 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should a Robot Think? Resource-Aware Reasoning via Reinforcement Learning for Embodied Robotic Decision-Making
Mar 17, 2026Embodied robotic systems increasingly rely on large language model (LLM)-based agents to support high-level reasoning, planning, and decision-making during interactions with the environment. However, invoking LLM reasoning introduces substantial computational latency and resource overhead, which can interrupt action execution and reduce system reliability. Excessive reasoning may delay actions, while insufficient reasoning often leads to incorrect decisions and task failures. This raises a fundamental question for embodied agents: when should the agent reason, and when should it act? In this work, we propose RARRL (Resource-Aware Reasoning via Reinforcement Learning), a hierarchical framework for resource-aware orchestration of embodied agents. Rather than learning low-level control policies, RARRL learns a high-level orchestration policy that operates at the agent's decision-making layer. This policy enables the agent to adaptively determine whether to invoke reasoning, which reasoning role to employ, and how much computational budget to allocate based on current observations, execution history, and remaining resources. Extensive experiments, including evaluations with empirical latency profiles derived from the ALFRED benchmark, show that RARRL consistently improves task success rates while reducing execution latency and enhancing robustness compared with fixed or heuristic reasoning strategies. These results demonstrate that adaptive reasoning control is essential for building reliable and efficient embodied robotic agents.
FlashMem: Supporting Modern DNN Workloads on Mobile with GPU Memory Hierarchy Optimizations
Feb 17, 2026The increasing size and complexity of modern deep neural networks (DNNs) pose significant challenges for on-device inference on mobile GPUs, with limited memory and computational resources. Existing DNN acceleration frameworks primarily deploy a weight preloading strategy, where all model parameters are loaded into memory before execution on mobile GPUs. We posit that this approach is not adequate for modern DNN workloads that comprise very large model(s) and possibly execution of several distinct models in succession. In this work, we introduce FlashMem, a memory streaming framework designed to efficiently execute large-scale modern DNNs and multi-DNN workloads while minimizing memory consumption and reducing inference latency. Instead of fully preloading weights, FlashMem statically determines model loading schedules and dynamically streams them on demand, leveraging 2.5D texture memory to minimize data transformations and improve execution efficiency. Experimental results on 11 models demonstrate that FlashMem achieves 2.0x to 8.4x memory reduction and 1.7x to 75.0x speedup compared to existing frameworks, enabling efficient execution of large-scale models and multi-DNN support on resource-constrained mobile GPUs.
WISE-Flow: Workflow-Induced Structured Experience for Self-Evolving Conversational Service Agents
Jan 13, 2026Large language model (LLM)-based agents are widely deployed in user-facing services but remain error-prone in new tasks, tend to repeat the same failure patterns, and show substantial run-to-run variability. Fixing failures via environment-specific training or manual patching is costly and hard to scale. To enable self-evolving agents in user-facing service environments, we propose WISE-Flow, a workflow-centric framework that converts historical service interactions into reusable procedural experience by inducing workflows with prerequisite-augmented action blocks. At deployment, WISE-Flow aligns the agent's execution trajectory to retrieved workflows and performs prerequisite-aware feasibility reasoning to achieve state-grounded next actions. Experiments on ToolSandbox and $τ^2$-bench show consistent improvement across base models.
From Bits to Chips: An LLM-based Hardware-Aware Quantization Agent for Streamlined Deployment of LLMs
Jan 07, 2026Deploying models, especially large language models (LLMs), is becoming increasingly attractive to a broader user base, including those without specialized expertise. However, due to the resource constraints of certain hardware, maintaining high accuracy with larger model while meeting the hardware requirements remains a significant challenge. Model quantization technique helps mitigate memory and compute bottlenecks, yet the added complexities of tuning and deploying quantized models further exacerbates these challenges, making the process unfriendly to most of the users. We introduce the Hardware-Aware Quantization Agent (HAQA), an automated framework that leverages LLMs to streamline the entire quantization and deployment process by enabling efficient hyperparameter tuning and hardware configuration, thereby simultaneously improving deployment quality and ease of use for a broad range of users. Our results demonstrate up to a 2.3x speedup in inference, along with increased throughput and improved accuracy compared to unoptimized models on Llama. Additionally, HAQA is designed to implement adaptive quantization strategies across diverse hardware platforms, as it automatically finds optimal settings even when they appear counterintuitive, thereby reducing extensive manual effort and demonstrating superior adaptability. Code will be released.
OUSAC: Optimized Guidance Scheduling with Adaptive Caching for DiT Acceleration
Dec 16, 2025



Diffusion models have emerged as the dominant paradigm for high-quality image generation, yet their computational expense remains substantial due to iterative denoising. Classifier-Free Guidance (CFG) significantly enhances generation quality and controllability but doubles the computation by requiring both conditional and unconditional forward passes at every timestep. We present OUSAC (Optimized gUidance Scheduling with Adaptive Caching), a framework that accelerates diffusion transformers (DiT) through systematic optimization. Our key insight is that variable guidance scales enable sparse computation: adjusting scales at certain timesteps can compensate for skipping CFG at others, enabling both fewer total sampling steps and fewer CFG steps while maintaining quality. However, variable guidance patterns introduce denoising deviations that undermine standard caching methods, which assume constant CFG scales across steps. Moreover, different transformer blocks are affected at different levels under dynamic conditions. This paper develops a two-stage approach leveraging these insights. Stage-1 employs evolutionary algorithms to jointly optimize which timesteps to skip and what guidance scale to use, eliminating up to 82% of unconditional passes. Stage-2 introduces adaptive rank allocation that tailors calibration efforts per transformer block, maintaining caching effectiveness under variable guidance. Experiments demonstrate that OUSAC significantly outperforms state-of-the-art acceleration methods, achieving 53% computational savings with 15% quality improvement on DiT-XL/2 (ImageNet 512x512), 60% savings with 16.1% improvement on PixArt-alpha (MSCOCO), and 5x speedup on FLUX while improving CLIP Score over the 50-step baseline.
TSLA: A Task-Specific Learning Adaptation for Semantic Segmentation on Autonomous Vehicles Platform
Aug 17, 2025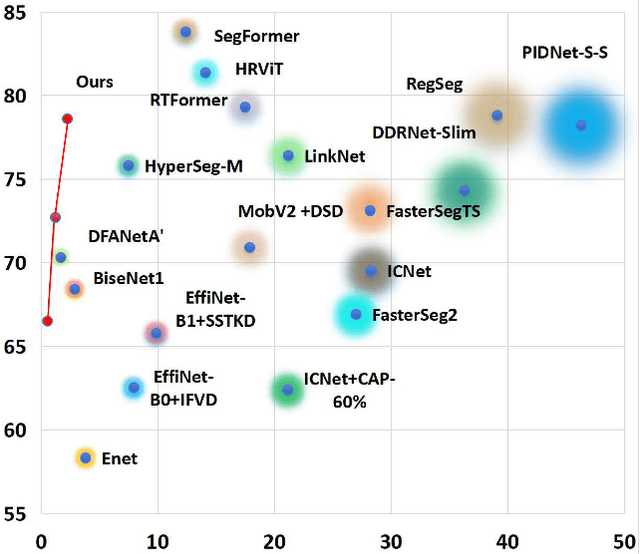
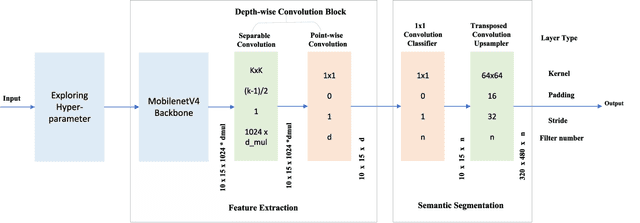
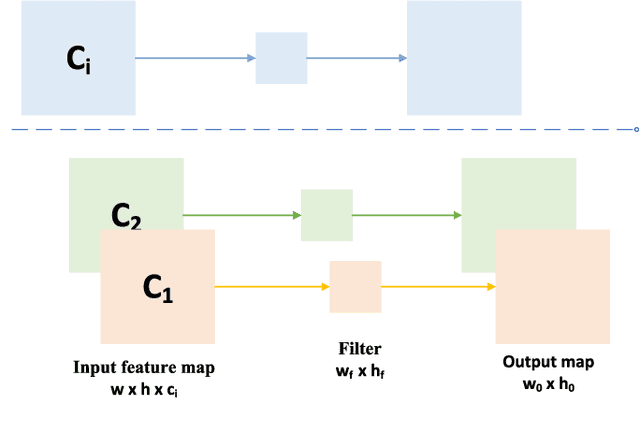
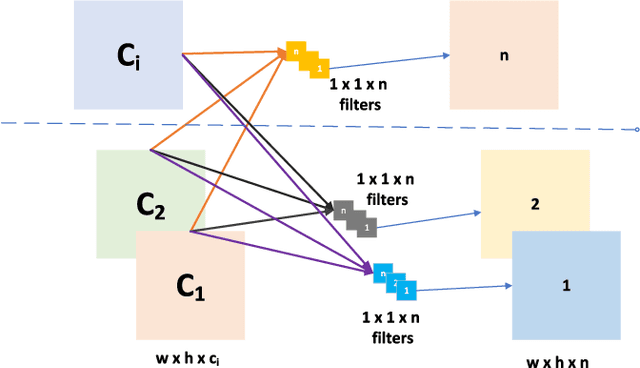
Autonomous driving platforms encounter diverse driving scenarios, each with varying hardware resources and precision requirements. Given the computational limitations of embedded devices, it is crucial to consider computing costs when deploying on target platforms like the NVIDIA\textsuperscript{\textregistered} DRIVE PX 2. Our objective is to customize the semantic segmentation network according to the computing power and specific scenarios of autonomous driving hardware. We implement dynamic adaptability through a three-tier control mechanism -- width multiplier, classifier depth, and classifier kernel -- allowing fine-grained control over model components based on hardware constraints and task requirements. This adaptability facilitates broad model scaling, targeted refinement of the final layers, and scenario-specific optimization of kernel sizes, leading to improved resource allocation and performance. Additionally, we leverage Bayesian Optimization with surrogate modeling to efficiently explore hyperparameter spaces under tight computational budgets. Our approach addresses scenario-specific and task-specific requirements through automatic parameter search, accommodating the unique computational complexity and accuracy needs of autonomous driving. It scales its Multiply-Accumulate Operations (MACs) for Task-Specific Learning Adaptation (TSLA), resulting in alternative configurations tailored to diverse self-driving tasks. These TSLA customizations maximize computational capacity and model accuracy, optimizing hardware utilization.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Structured Agent Distillation for Large Language Model
May 20, 2025



Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
QuartDepth: Post-Training Quantization for Real-Time Depth Estimation on the Edge
Mar 20, 2025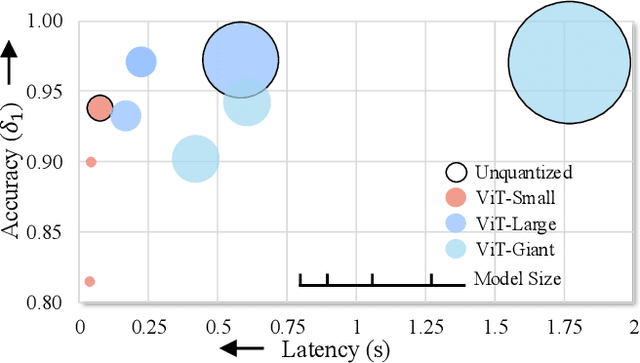
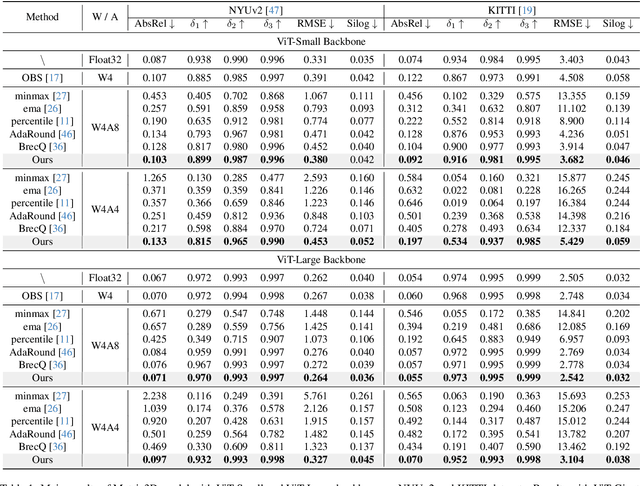
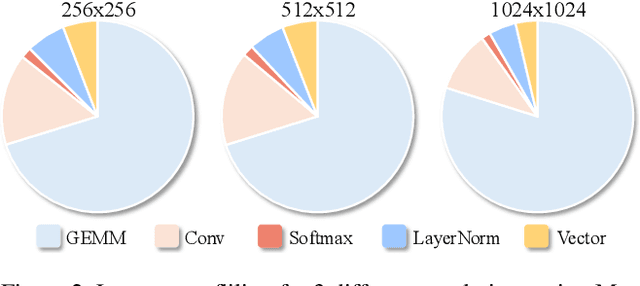
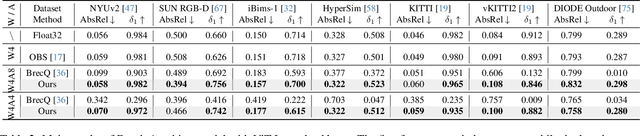
Monocular Depth Estimation (MDE) has emerged as a pivotal task in computer vision, supporting numerous real-world applications. However, deploying accurate depth estimation models on resource-limited edge devices, especially Application-Specific Integrated Circuits (ASICs), is challenging due to the high computational and memory demands. Recent advancements in foundational depth estimation deliver impressive results but further amplify the difficulty of deployment on ASICs. To address this, we propose QuartDepth which adopts post-training quantization to quantize MDE models with hardware accelerations for ASICs. Our approach involves quantizing both weights and activations to 4-bit precision, reducing the model size and computation cost. To mitigate the performance degradation, we introduce activation polishing and compensation algorithm applied before and after activation quantization, as well as a weight reconstruction method for minimizing errors in weight quantization. Furthermore, we design a flexible and programmable hardware accelerator by supporting kernel fusion and customized instruction programmability, enhancing throughput and efficiency. Experimental results demonstrate that our framework achieves competitive accuracy while enabling fast inference and higher energy efficiency on ASICs, bridging the gap between high-performance depth estimation and practical edge-device applicability. Code: https://github.com/shawnricecake/quart-depth
Learning LLM Preference over Intra-Dialogue Pairs: A Framework for Utterance-level Understandings
Mar 07, 2025

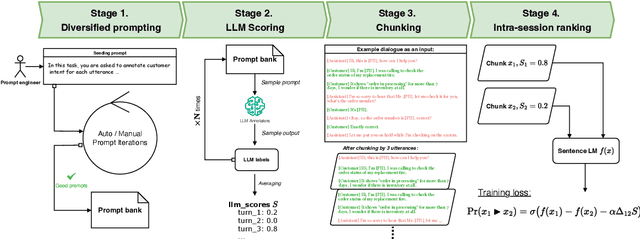

Large language models (LLMs) have demonstrated remarkable capabilities in handling complex dialogue tasks without requiring use case-specific fine-tuning. However, analyzing live dialogues in real-time necessitates low-latency processing systems, making it impractical to deploy models with billions of parameters due to latency constraints. As a result, practitioners often prefer smaller models with millions of parameters, trained on high-quality, human-annotated datasets. Yet, curating such datasets is both time-consuming and costly. Consequently, there is a growing need to combine the scalability of LLM-generated labels with the precision of human annotations, enabling fine-tuned smaller models to achieve both higher speed and accuracy comparable to larger models. In this paper, we introduce a simple yet effective framework to address this challenge. Our approach is specifically designed for per-utterance classification problems, which encompass tasks such as intent detection, dialogue state tracking, and more. To mitigate the impact of labeling errors from LLMs -- the primary source of inaccuracies in student models -- we propose a noise-reduced preference learning loss. Experimental results demonstrate that our method significantly improves accuracy across utterance-level dialogue tasks, including sentiment detection (over $2\%$), dialogue act classification (over $1.5\%$), etc.