 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuppeteer: A Random Forest-based Manager for Hardware Prefetchers across the Memory Hierarchy
Jan 28, 2022
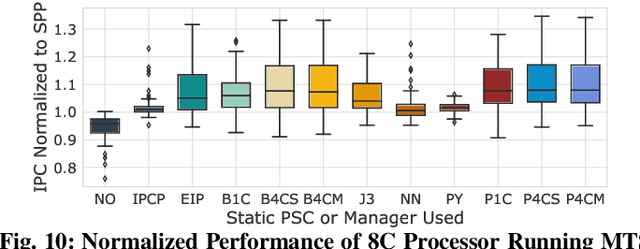


Over the years, processor throughput has steadily increased. However, the memory throughput has not increased at the same rate, which has led to the memory wall problem in turn increasing the gap between effective and theoretical peak processor performance. To cope with this, there has been an abundance of work in the area of data/instruction prefetcher designs. Broadly, prefetchers predict future data/instruction address accesses and proactively fetch data/instructions in the memory hierarchy with the goal of lowering data/instruction access latency. To this end, one or more prefetchers are deployed at each level of the memory hierarchy, but typically, each prefetcher gets designed in isolation without comprehensively accounting for other prefetchers in the system. As a result, individual prefetchers do not always complement each other, and that leads to lower average performance gains and/or many negative outliers. In this work, we propose Puppeteer, which is a hardware prefetcher manager that uses a suite of random forest regressors to determine at runtime which prefetcher should be ON at each level in the memory hierarchy, such that the prefetchers complement each other and we reduce the data/instruction access latency. Compared to a design with no prefetchers, using Puppeteer we improve IPC by 46.0% in 1 Core (1C), 25.8% in 4 Core (4C), and 11.9% in 8 Core (8C) processors on average across traces generated from SPEC2017, SPEC2006, and Cloud suites with ~10KB overhead. Moreover, we also reduce the number of negative outliers by over 89%, and the performance loss of the worst-case negative outlier from 25% to only 5% compared to the state-of-the-art.
Field of Groves: An Energy-Efficient Random Forest
Apr 10, 2017
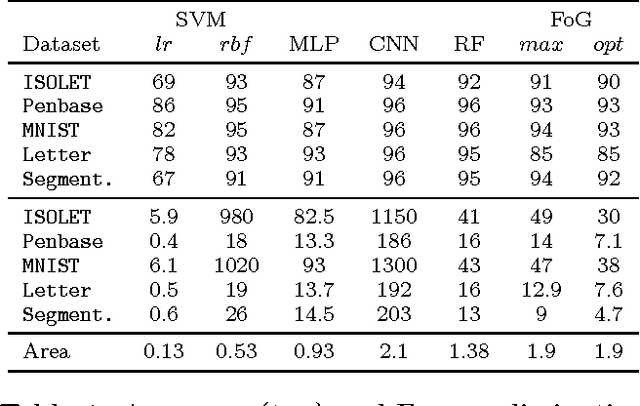
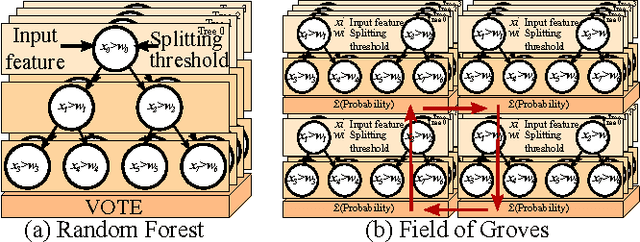
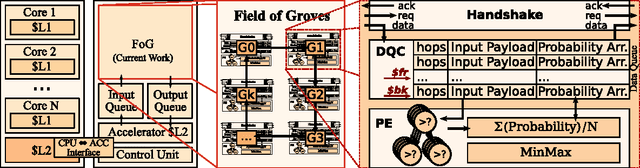
Machine Learning (ML) algorithms, like Convolutional Neural Networks (CNN), Support Vector Machines (SVM), etc. have become widespread and can achieve high statistical performance. However their accuracy decreases significantly in energy-constrained mobile and embedded systems space, where all computations need to be completed under a tight energy budget. In this work, we present a field of groves (FoG) implementation of random forests (RF) that achieves an accuracy comparable to CNNs and SVMs under tight energy budgets. Evaluation of the FoG shows that at comparable accuracy it consumes ~1.48x, ~24x, ~2.5x, and ~34.7x lower energy per classification compared to conventional RF, SVM_RBF , MLP, and CNN, respectively. FoG is ~6.5x less energy efficient than SVM_LR, but achieves 18% higher accuracy on average across all considered datasets.