 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Generation without Representation: Efficient Causal Protein Language Models Enable Zero-Shot Fitness Estimation
Feb 02, 2026Protein language models (PLMs) face a fundamental divide: masked language models (MLMs) excel at fitness prediction while causal models enable generation, forcing practitioners to maintain separate architectures. We introduce \textbf{Proust}, a 309M-parameter causal PLM that bridges this gap through architectural innovations adapted from recent LLM research, including grouped-query attention with shared K/V projections, cross-layer value residuals, and depthwise causal convolutions. Trained on 33B tokens in 40 B200 GPU-hours, Proust achieves Spearman $ρ= 0.390$ on ProteinGym substitutions, competitive with MLMs requiring 50--200$\times$ the compute. On indels, Proust sets a new state-of-the-art, outperforming models up to 20$\times$ larger. On EVEREST viral fitness benchmarks, it approaches structure-aware methods using sequence alone. These powerful representations position Proust in a sweet spot as it also retains native generative capabilities that MLMs lack by design. Interpretability analysis reveals that per-position entropy variance predicts, to an extent, when retrieval augmentation helps and hurts. Such insights can grow in both quantity and quality at scale and inform capabilities such as test-time scaling. Code and weights are available at https://github.com/Furkan9015/proust-inference
Puppeteer: A Random Forest-based Manager for Hardware Prefetchers across the Memory Hierarchy
Jan 28, 2022
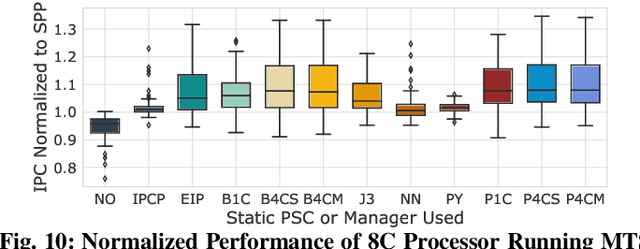


Over the years, processor throughput has steadily increased. However, the memory throughput has not increased at the same rate, which has led to the memory wall problem in turn increasing the gap between effective and theoretical peak processor performance. To cope with this, there has been an abundance of work in the area of data/instruction prefetcher designs. Broadly, prefetchers predict future data/instruction address accesses and proactively fetch data/instructions in the memory hierarchy with the goal of lowering data/instruction access latency. To this end, one or more prefetchers are deployed at each level of the memory hierarchy, but typically, each prefetcher gets designed in isolation without comprehensively accounting for other prefetchers in the system. As a result, individual prefetchers do not always complement each other, and that leads to lower average performance gains and/or many negative outliers. In this work, we propose Puppeteer, which is a hardware prefetcher manager that uses a suite of random forest regressors to determine at runtime which prefetcher should be ON at each level in the memory hierarchy, such that the prefetchers complement each other and we reduce the data/instruction access latency. Compared to a design with no prefetchers, using Puppeteer we improve IPC by 46.0% in 1 Core (1C), 25.8% in 4 Core (4C), and 11.9% in 8 Core (8C) processors on average across traces generated from SPEC2017, SPEC2006, and Cloud suites with ~10KB overhead. Moreover, we also reduce the number of negative outliers by over 89%, and the performance loss of the worst-case negative outlier from 25% to only 5% compared to the state-of-the-art.
Custom Tailored Suite of Random Forests for Prefetcher Adaptation
Aug 01, 2020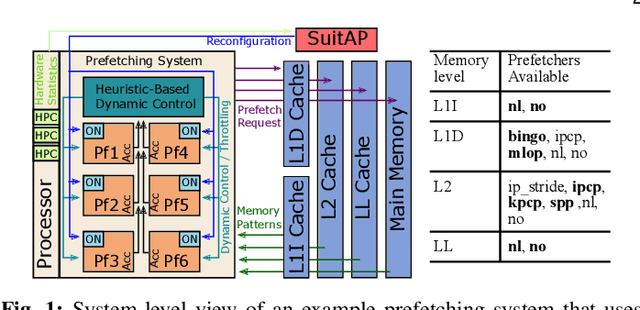

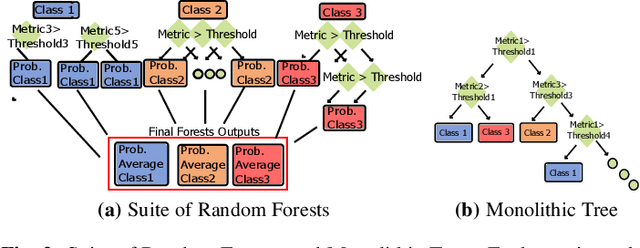
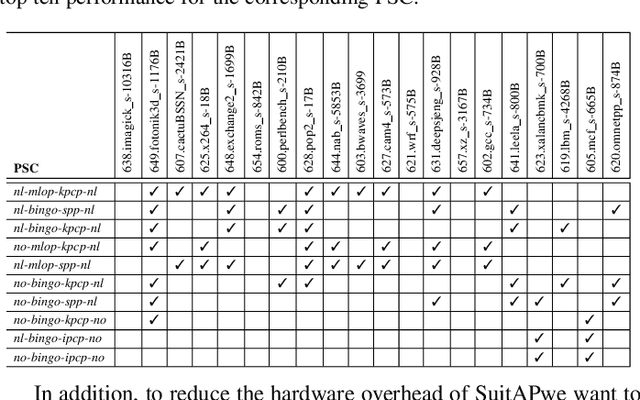
To close the gap between memory and processors, and in turn improve performance, there has been an abundance of work in the area of data/instruction prefetcher designs. Prefetchers are deployed in each level of the memory hierarchy, but typically, each prefetcher gets designed without comprehensively accounting for other prefetchers in the system. As a result, these individual prefetcher designs do not always complement each other, and that leads to low average performance gains and/or many negative outliers. In this work, we propose SuitAP (Suite of random forests for Adaptation of Prefetcher system configuration), which is a hardware prefetcher adapter that uses a suite of random forests to determine at runtime which prefetcher should be ON at each memory level, such that they complement each other. Compared to a design with no prefetchers, using SuitAP we improve IPC by 46% on average across traces generated from SPEC2017 suite with 12KB overhead. Moreover, we also reduce negative outliers using SuitAP.