 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Apr 26, 2024



Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
Achieving on-Mobile Real-Time Super-Resolution with Neural Architecture and Pruning Search
Aug 18, 2021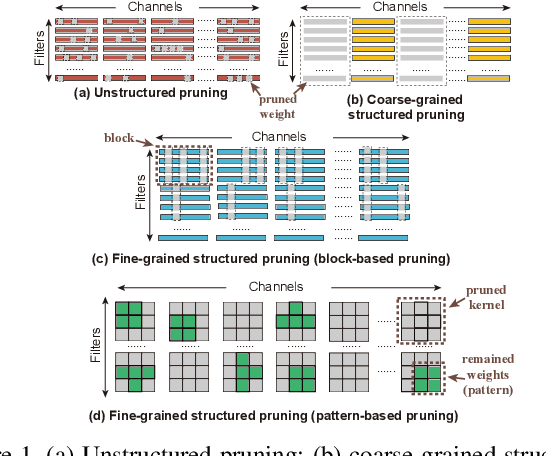
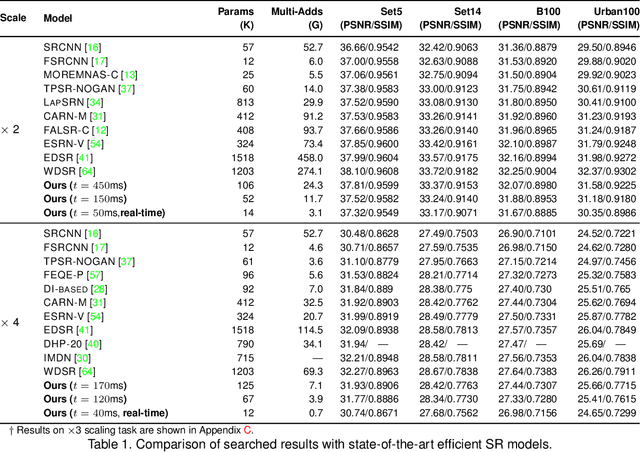
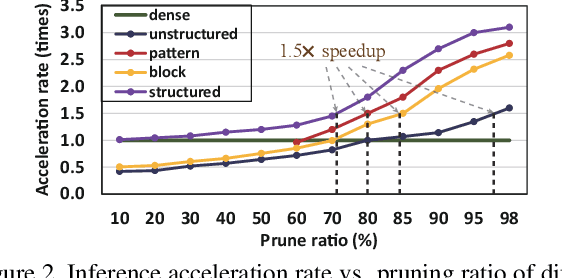
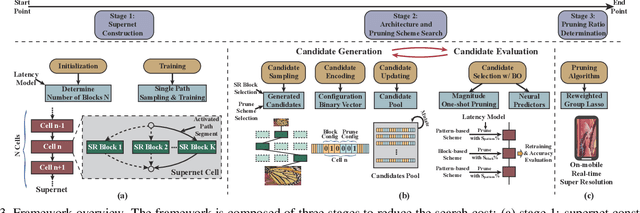
Though recent years have witnessed remarkable progress in single image super-resolution (SISR) tasks with the prosperous development of deep neural networks (DNNs), the deep learning methods are confronted with the computation and memory consumption issues in practice, especially for resource-limited platforms such as mobile devices. To overcome the challenge and facilitate the real-time deployment of SISR tasks on mobile, we combine neural architecture search with pruning search and propose an automatic search framework that derives sparse super-resolution (SR) models with high image quality while satisfying the real-time inference requirement. To decrease the search cost, we leverage the weight sharing strategy by introducing a supernet and decouple the search problem into three stages, including supernet construction, compiler-aware architecture and pruning search, and compiler-aware pruning ratio search. With the proposed framework, we are the first to achieve real-time SR inference (with only tens of milliseconds per frame) for implementing 720p resolution with competitive image quality (in terms of PSNR and SSIM) on mobile platforms (Samsung Galaxy S20).