 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Information from Scientific Literature via Visual Table Question Answering Models
Aug 26, 2025



This study explores three approaches to processing table data in scientific papers to enhance extractive question answering and develop a software tool for the systematic review process. The methods evaluated include: (1) Optical Character Recognition (OCR) for extracting information from documents, (2) Pre-trained models for document visual question answering, and (3) Table detection and structure recognition to extract and merge key information from tables with textual content to answer extractive questions. In exploratory experiments, we augmented ten sample test documents containing tables and relevant content against RF- EMF-related scientific papers with seven predefined extractive question-answer pairs. The results indicate that approaches preserving table structure outperform the others, particularly in representing and organizing table content. Accurately recognizing specific notations and symbols within the documents emerged as a critical factor for improved results. Our study concludes that preserving the structural integrity of tables is essential for enhancing the accuracy and reliability of extractive question answering in scientific documents.
* Accepted at ACM International Conference on Research in Adaptive and Convergent Systems, November 5-8, 2024, Pompei, Italy
LoL-PIM: Long-Context LLM Decoding with Scalable DRAM-PIM System
Dec 28, 2024



The expansion of large language models (LLMs) with hundreds of billions of parameters presents significant challenges to computational resources, particularly data movement and memory bandwidth. Long-context LLMs, which process sequences of tens of thousands of tokens, further increase the demand on the memory system as the complexity in attention layers and key-value cache sizes is proportional to the context length. Processing-in-Memory (PIM) maximizes memory bandwidth by moving compute to the data and can address the memory bandwidth challenges; however, PIM is not necessarily scalable to accelerate long-context LLM because of limited per-module memory capacity and the inflexibility of fixed-functional unit PIM architecture and static memory management. In this work, we propose LoL-PIM which is a multi-node PIM architecture that accelerates long context LLM through hardware-software co-design. In particular, we propose how pipeline parallelism can be exploited across a multi-PIM module while a direct PIM access (DPA) controller (or DMA for PIM) is proposed that enables dynamic PIM memory management and results in efficient PIM utilization across a diverse range of context length. We developed an MLIR-based compiler for LoL-PIM extending a commercial PIM-based compiler where the software modifications were implemented and evaluated, while the hardware changes were modeled in the simulator. Our evaluations demonstrate that LoL-PIM significantly improves throughput and reduces latency for long-context LLM inference, outperforming both multi-GPU and GPU-PIM systems (up to 8.54x and 16.0x speedup, respectively), thereby enabling more efficient deployment of LLMs in real-world applications.
NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Apr 26, 2024



Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
Hera: A Heterogeneity-Aware Multi-Tenant Inference Server for Personalized Recommendations
Feb 23, 2023



While providing low latency is a fundamental requirement in deploying recommendation services, achieving high resource utility is also crucial in cost-effectively maintaining the datacenter. Co-locating multiple workers of a model is an effective way to maximize query-level parallelism and server throughput, but the interference caused by concurrent workers at shared resources can prevent server queries from meeting its SLA. Hera utilizes the heterogeneous memory requirement of multi-tenant recommendation models to intelligently determine a productive set of co-located models and its resource allocation, providing fast response time while achieving high throughput. We show that Hera achieves an average 37.3% improvement in effective machine utilization, enabling 26% reduction in required servers, significantly improving upon the baseline recommedation inference server.
Answer Fast: Accelerating BERT on the Tensor Streaming Processor
Jun 22, 2022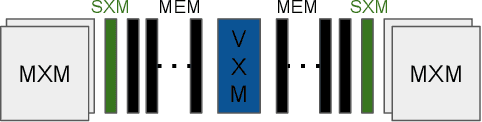
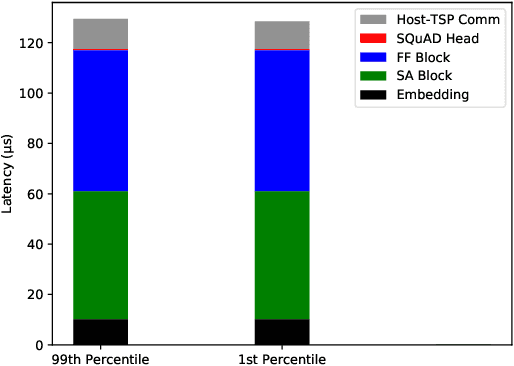
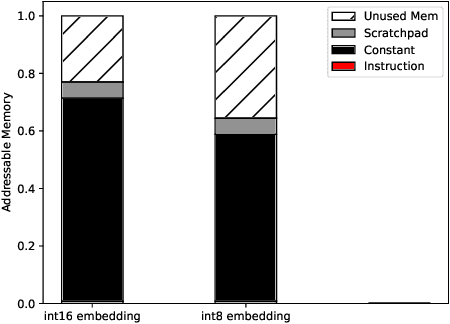

Transformers have become a predominant machine learning workload, they are not only the de-facto standard for natural language processing tasks, but they are also being deployed in other domains such as vision and speech recognition. Many of the transformer-based applications are real-time systems such as machine translation and web search. These real time systems often come with strict end-to-end inference latency requirements. Unfortunately, while the majority of the transformer computation comes from matrix multiplications, transformers also include several non-linear components that tend to become the bottleneck during an inference. In this work, we accelerate the inference of BERT models on the tensor streaming processor. By carefully fusing all the nonlinear components with the matrix multiplication components, we are able to efficiently utilize the on-chip matrix multiplication units resulting in a deterministic tail latency of 130 $\mu$s for a batch-1 inference through BERT-base, which is 6X faster than the current state-of-the-art.
NeuMMU: Architectural Support for Efficient Address Translations in Neural Processing Units
Nov 15, 2019
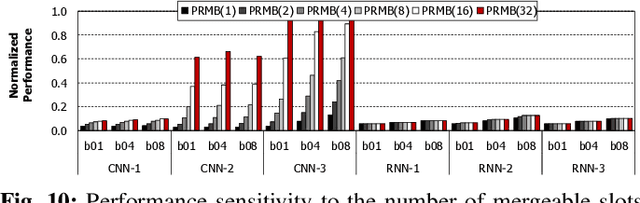
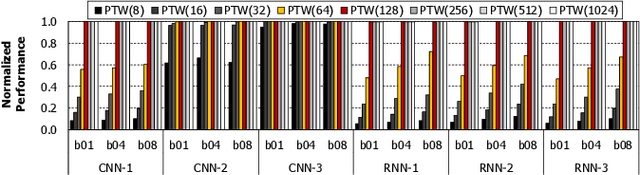
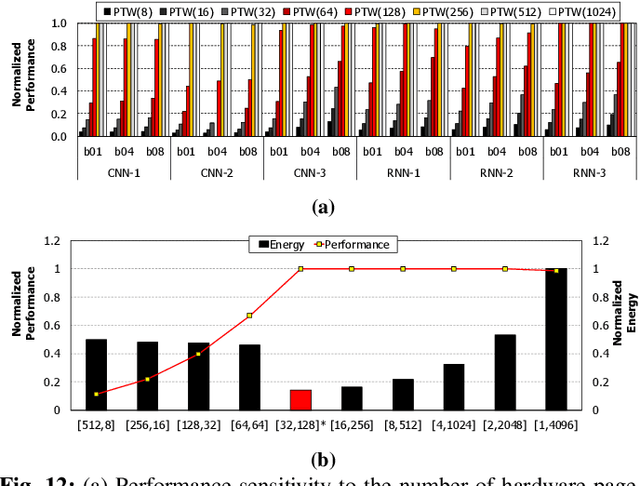
To satisfy the compute and memory demands of deep neural networks, neural processing units (NPUs) are widely being utilized for accelerating deep learning algorithms. Similar to how GPUs have evolved from a slave device into a mainstream processor architecture, it is likely that NPUs will become first class citizens in this fast-evolving heterogeneous architecture space. This paper makes a case for enabling address translation in NPUs to decouple the virtual and physical memory address space. Through a careful data-driven application characterization study, we root-cause several limitations of prior GPU-centric address translation schemes and propose a memory management unit (MMU) that is tailored for NPUs. Compared to an oracular MMU design point, our proposal incurs only an average 0.06% performance overhead.
LYTNet: A Convolutional Neural Network for Real-Time Pedestrian Traffic Lights and Zebra Crossing Recognition for the Visually Impaired
Jul 23, 2019


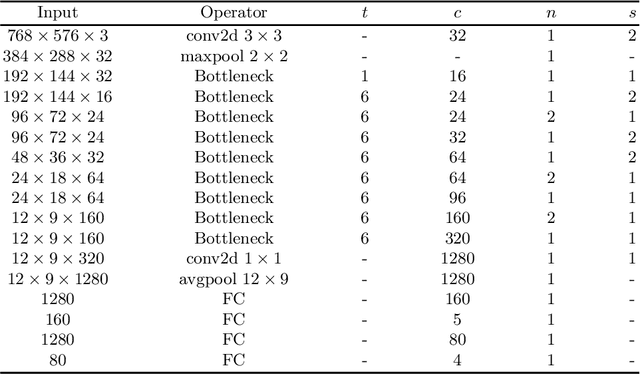
Currently, the visually impaired rely on either a sighted human, guide dog, or white cane to safely navigate. However, the training of guide dogs is extremely expensive, and canes cannot provide essential information regarding the color of traffic lights and direction of crosswalks. In this paper, we propose a deep learning based solution that provides information regarding the traffic light mode and the position of the zebra crossing. Previous solutions that utilize machine learning only provide one piece of information and are mostly binary: only detecting red or green lights. The proposed convolutional neural network, LYTNet, is designed for comprehensiveness, accuracy, and computational efficiency. LYTNet delivers both of the two most important pieces of information for the visually impaired to cross the road. We provide five classes of pedestrian traffic lights rather than the commonly seen three or four, and a direction vector representing the midline of the zebra crossing that is converted from the 2D image plane to real-world positions. We created our own dataset of pedestrian traffic lights containing over 5000 photos taken at hundreds of intersections in Shanghai. The experiments carried out achieve a classification accuracy of 94%, average angle error of 6.35 degrees, with a frame rate of 20 frames per second when testing the network on an iPhone 7 with additional post-processing steps.