 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Apr 26, 2024



Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
Photonics for Sustainable Computing
Jan 10, 2024Photonic integrated circuits are finding use in a variety of applications including optical transceivers, LIDAR, bio-sensing, photonic quantum computing, and Machine Learning (ML). In particular, with the exponentially increasing sizes of ML models, photonics-based accelerators are getting special attention as a sustainable solution because they can perform ML inferences with multiple orders of magnitude higher energy efficiency than CMOS-based accelerators. However, recent studies have shown that hardware manufacturing and infrastructure contribute significantly to the carbon footprint of computing devices, even surpassing the emissions generated during their use. For example, the manufacturing process accounts for 74% of the total carbon emissions from Apple in 2019. This prompts us to ask -- if we consider both the embodied (manufacturing) and operational carbon cost of photonics, is it indeed a viable avenue for a sustainable future? So, in this paper, we build a carbon footprint model for photonic chips and investigate the sustainability of photonics-based accelerators by conducting a case study on ADEPT, a photonics-based accelerator for deep neural network inference. Our analysis shows that photonics can reduce both operational and embodied carbon footprints with its high energy efficiency and at least 4$\times$ less fabrication carbon cost per unit area than 28 nm CMOS.
Accelerating DNN Training With Photonics: A Residue Number System-Based Design
Nov 29, 2023



Photonic computing is a compelling avenue for performing highly efficient matrix multiplication, a crucial operation in Deep Neural Networks (DNNs). While this method has shown great success in DNN inference, meeting the high precision demands of DNN training proves challenging due to the precision limitations imposed by costly data converters and the analog noise inherent in photonic hardware. This paper proposes Mirage, a photonic DNN training accelerator that overcomes the precision challenges in photonic hardware using the Residue Number System (RNS). RNS is a numeral system based on modular arithmetic$\unicode{x2014}$allowing us to perform high-precision operations via multiple low-precision modular operations. In this work, we present a novel micro-architecture and dataflow for an RNS-based photonic tensor core performing modular arithmetic in the analog domain. By combining RNS and photonics, Mirage provides high energy efficiency without compromising precision and can successfully train state-of-the-art DNNs achieving accuracy comparable to FP32 training. Our study shows that on average across several DNNs when compared to systolic arrays, Mirage achieves more than $23.8\times$ faster training and $32.1\times$ lower EDP in an iso-energy scenario and consumes $42.8\times$ lower power with comparable or better EDP in an iso-area scenario.
Towards Efficient Hyperdimensional Computing Using Photonics
Nov 29, 2023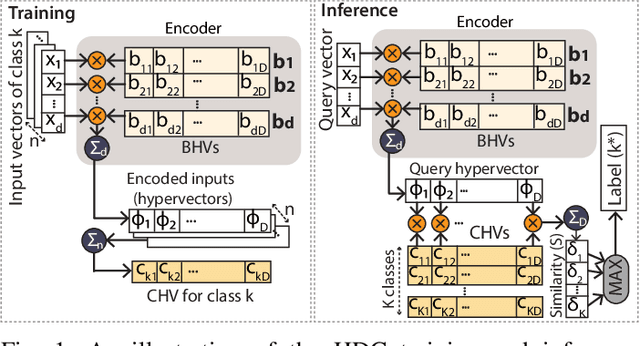
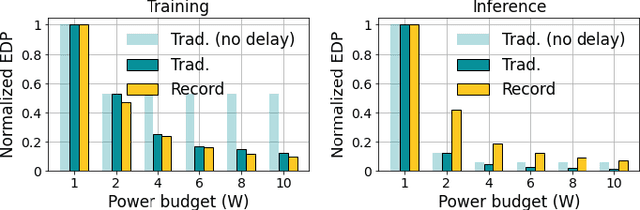
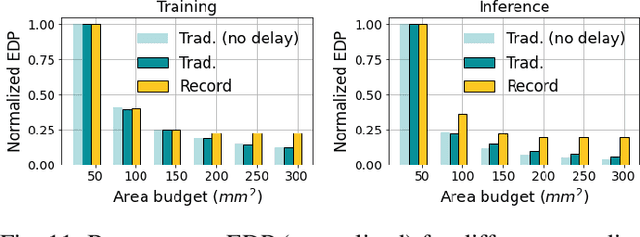
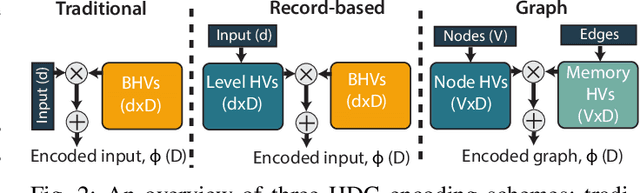
Over the past few years, silicon photonics-based computing has emerged as a promising alternative to CMOS-based computing for Deep Neural Networks (DNN). Unfortunately, the non-linear operations and the high-precision requirements of DNNs make it extremely challenging to design efficient silicon photonics-based systems for DNN inference and training. Hyperdimensional Computing (HDC) is an emerging, brain-inspired machine learning technique that enjoys several advantages over existing DNNs, including being lightweight, requiring low-precision operands, and being robust to noise introduced by the nonidealities in the hardware. For HDC, computing in-memory (CiM) approaches have been widely used, as CiM reduces the data transfer cost if the operands can fit into the memory. However, inefficient multi-bit operations, high write latency, and low endurance make CiM ill-suited for HDC. On the other hand, the existing electro-photonic DNN accelerators are inefficient for HDC because they are specifically optimized for matrix multiplication in DNNs and consume a lot of power with high-precision data converters. In this paper, we argue that photonic computing and HDC complement each other better than photonic computing and DNNs, or CiM and HDC. We propose PhotoHDC, the first-ever electro-photonic accelerator for HDC training and inference, supporting the basic, record-based, and graph encoding schemes. Evaluating with popular datasets, we show that our accelerator can achieve two to five orders of magnitude lower EDP than the state-of-the-art electro-photonic DNN accelerators for implementing HDC training and inference. PhotoHDC also achieves four orders of magnitude lower energy-delay product than CiM-based accelerators for both HDC training and inference.
A Blueprint for Precise and Fault-Tolerant Analog Neural Networks
Sep 19, 2023Analog computing has reemerged as a promising avenue for accelerating deep neural networks (DNNs) due to its potential to overcome the energy efficiency and scalability challenges posed by traditional digital architectures. However, achieving high precision and DNN accuracy using such technologies is challenging, as high-precision data converters are costly and impractical. In this paper, we address this challenge by using the residue number system (RNS). RNS allows composing high-precision operations from multiple low-precision operations, thereby eliminating the information loss caused by the limited precision of the data converters. Our study demonstrates that analog accelerators utilizing the RNS-based approach can achieve ${\geq}99\%$ of FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision whereas a conventional analog core requires more than $8$-bit precision to achieve the same accuracy in the same DNNs. The reduced precision requirements imply that using RNS can reduce the energy consumption of analog accelerators by several orders of magnitude while maintaining the same throughput and precision. Our study extends this approach to DNN training, where we can efficiently train DNNs using $7$-bit integer arithmetic while achieving accuracy comparable to FP32 precision. Lastly, we present a fault-tolerant dataflow using redundant RNS error-correcting codes to protect the computation against noise and errors inherent within an analog accelerator.
Leveraging Residue Number System for Designing High-Precision Analog Deep Neural Network Accelerators
Jun 15, 2023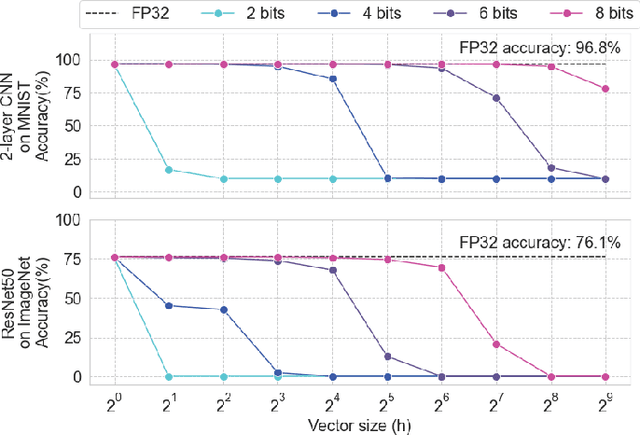
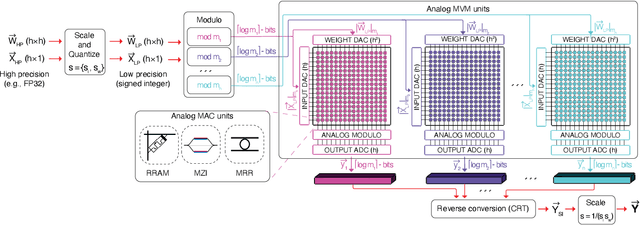
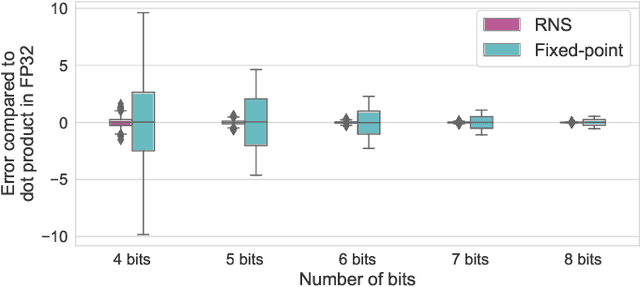
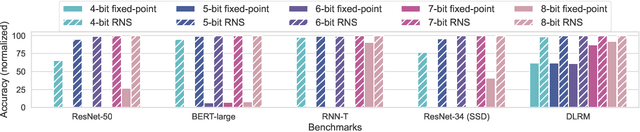
Achieving high accuracy, while maintaining good energy efficiency, in analog DNN accelerators is challenging as high-precision data converters are expensive. In this paper, we overcome this challenge by using the residue number system (RNS) to compose high-precision operations from multiple low-precision operations. This enables us to eliminate the information loss caused by the limited precision of the ADCs. Our study shows that RNS can achieve 99% FP32 accuracy for state-of-the-art DNN inference using data converters with only $6$-bit precision. We propose using redundant RNS to achieve a fault-tolerant analog accelerator. In addition, we show that RNS can reduce the energy consumption of the data converters within an analog accelerator by several orders of magnitude compared to a regular fixed-point approach.
Puppeteer: A Random Forest-based Manager for Hardware Prefetchers across the Memory Hierarchy
Jan 28, 2022
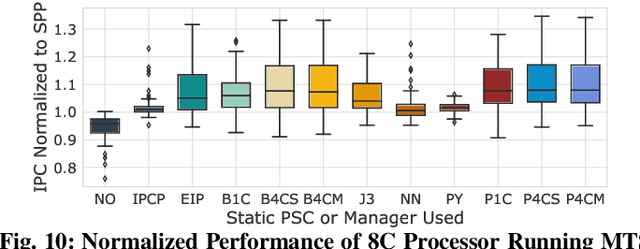


Over the years, processor throughput has steadily increased. However, the memory throughput has not increased at the same rate, which has led to the memory wall problem in turn increasing the gap between effective and theoretical peak processor performance. To cope with this, there has been an abundance of work in the area of data/instruction prefetcher designs. Broadly, prefetchers predict future data/instruction address accesses and proactively fetch data/instructions in the memory hierarchy with the goal of lowering data/instruction access latency. To this end, one or more prefetchers are deployed at each level of the memory hierarchy, but typically, each prefetcher gets designed in isolation without comprehensively accounting for other prefetchers in the system. As a result, individual prefetchers do not always complement each other, and that leads to lower average performance gains and/or many negative outliers. In this work, we propose Puppeteer, which is a hardware prefetcher manager that uses a suite of random forest regressors to determine at runtime which prefetcher should be ON at each level in the memory hierarchy, such that the prefetchers complement each other and we reduce the data/instruction access latency. Compared to a design with no prefetchers, using Puppeteer we improve IPC by 46.0% in 1 Core (1C), 25.8% in 4 Core (4C), and 11.9% in 8 Core (8C) processors on average across traces generated from SPEC2017, SPEC2006, and Cloud suites with ~10KB overhead. Moreover, we also reduce the number of negative outliers by over 89%, and the performance loss of the worst-case negative outlier from 25% to only 5% compared to the state-of-the-art.
Custom Tailored Suite of Random Forests for Prefetcher Adaptation
Aug 01, 2020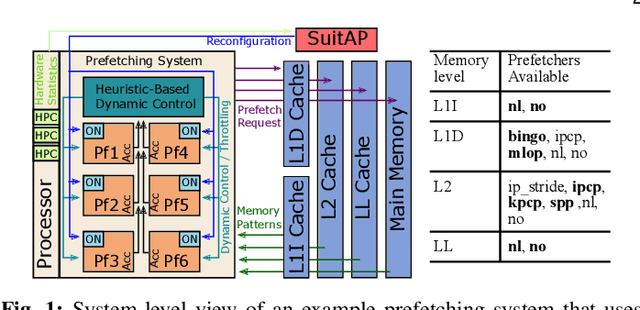

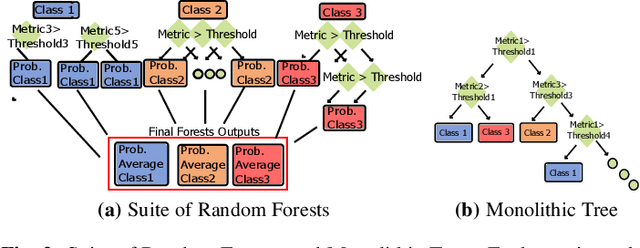
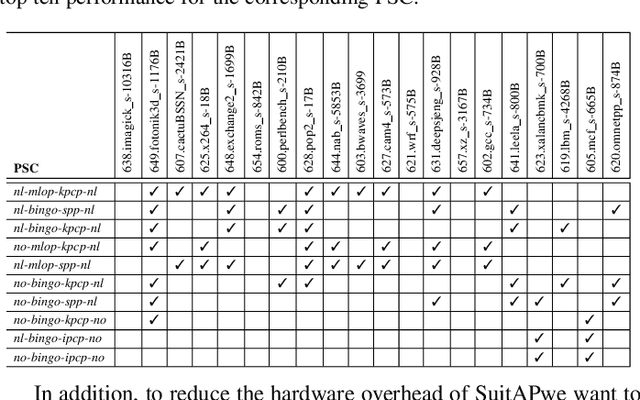
To close the gap between memory and processors, and in turn improve performance, there has been an abundance of work in the area of data/instruction prefetcher designs. Prefetchers are deployed in each level of the memory hierarchy, but typically, each prefetcher gets designed without comprehensively accounting for other prefetchers in the system. As a result, these individual prefetcher designs do not always complement each other, and that leads to low average performance gains and/or many negative outliers. In this work, we propose SuitAP (Suite of random forests for Adaptation of Prefetcher system configuration), which is a hardware prefetcher adapter that uses a suite of random forests to determine at runtime which prefetcher should be ON at each memory level, such that they complement each other. Compared to a design with no prefetchers, using SuitAP we improve IPC by 46% on average across traces generated from SPEC2017 suite with 12KB overhead. Moreover, we also reduce negative outliers using SuitAP.
CUDA optimized Neural Network predicts blood glucose control from quantified joint mobility and anthropometrics
Aug 19, 2019
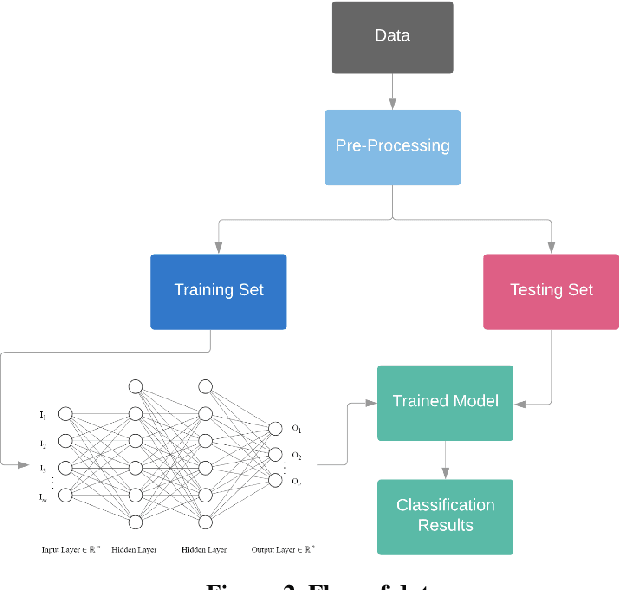
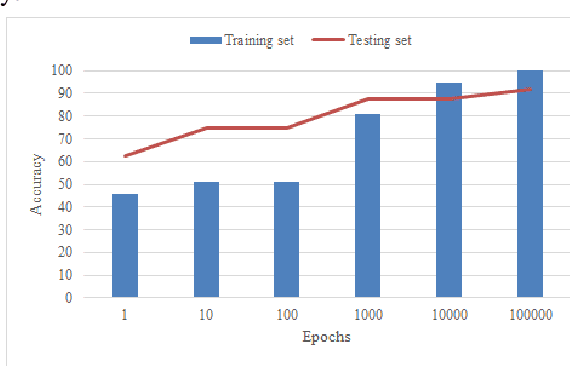

Neural network training entails heavy computation with obvious bottlenecks. The Compute Unified Device Architecture (CUDA) programming model allows us to accelerate computation by passing the processing workload from the CPU to the graphics processing unit (GPU). In this paper, we leveraged the power of Nvidia GPUs to parallelize all of the computation involved in training, to accelerate a backpropagation feed-forward neural network with one hidden layer using CUDA and C++. This optimized neural network was tasked with predicting the level of glycated hemoglobin (HbA1c) from non-invasive markers. The rate of increase in the prevalence of Diabetes Mellitus has resulted in an urgent need for early detection and accurate diagnosis. However, due to the invasiveness and limitations of conventional tests, alternate means are being considered. Limited Joint Mobility (LJM) has been reported as an indicator for poor glycemic control. LJM of the fingers is quantified and its link to HbA1c is investigated along with other potential non-invasive markers of HbA1c. We collected readings of 33 potential markers from 120 participants at a clinic in south Trinidad. Our neural network achieved 95.65% accuracy on the training and 86.67% accuracy on the testing set for male participants and 97.73% and 66.67% accuracy on the training and testing sets for female participants. Using 960 CUDA cores from a Nvidia GeForce GTX 660, our parallelized neural network was trained 50 times faster on both subsets, than its corresponding CPU implementation on an Intel Core (TM) i7-3630QM 2.40 GHz CPU.
The efficacy of various machine learning models for multi-class classification of RNA-seq expression data
Aug 19, 2019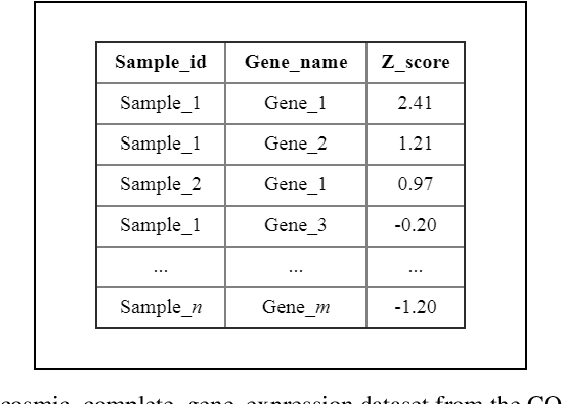


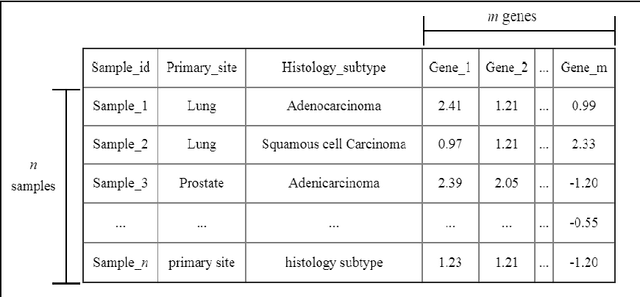
Late diagnosis and high costs are key factors that negatively impact the care of cancer patients worldwide. Although the availability of biological markers for the diagnosis of cancer type is increasing, costs and reliability of tests currently present a barrier to the adoption of their routine use. There is a pressing need for accurate methods that enable early diagnosis and cover a broad range of cancers. The use of machine learning and RNA-seq expression analysis has shown promise in the classification of cancer type. However, research is inconclusive about which type of machine learning models are optimal. The suitability of five algorithms were assessed for the classification of 17 different cancer types. Each algorithm was fine-tuned and trained on the full array of 18,015 genes per sample, for 4,221 samples (75 % of the dataset). They were then tested with 1,408 samples (25 % of the dataset) for which cancer types were withheld to determine the accuracy of prediction. The results show that ensemble algorithms achieve 100% accuracy in the classification of 14 out of 17 types of cancer. The clustering and classification models, while faster than the ensembles, performed poorly due to the high level of noise in the dataset. When the features were reduced to a list of 20 genes, the ensemble algorithms maintained an accuracy above 95% as opposed to the clustering and classification models.