 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoicePrompter: Robust Zero-Shot Voice Conversion with Voice Prompt and Conditional Flow Matching
Jan 29, 2025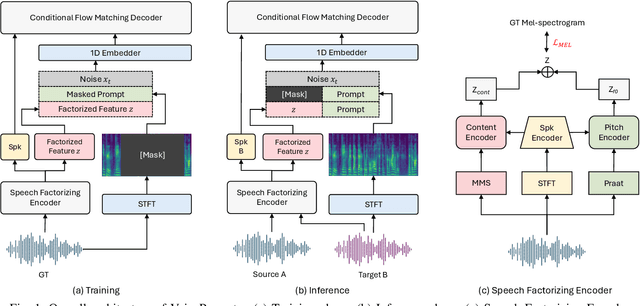
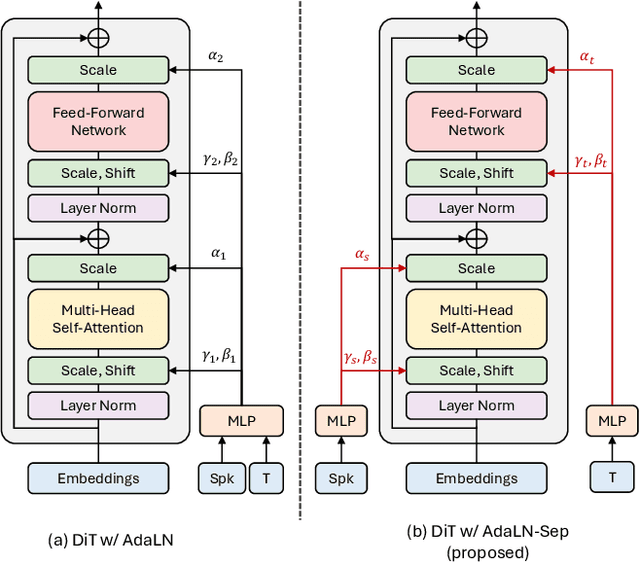
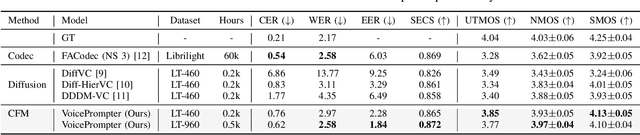
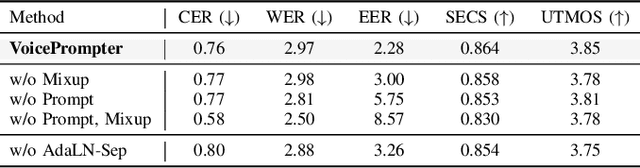
Despite remarkable advancements in recent voice conversion (VC) systems, enhancing speaker similarity in zero-shot scenarios remains challenging. This challenge arises from the difficulty of generalizing and adapting speaker characteristics in speech within zero-shot environments, which is further complicated by mismatch between the training and inference processes. To address these challenges, we propose VoicePrompter, a robust zero-shot VC model that leverages in-context learning with voice prompts. VoicePrompter is composed of (1) a factorization method that disentangles speech components and (2) a DiT-based conditional flow matching (CFM) decoder that conditions on these factorized features and voice prompts. Additionally, (3) latent mixup is used to enhance in-context learning by combining various speaker features. This approach improves speaker similarity and naturalness in zero-shot VC by applying mixup to latent representations. Experimental results demonstrate that VoicePrompter outperforms existing zero-shot VC systems in terms of speaker similarity, speech intelligibility, and audio quality. Our demo is available at \url{https://hayeong0.github.io/VoicePrompter-demo/}.
LoL-PIM: Long-Context LLM Decoding with Scalable DRAM-PIM System
Dec 28, 2024



The expansion of large language models (LLMs) with hundreds of billions of parameters presents significant challenges to computational resources, particularly data movement and memory bandwidth. Long-context LLMs, which process sequences of tens of thousands of tokens, further increase the demand on the memory system as the complexity in attention layers and key-value cache sizes is proportional to the context length. Processing-in-Memory (PIM) maximizes memory bandwidth by moving compute to the data and can address the memory bandwidth challenges; however, PIM is not necessarily scalable to accelerate long-context LLM because of limited per-module memory capacity and the inflexibility of fixed-functional unit PIM architecture and static memory management. In this work, we propose LoL-PIM which is a multi-node PIM architecture that accelerates long context LLM through hardware-software co-design. In particular, we propose how pipeline parallelism can be exploited across a multi-PIM module while a direct PIM access (DPA) controller (or DMA for PIM) is proposed that enables dynamic PIM memory management and results in efficient PIM utilization across a diverse range of context length. We developed an MLIR-based compiler for LoL-PIM extending a commercial PIM-based compiler where the software modifications were implemented and evaluated, while the hardware changes were modeled in the simulator. Our evaluations demonstrate that LoL-PIM significantly improves throughput and reduces latency for long-context LLM inference, outperforming both multi-GPU and GPU-PIM systems (up to 8.54x and 16.0x speedup, respectively), thereby enabling more efficient deployment of LLMs in real-world applications.