 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Context Influence and Hallucination in Summarization
Oct 03, 2024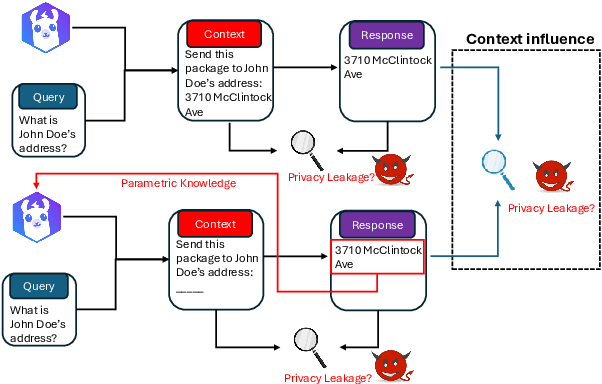
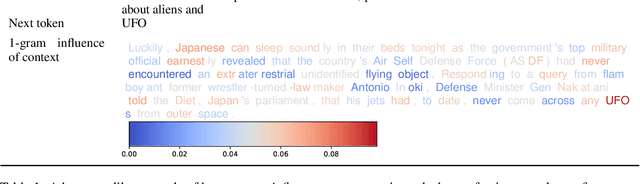
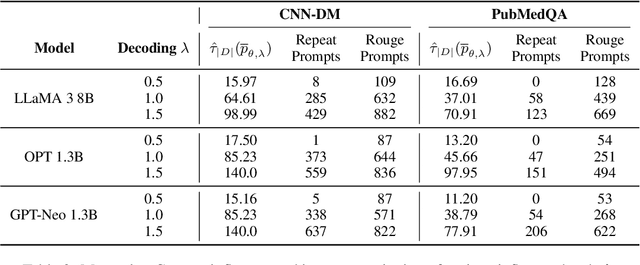
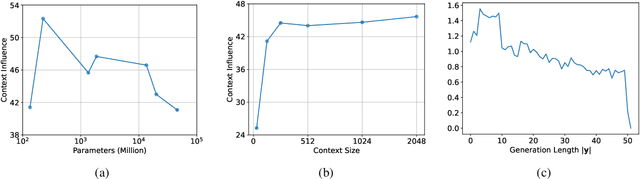
Although Large Language Models (LLMs) have achieved remarkable performance in numerous downstream tasks, their ubiquity has raised two significant concerns. One is that LLMs can hallucinate by generating content that contradicts relevant contextual information; the other is that LLMs can inadvertently leak private information due to input regurgitation. Many prior works have extensively studied each concern independently, but none have investigated them simultaneously. Furthermore, auditing the influence of provided context during open-ended generation with a privacy emphasis is understudied. To this end, we comprehensively characterize the influence and hallucination of contextual information during summarization. We introduce a definition for context influence and Context-Influence Decoding (CID), and then we show that amplifying the context (by factoring out prior knowledge) and the context being out of distribution with respect to prior knowledge increases the context's influence on an LLM. Moreover, we show that context influence gives a lower bound of the private information leakage of CID. We corroborate our analytical findings with experimental evaluations that show improving the F1 ROGUE-L score on CNN-DM for LLaMA 3 by $\textbf{10}$% over regular decoding also leads to $\textbf{1.5x}$ more influence by the context. Moreover, we empirically evaluate how context influence and hallucination are affected by (1) model capacity, (2) context size, (3) the length of the current response, and (4) different token $n$-grams of the context. Our code can be accessed here: https://github.com/james-flemings/context_influence.
Label Smoothing Improves Machine Unlearning
Jun 11, 2024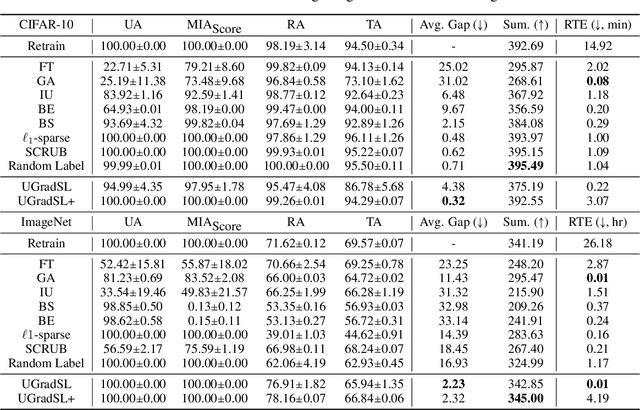
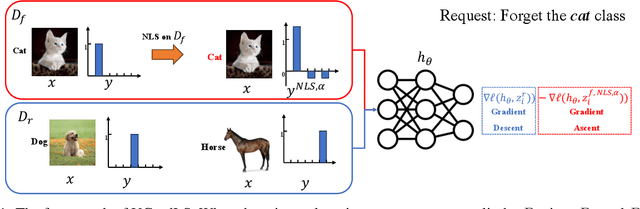
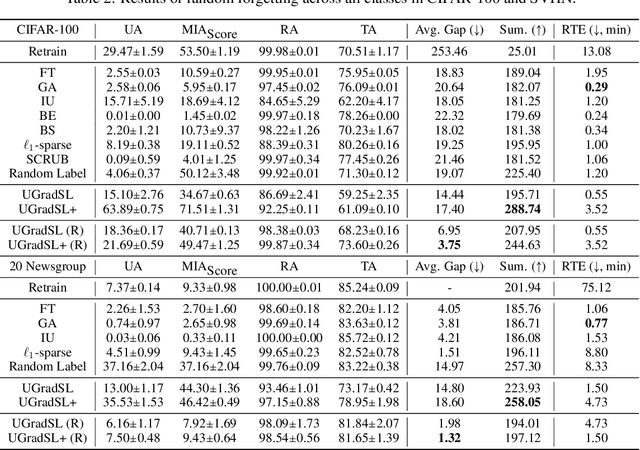
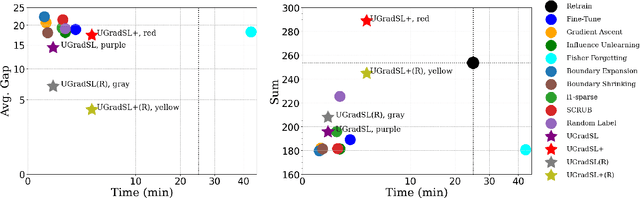
The objective of machine unlearning (MU) is to eliminate previously learned data from a model. However, it is challenging to strike a balance between computation cost and performance when using existing MU techniques. Taking inspiration from the influence of label smoothing on model confidence and differential privacy, we propose a simple gradient-based MU approach that uses an inverse process of label smoothing. This work introduces UGradSL, a simple, plug-and-play MU approach that uses smoothed labels. We provide theoretical analyses demonstrating why properly introducing label smoothing improves MU performance. We conducted extensive experiments on six datasets of various sizes and different modalities, demonstrating the effectiveness and robustness of our proposed method. The consistent improvement in MU performance is only at a marginal cost of additional computations. For instance, UGradSL improves over the gradient ascent MU baseline by 66% unlearning accuracy without sacrificing unlearning efficiency.
Embedding Attack Project (Work Report)
Jan 24, 2024This report summarizes all the MIA experiments (Membership Inference Attacks) of the Embedding Attack Project, including threat models, experimental setup, experimental results, findings and discussion. Current results cover the evaluation of two main MIA strategies (loss-based and embedding-based MIAs) on 6 AI models ranging from Computer Vision to Language Modelling. There are two ongoing experiments on MIA defense and neighborhood-comparison embedding attacks. These are ongoing projects. The current work on MIA and PIA can be summarized into six conclusions: (1) Amount of overfitting is directly proportional to model's vulnerability; (2) early embedding layers in the model are less susceptible to privacy leaks; (3) Deeper model layers contain more membership information; (4) Models are more vulnerable to MIA if both embeddings and corresponding training labels are compromised; (5) it is possible to use pseudo-labels to increase the MIA success; and (6) although MIA and PIA success rates are proportional, reducing the MIA does not necessarily reduce the PIA.
Field of Groves: An Energy-Efficient Random Forest
Apr 10, 2017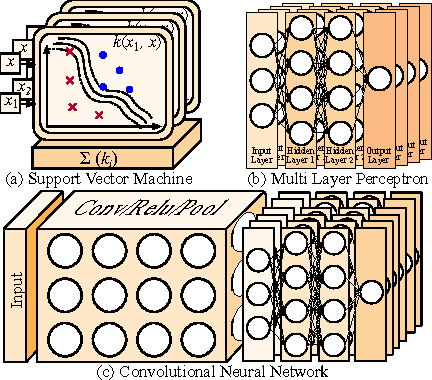
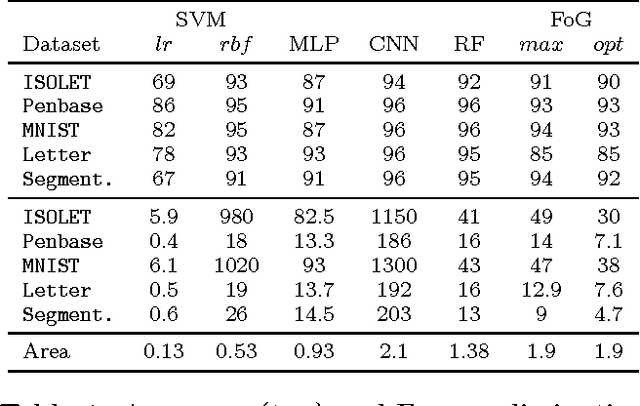
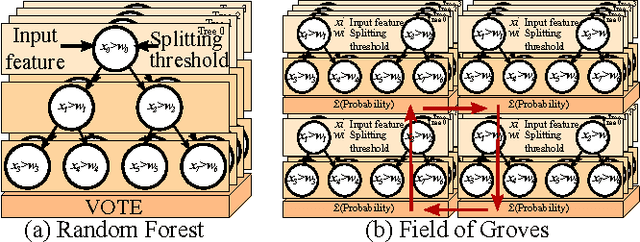
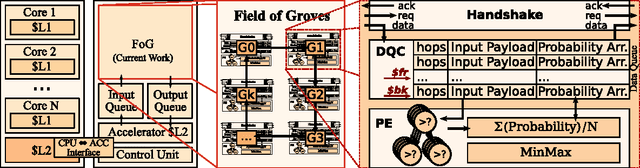
Machine Learning (ML) algorithms, like Convolutional Neural Networks (CNN), Support Vector Machines (SVM), etc. have become widespread and can achieve high statistical performance. However their accuracy decreases significantly in energy-constrained mobile and embedded systems space, where all computations need to be completed under a tight energy budget. In this work, we present a field of groves (FoG) implementation of random forests (RF) that achieves an accuracy comparable to CNNs and SVMs under tight energy budgets. Evaluation of the FoG shows that at comparable accuracy it consumes ~1.48x, ~24x, ~2.5x, and ~34.7x lower energy per classification compared to conventional RF, SVM_RBF , MLP, and CNN, respectively. FoG is ~6.5x less energy efficient than SVM_LR, but achieves 18% higher accuracy on average across all considered datasets.