of Large Language Models (LLMs) in visual understanding, enriching Vision-Language Models (VLMs) with more comprehensive visual language datasets. However, the effectiveness of VLMs is highly dependent on large-scale, high-quality datasets that ensure precise recognition and accurate reasoning. Two key challenges hinder progress: (1) noisy alignments between images and the corresponding text, which leads to misinterpretation, and (2) ambiguous or misleading text, which obscures visual content. To address these challenges, we propose SCALE (Single modality data quality and Cross modality Alignment Evaluation), a novel quality-driven data selection pipeline for VLM instruction tuning datasets. Specifically, SCALE integrates a cross-modality assessment framework that first assigns each data entry to its appropriate vision-language task, generates general and task-specific captions (covering scenes, objects, style, etc.), and evaluates the alignment, clarity, task rarity, text coherence, and image clarity of each entry based on the generated captions. We reveal that: (1) current unimodal quality assessment methods evaluate one modality while overlooking the rest, which can underestimate samples essential for specific tasks and discard the lower-quality instances that help build model robustness; and (2) appropriately generated image captions provide an efficient way to transfer the image-text multimodal task into a unified text modality.
Evaluating LLM-corrupted Crowdsourcing Data Without Ground Truth
Jun 08, 2025The recent success of generative AI highlights the crucial role of high-quality human feedback in building trustworthy AI systems. However, the increasing use of large language models (LLMs) by crowdsourcing workers poses a significant challenge: datasets intended to reflect human input may be compromised by LLM-generated responses. Existing LLM detection approaches often rely on high-dimension training data such as text, making them unsuitable for annotation tasks like multiple-choice labeling. In this work, we investigate the potential of peer prediction -- a mechanism that evaluates the information within workers' responses without using ground truth -- to mitigate LLM-assisted cheating in crowdsourcing with a focus on annotation tasks. Our approach quantifies the correlations between worker answers while conditioning on (a subset of) LLM-generated labels available to the requester. Building on prior research, we propose a training-free scoring mechanism with theoretical guarantees under a crowdsourcing model that accounts for LLM collusion. We establish conditions under which our method is effective and empirically demonstrate its robustness in detecting low-effort cheating on real-world crowdsourcing datasets.
GUARD: Generation-time LLM Unlearning via Adaptive Restriction and Detection
May 19, 2025Large Language Models (LLMs) have demonstrated strong capabilities in memorizing vast amounts of knowledge across diverse domains. However, the ability to selectively forget specific knowledge is critical for ensuring the safety and compliance of deployed models. Existing unlearning efforts typically fine-tune the model with resources such as forget data, retain data, and a calibration model. These additional gradient steps blur the decision boundary between forget and retain knowledge, making unlearning often at the expense of overall performance. To avoid the negative impact of fine-tuning, it would be better to unlearn solely at inference time by safely guarding the model against generating responses related to the forget target, without destroying the fluency of text generation. In this work, we propose Generation-time Unlearning via Adaptive Restriction and Detection (GUARD), a framework that enables dynamic unlearning during LLM generation. Specifically, we first employ a prompt classifier to detect unlearning targets and extract the corresponding forbidden token. We then dynamically penalize and filter candidate tokens during generation using a combination of token matching and semantic matching, effectively preventing the model from leaking the forgotten content. Experimental results on copyright content unlearning tasks over the Harry Potter dataset and the MUSE benchmark, as well as entity unlearning tasks on the TOFU dataset, demonstrate that GUARD achieves strong forget quality across various tasks while causing almost no degradation to the LLM's general capabilities, striking an excellent trade-off between forgetting and utility.
Token Cleaning: Fine-Grained Data Selection for LLM Supervised Fine-Tuning
Feb 04, 2025



Recent studies show that in supervised fine-tuning (SFT) of large language models (LLMs), data quality matters more than quantity. While most data cleaning methods concentrate on filtering entire samples, the quality of individual tokens within a sample can vary significantly. After pre-training, even in high-quality samples, patterns or phrases that are not task-related can be redundant or uninformative. Continuing to fine-tune on these patterns may offer limited benefit and even degrade downstream task performance. In this paper, we investigate token quality from a noisy-label perspective and propose a generic token cleaning pipeline for SFT tasks. Our method filters out uninformative tokens while preserving those carrying key task-specific information. Specifically, we first evaluate token quality by examining the influence of model updates on each token, then apply a threshold-based separation. The token influence can be measured in a single pass with a fixed reference model or iteratively with self-evolving reference models. The benefits and limitations of both methods are analyzed theoretically by error upper bounds. Extensive experiments show that our framework consistently improves performance across multiple downstream tasks.
Noise-Resilient Point-wise Anomaly Detection in Time Series Using Weak Segment Labels
Jan 21, 2025



Detecting anomalies in temporal data has gained significant attention across various real-world applications, aiming to identify unusual events and mitigate potential hazards. In practice, situations often involve a mix of segment-level labels (detected abnormal events with segments of time points) and unlabeled data (undetected events), while the ideal algorithmic outcome should be point-level predictions. Therefore, the huge label information gap between training data and targets makes the task challenging. In this study, we formulate the above imperfect information as noisy labels and propose NRdetector, a noise-resilient framework that incorporates confidence-based sample selection, robust segment-level learning, and data-centric point-level detection for multivariate time series anomaly detection. Particularly, to bridge the information gap between noisy segment-level labels and missing point-level labels, we develop a novel loss function that can effectively mitigate the label noise and consider the temporal features. It encourages the smoothness of consecutive points and the separability of points from segments with different labels. Extensive experiments on real-world multivariate time series datasets with 11 different evaluation metrics demonstrate that NRdetector consistently achieves robust results across multiple real-world datasets, outperforming various baselines adapted to operate in our setting.
Reassessing Layer Pruning in LLMs: New Insights and Methods
Nov 23, 2024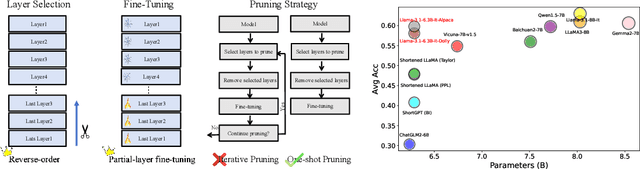
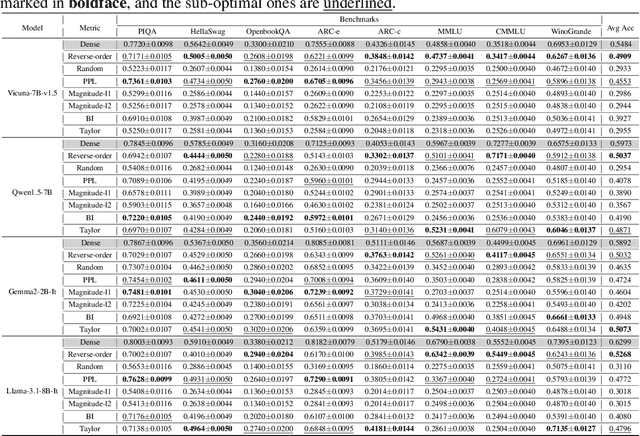
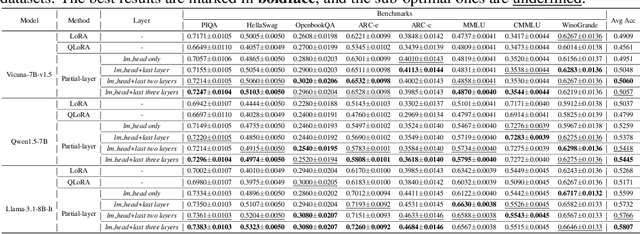
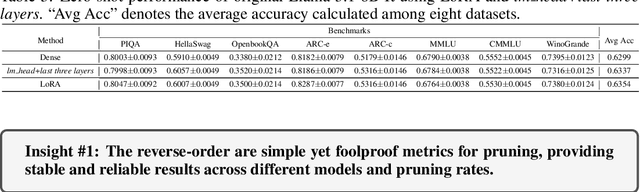
Although large language models (LLMs) have achieved remarkable success across various domains, their considerable scale necessitates substantial computational resources, posing significant challenges for deployment in resource-constrained environments. Layer pruning, as a simple yet effective compression method, removes layers of a model directly, reducing computational overhead. However, what are the best practices for layer pruning in LLMs? Are sophisticated layer selection metrics truly effective? Does the LoRA (Low-Rank Approximation) family, widely regarded as a leading method for pruned model fine-tuning, truly meet expectations when applied to post-pruning fine-tuning? To answer these questions, we dedicate thousands of GPU hours to benchmarking layer pruning in LLMs and gaining insights across multiple dimensions. Our results demonstrate that a simple approach, i.e., pruning the final 25\% of layers followed by fine-tuning the \texttt{lm\_head} and the remaining last three layer, yields remarkably strong performance. Following this guide, we prune Llama-3.1-8B-It and obtain a model that outperforms many popular LLMs of similar size, such as ChatGLM2-6B, Vicuna-7B-v1.5, Qwen1.5-7B and Baichuan2-7B. We release the optimal model weights on Huggingface, and the code is available on GitHub.